Mastering Warehouse Data Modeling: Concepts & Production
|
0
min read

Your dashboards are loading, but nobody trusts them. Finance says revenue is off. Operations sees missing records. Analysts spend more time explaining why a metric moved than what to do about it. That's usually the moment teams realize the warehouse isn't failing because of SQL syntax or BI tooling. It's failing because the model underneath the warehouse never became a durable system.
Good warehouse data modeling turns scattered operational data into something people can query, understand, and trust. It also decides how painful change will be later. A model that looks clean in a diagram can still collapse under late-arriving data, unclear definitions, slow joins, and schema drift. A model that works in production has to survive all of those pressures at once.
Table of Contents
Why Warehouse Data Modeling is Your Analytics Foundation
When a team says “our data is messy,” the underlying issue is usually structural. Tables reflect application behavior instead of business meaning. Metrics are calculated three different ways. Historical changes are overwritten, so nobody can answer what a customer, product, or contract looked like at a prior point in time.
That's where warehouse data modeling matters. It gives analysts a stable language for the business. Instead of stitching together raw orders, customer records, invoices, and status logs every time someone needs a report, the warehouse provides durable entities, consistent joins, and agreed definitions.

Trust breaks before pipelines do
A pipeline can finish successfully and still produce bad analytics. The data may arrive on time, but the model can still hide duplication, flatten relationships incorrectly, or erase history that downstream users need for trend analysis and audit work.
The practical consequence is simple. Poor models create argument. Good models create decisions.
Practical rule: If a business user needs a data engineer to explain every dashboard join, the model is still too close to the source systems.
A solid warehouse model does three jobs at once:
Creates consistency: Customer, product, and revenue definitions stop changing from dashboard to dashboard.
Supports historical analysis: Teams can answer not just what is true now, but what was true at a specific time.
Improves maintainability: Engineers can add new sources and metrics without rewriting the entire analytics layer.
Modeling is an old discipline with modern consequences
Data warehousing didn't appear with cloud platforms. The architecture behind it goes back decades. The history of data warehouse architecture traces the discipline to the 1980s, when the core approach was developed to transform operational data into decision-support systems. That shift gave organizations a way to consolidate data from separate operational domains and make it useful for analysis.
The move from mainframe-oriented storage to cloud and hybrid warehouses changed implementation details, but it didn't remove the need for modeling. It raised the stakes. Modern warehouses have to absorb more data, more change, and more users while still preserving historical context.
That's why teams that rush straight to ingestion and dashboards often stall. Loading data is not the same as organizing it. A warehouse becomes useful only when the model matches how the business asks questions.
Choosing Your Blueprint Star, Snowflake, or Data Vault
The easiest way to explain modeling styles is to compare them to library design. One library is arranged for fast browsing. Another is organized for precise categorization. A third is built like an archive, where preserving lineage matters as much as retrieval.
Warehouse models make the same trade-offs.
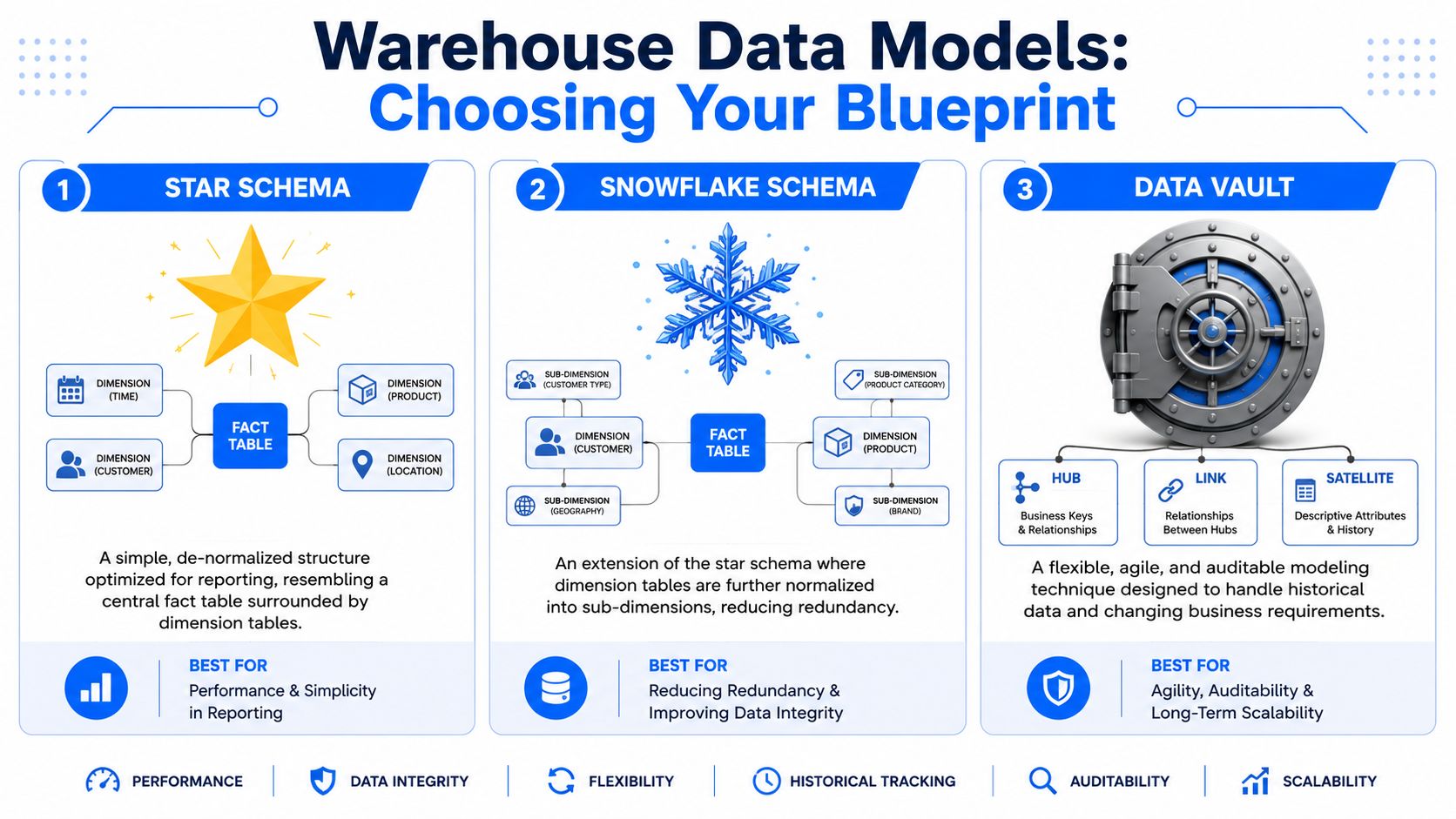
Think of the model like a library
A Star Schema is the browse-friendly library. One central fact table holds measurable events such as orders, claims, page views, or invoices. Dimension tables provide context like customer, product, region, and date. It's easy to teach, easy to query, and usually the right choice when BI is the primary workload.
A Snowflake Schema starts from the same dimensional idea but normalizes some dimensions into sub-dimensions. Product may split into brand, category, and supplier tables. Geography may split into city, region, and country. You reduce redundancy, but you add join complexity.
A Data Vault is closer to an archival system. It separates stable business keys, relationships, and descriptive history into distinct structures. According to ER/Studio's overview of warehouse modeling patterns, Star Schema dominates simplicity and speed requirements, while Data Vault is unmatched for enterprises dealing with fast-changing environments and strict regulatory demands. That same source describes Data Vault as a structure of hubs for core business entities, links for relationships, and satellites for descriptive attributes and change history.
For teams sketching options visually, a data architecture diagram reference can help clarify how these patterns differ once you move from whiteboard to implementation.
What each pattern optimizes for
Here's what usually works in practice.
Star Schema works best when analysts need fast, predictable reporting and the business can align around clear facts and dimensions.
Snowflake works best when dimension reuse and tighter normalization matter more than analyst simplicity.
Data Vault works best when source systems change frequently, lineage matters, and preserving raw history is essential.
3NF models fit best when you need operational fidelity in a core integration layer, but they usually need another presentation layer before most analysts can use them comfortably.
The trap is choosing based on ideology. A lot of teams pick Data Vault because it sounds enterprise-grade, then discover they still need dimensional marts for reporting. Others flatten everything into stars too early and regret it when upstream systems change every quarter.
Star for usability. Snowflake for tighter normalization. Data Vault for adaptability and auditability.
A practical architecture often mixes patterns. Raw and core layers may preserve source fidelity and change history. Analytics-facing marts may still present a star schema because that's what BI tools and analysts most readily use.
Later in the section, it helps to see the trade-offs in motion:
Data Modeling Approaches Compared
Criterion | Star Schema | Snowflake Schema | Data Vault |
|---|---|---|---|
Query performance | Usually strong for BI queries because joins are straightforward | Can be slower to navigate because dimensions are more normalized | Strong for lineage and ingestion patterns, but not usually the final reporting shape |
Analyst usability | High. Business users can understand it quickly | Moderate. More joins and table hopping | Lower for self-service users unless you build marts on top |
Storage efficiency | Lower than more normalized designs | Better than star in some dimensions because redundancy is reduced | Varies, often with more tables and more historical records |
Flexibility for change | Moderate | Moderate | High |
Historical tracking | Good when modeled deliberately | Good when modeled deliberately | Excellent by design |
Governance and auditability | Good, depends on discipline | Good | Strong |
Implementation complexity | Lower | Medium | High |
The decision should come from your workload, not fashion. If executives need trusted KPI dashboards every morning, start with the shape that makes those queries easy. If regulators, auditors, or integration-heavy programs drive the design, optimize for lineage and controlled change first.
Principles of High-Performance Warehouse Design
A warehouse model can use different patterns and still fail for the same reasons. The common failure points are nearly always strategic. Wrong grain. Source-centric design. Unclear naming. No plan for growth. No ownership over definitions.

Start with business processes, not source systems
The warehouse should model what the organization does. Orders. Shipments. Claims. Payments. App sessions. Support cases. If the design starts with whatever tables happened to arrive from Salesforce, SAP, or a product database, you inherit application quirks instead of business logic.
I've found one rule especially reliable: define the business event first, then decide how the warehouse will represent it. That keeps fact tables anchored to something measurable and repeatable.
A warehouse lasts longer when its core entities survive a system migration.
Design for readers, growth, and control
Analysts and BI developers are readers of the model. Data engineers are maintainers of the model. Governance teams are risk owners for the model. Good design respects all three.
Use this as an essential checklist:
Clarity over cleverness: Prefer table and column names that a new analyst can understand without opening five transformation files.
Stable grain: Every fact table needs an explicit row-level definition. If you can't state the grain in one sentence, the table isn't ready.
Scalability from day one: Assume volume, concurrency, and new subject areas will grow. Retrofitting scale is expensive.
Performance awareness: Logical elegance isn't enough. If common queries require excessive scans and joins, users will export data into spreadsheets and work around the warehouse.
Governance built in: Access rules, lineage, quality checks, and ownership can't be deferred to “later.”
Staffing matters here too. Teams often have strong pipeline engineers but no one who can bridge modeling, platform constraints, and business semantics. If you're building or reworking a warehouse program, a specialized Cloud Data Architect recruitment partner can be useful because architecture mistakes usually show up long after the hiring decision.
The model should also leave room for layered design. Raw, staging, core, analytics, and aggregate layers each solve a different problem. The mistake is collapsing them into one because it feels faster. It is faster at first. It's slower every month after that.
From Business Questions to Warehouse Schemas
The best logical models start with uncomfortable conversations. Stakeholders often ask for “a sales dashboard” or “customer 360” when they need a handful of very specific decisions supported well. Your job is to force precision before a single fact table is designed.

Turn questions into grain
Take a business question like: “What was our monthly product revenue by region?”
That question already hints at the structure:
The business process is sales or invoicing.
The measure is revenue.
The time perspective is monthly.
The slicing dimensions are product and region.
But the model shouldn't jump straight to a monthly table. The first task is to define the lowest useful grain. Is one row an order line, an invoice line, a shipment, or a daily summarized record? In most warehouses, choosing the most atomic reliable business event keeps future analysis open.
A practical sequence looks like this:
Interview for decisions, not dashboards: Ask what action follows from the metric. If nobody acts on it, don't model it first.
List the core processes: Sales, returns, subscriptions, claims, tickets, or sensor events usually become separate fact domains.
Declare the grain early: “One row per invoice line” is clear. “One row per customer transaction summary” usually isn't.
Name dimensions from business language: Customer, product, region, channel, sales rep, and date are easier to govern than source-specific labels.
Resolve metric semantics before build: Revenue, active customer, and churn are notorious for looking simple while hiding policy choices.
Field note: Most rework happens because teams skipped grain definition and discovered later that one table was mixing events, snapshots, and derived summaries.
A focused warehouse integration planning guide is useful during this stage because source onboarding affects key design choices such as business keys, late-arriving records, and conformance across systems.
Move from entities to workable schemas
After the questions are clear, map the concepts into a conceptual model first. Keep it business-oriented. Customer buys product. Order belongs to region. Invoice references contract. Entity-relationship thinking aids in this process, even if the final warehouse won't be a pure ER design.
The logical model comes next. That's where you define keys, attributes, and relationships with enough precision that engineering can implement them. Facts get foreign keys to dimensions. Dimensions get stable identifiers and descriptive attributes. Shared dimensions become conformed so the same customer or product means the same thing across marts.
A good review session at this point asks questions like:
Review question | Why it matters |
|---|---|
What is the row in this table? | Prevents mixed-grain confusion |
What business process does it represent? | Keeps models anchored to reality |
Which dimensions are reused elsewhere? | Supports conformance and consistency |
What history must be retained? | Prevents destructive overwrites |
Which metrics belong upstream versus in BI? | Reduces duplicated logic |
The physical model comes later. But if the logical model is vague, physical optimization won't save it.
Physical Implementation and Performance Tuning
A logical design can be perfectly sensible and still perform badly once it meets real query patterns. At this juncture, warehouse data modeling stops being conceptual and becomes engineering.
Logical models don't guarantee fast queries
The physical layer matters because engines don't execute diagrams. They execute storage layouts, clustering patterns, partition pruning rules, and materialized strategies. The physical modeling guidance on engine-specific design choices makes this concrete: partitioning a fact table by date can reduce scan overhead by 60–80% for queries filtering recent records, and clustering on high-cardinality dimension keys can improve join efficiency by up to 45% in star schema implementations.
That changes how you should think about implementation. A fact table with an order_date filter in nearly every dashboard should usually be physically organized to exploit that access pattern. A star schema that joins constantly on customer_id or another selective dimension key should reflect that in clustering or equivalent engine-specific design.
The practical tuning priorities are usually:
Partition on common temporal filters: If users query recent periods constantly, date-based partitioning is often the first win.
Cluster around selective joins: High-cardinality keys can improve locality for repeated joins.
Materialize with intent: Not every transformation should stay a view. Heavy reuse and expensive joins often justify table materialization.
Separate serving layers from raw ingestion: Raw tables preserve fidelity. Reporting tables should serve workload shape.
For teams working through platform-specific tuning choices, this guide to optimizing your data warehouse for maximum efficiency with modern data quality tools is a useful complement to logical design work.
Handle history deliberately
Historical tracking is one of the first places where design shortcuts become expensive. If a customer changes region, segment, or pricing tier, you need to know whether reports should reflect the current value or the value at the time of the event.
In dimensional models, Type 2 Slowly Changing Dimensions are the standard mechanism for preserving history. The basic idea is straightforward: close the old dimension row, insert a new one, and use effective dates or validity windows so facts can join to the correct historical version.
A simple pattern looks like this:
This pattern isn't glamorous, but it protects trend analysis, point-in-time reporting, and auditability. Teams that overwrite dimensions because it feels simpler usually end up rebuilding historical logic later under deadline pressure.
Keeping Your Data Model Healthy with Observability
A warehouse model doesn't stay trustworthy just because the original design was strong. It degrades through ordinary operational change. A source team adds a column. An ingestion job arrives late. A field starts subtly drifting. A join still works, but the business meaning shifts.

A warehouse model degrades quietly
This is why observability belongs in the lifecycle of warehouse data modeling, not as an afterthought. The model you designed is only useful if it remains structurally stable, timely, and semantically credible in production.
The operational risk is larger than many teams admit. The documented impact of data quality issues on AI systems notes that data quality problems cause an average of 15–30% of AI model failures, with silent data drift and schema changes as primary contributors. Those same failure modes affect warehouse models long before they show up as an AI incident. Dashboards break. Historical comparisons skew. Downstream jobs start succeeding technically while failing analytically.
A healthy warehouse isn't the one with the prettiest schema. It's the one that tells you quickly when reality no longer matches the model.
What to monitor after go-live
Once a model is in production, four monitoring categories matter more than most others.
Schema stability: Watch for added or removed columns, type changes, and renamed fields that can invalidate transformations or alter meaning.
Timeliness: Know when expected loads are late, missing, or incomplete so stale dashboards don't get mistaken for truth.
Metric behavior: Monitor unusual shifts in volumes, null rates, distributions, and relationship patterns that standard pipeline checks won't catch.
Rule compliance: Enforce business constraints at the record level where governance or audit requirements demand precision.
Modern observability platforms prove their worth. According to the verified platform description, digna combines AI-powered anomaly detection, timeliness monitoring, record-level validation, and schema tracking while running analyses inside customer-controlled environments. Its architecture is designed for in-database execution, private-cloud or on-prem deployment, and zero vendor data access.
That matters operationally because observability should sit close to the warehouse, not depend on extracting sensitive datasets into yet another tool. It also changes incident response. Instead of discovering problems after a CFO questions a dashboard, engineers can catch structural and behavioral issues earlier.
The deeper point is architectural. A warehouse model is a living asset. If you don't monitor whether the assumptions behind the model still hold, you don't really have a governed warehouse. You have a diagram and some luck.
Modeling for Today and Tomorrow
Warehouse data modeling is never just about picking a schema pattern. It's about aligning business questions, logical structure, physical performance, and operational trust into one system that can survive change.
The real deliverable is trust
The teams that do this well don't obsess over textbook purity. They make deliberate trade-offs. They choose Star when analysts need speed and clarity. They use more flexible core patterns when source volatility and lineage matter. They define grain early, preserve history on purpose, and tune the physical layer for the queries people run.
Just as important, they treat the warehouse as something that requires ongoing care. Models drift. Definitions expand. Platforms evolve. A design that worked last year may still be logically correct and operationally fragile.
That's why the strongest warehouse programs think in a full lifecycle. Choose the right blueprint. Build for readability and scale. Implement for workload reality. Monitor the model after it goes live. When those pieces stay connected, the warehouse becomes a durable source of truth instead of a recurring cleanup project.
If you want a practical way to protect the warehouse you've already built, digna helps teams monitor schema changes, data anomalies, timeliness, and validation directly inside customer-controlled environments so data issues surface before they damage dashboards, analytics, or downstream models.



