Data Owner Responsibilities: Guide to Key Duties 2026
|
0
min read

You've probably seen the moment already. An executive dashboard shows one revenue number in the board pack, another in finance, and a third in the BI tool your team trusts most. Slack fills up. Data engineers start checking pipelines. Analysts compare filters. Someone asks whether the CRM sync failed. Someone else blames definitions.
Most of the time, the problem isn't the dashboard. It's that nobody with enough authority owns the underlying dataset end to end.
That's why data owner responsibilities matter so much. A data owner isn't the person fixing every broken load or validating every row. The owner is the senior person who decides what the data means, what quality is acceptable, who gets access, how long it's retained, and what happens when something goes wrong. In modern environments, that responsibility only works when strategic accountability is matched with practical visibility into schemas, timeliness, record-level rules, and anomalies.
Table of Contents
The High Cost of Unowned Data
A familiar failure starts with a simple question from the CEO. Why did customer churn rise on one dashboard and fall on another?
Within an hour, the business is in a fire drill. BI is checking semantic logic. Engineering is reviewing late loads. Finance is asking whether historical records were reclassified. Nobody can answer the basic question quickly: who has the authority to say which dataset is the trusted one, and who is accountable for making sure it stays that way?

This is what unowned data looks like in practice. Not a dramatic system outage every time, but recurring uncertainty. Teams waste time reconciling numbers that should already be governed. Decisions slow down because every important metric needs a disclaimer attached to it. Trust erodes one report at a time.
Where the real failure sits
When ownership is vague, technical teams inherit decisions they shouldn't be making alone. Engineers can tell you a column changed. Analysts can tell you a KPI moved unexpectedly. Security teams can tell you access looks risky. But those groups shouldn't define business meaning, acceptable quality, retention intent, and risk tolerance without a senior decision-maker.
Practical rule: If a dataset can change a board-level decision, a budget, or a compliance posture, it needs a named owner with authority above the delivery team.
The gap is wider in modern data stacks because many failures don't announce themselves. Silent drift, schema changes, and unusual distributions can pass through pipelines without breaking them. Recent industry analysis cited by Censinet notes that 60% of data quality issues stem from silent drift and schema changes that evade manual detection in the discussion of data owner gaps and observability realities in this Censinet analysis of ownership roles.
That's the operational problem many governance models still underplay. They define accountability at a high level, but they don't tell owners how to supervise fast-moving data conditions day to day. If you want to estimate the business effect of these failures, a data downtime cost calculator is a useful way to frame the discussion in executive terms.
What ownership changes
A strong data owner reduces confusion before incidents happen. The owner makes the call on what the dataset is for, which controls matter most, and which teams execute the work. That turns governance from a vague ideal into a business operating model.
Unowned data creates meetings. Owned data creates decisions.
Who Is a Data Owner and Who Is Not
A data owner is a senior business leader who holds ultimate accountability for a defined data domain or dataset. That person isn't expected to write SQL, tune pipelines, or administer storage. The owner is expected to make binding decisions about meaning, quality expectations, access, retention, and risk.
In the UK government's data ownership model, the role is explicitly defined as a senior individual with dedicated accountabilities. That same model ties ownership to legal and operational duties, and notes that under GDPR, non-compliance can lead to fines of up to €20 million or 4% of global annual revenue in the relevant cases, as outlined in the UK government data ownership model.

The easiest way to separate the roles
The cleanest analogy is property.
Data owner is the house owner. They decide how the property is used, who is allowed in, what level of upkeep is acceptable, and when major fixes get funded.
Data steward is the property manager. They handle day-to-day quality work, coordinate follow-up, and keep the operating processes moving.
Data custodian is the maintenance crew. They run the infrastructure, storage, backups, permissions implementation, and platform operations.
Data user is the occupant or visitor. They consume the space, but they don't govern it.
That distinction matters because organizations often assign “ownership” to the person closest to the system. That's usually wrong. The engineer may operate the pipeline. The analyst may know the report. Neither automatically owns the business consequences of bad definitions, poor access decisions, or missing retention rules.
Who is not a data owner
A person is not a data owner just because they touch the data often.
Here are common false positives:
The busiest analyst: They know the KPI but may not have authority to set policy or accept risk.
The lead engineer: They operate the platform but shouldn't define business usage or regulatory intent.
The application admin: They can grant permissions in a tool, but that doesn't mean they should decide who ought to have access.
An executive with no domain connection: Seniority alone isn't enough. Owners need business accountability for the data's use.
The test is simple. Can this person approve quality thresholds, settle disputes over meaning, fund remediation, and accept the consequences of getting it wrong?
If the answer is no, they're not the owner.
What good ownership looks like
Good owners are close enough to the business to understand why the data exists, and senior enough to act when trade-offs appear. They don't disappear behind the phrase “that's a data team issue.” They sponsor controls, approve standards, and make escalation paths real.
That's why the strongest data owner responsibilities sit with leaders in finance, operations, clinical functions, risk, revenue, or product. The role is strategic, but it must still connect to operational evidence.
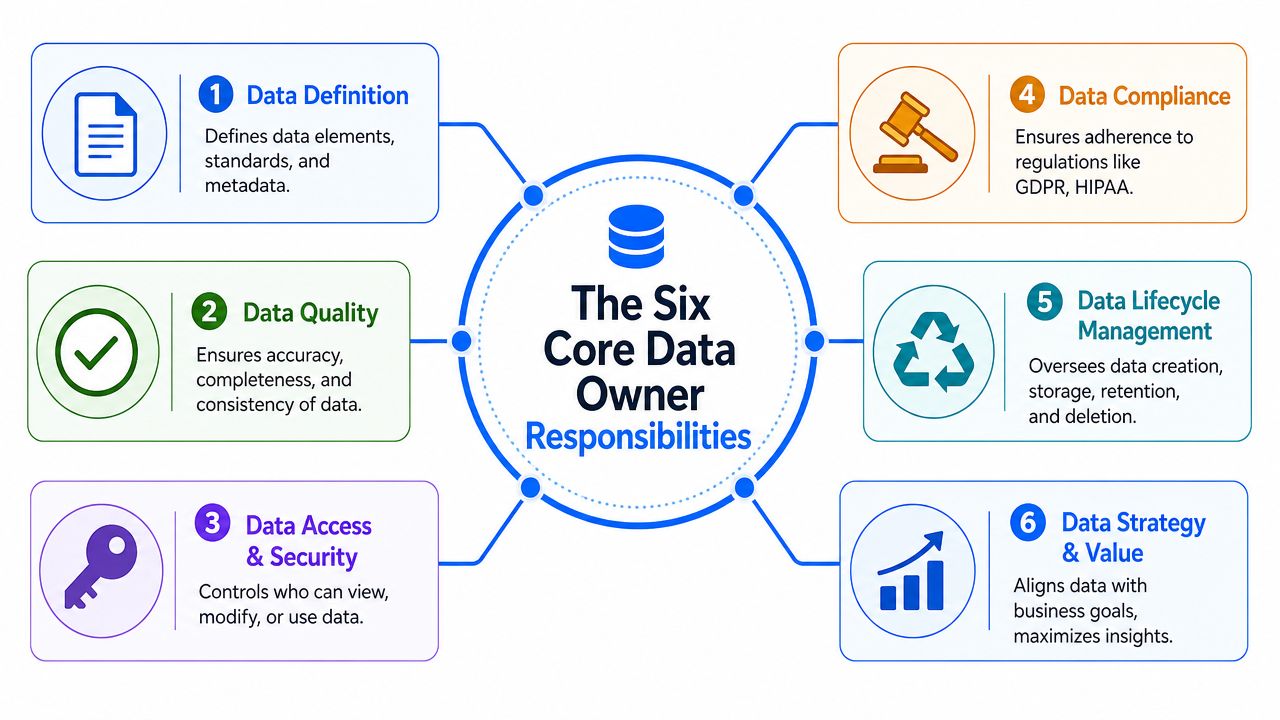
The Six Core Data Owner Responsibilities
The role becomes manageable when you break it into a handful of clear obligations. These are the core data owner responsibilities that matter most in practice.
Data ownership also sits inside a broader security and compliance context. If you want a grounded overview of the surrounding controls, this DFW data security and compliance guide is a practical companion for executives who need to align governance with enterprise risk.
Data quality
Owners don't clean records themselves. They define what “good enough” means and ensure teams can enforce it.
That includes setting expectations for accuracy, completeness, consistency, and timeliness. DataSunrise describes owners as responsible for classifying datasets, establishing data quality standards, and defining access policies, with senior healthcare leaders carrying ultimate responsibility for how datasets are safeguarded and used under frameworks such as HIPAA and GDPR in its overview of the data owner role in governance.
In practice, good ownership means the business doesn't say “make the data better.” It says things like:
customer status must align with approved business states
key financial records can't be posted with missing required fields
reference relationships must remain valid across source and reporting tables
delivery expectations for critical feeds must be explicit
Access management
The owner decides who should have access, at what level, and for what purpose.
That doesn't mean manually clicking permission settings in every platform. It means approving role-based access rules, deciding when broader access is justified, and ensuring sensitive data stays restricted to authorized users. A common failure is leaving these decisions to whichever technical team can implement them fastest.
A practical access model asks three questions:
Decision area | What the owner decides | What teams execute |
|---|---|---|
Business need | Who needs access and why | Steward validates request context |
Permission scope | Read, write, delete, export, admin | Custodian or admin applies controls |
Review cycle | When access must be reviewed | Governance and security track completion |
Compliance and security
Compliance ownership can't be delegated away just because technical controls exist. The owner must ensure the dataset is handled in line with the laws, contractual obligations, and internal policies that apply to it.
That means knowing whether the data contains regulated information, ensuring appropriate safeguards exist, and requiring evidence that controls are working. In regulated sectors, this is one of the most visible parts of the role because mistakes are expensive and public.
A weak control framework usually starts with a weak ownership decision, not a missing dashboard.
Data lifecycle management
Every important dataset needs a lifecycle. How is it created, stored, archived, retained, and disposed of? Who approves exceptions? When should historical records stop being available for routine use?
Owners should set policy for retention and disposal based on legal and business needs. Without that, teams either keep everything forever or delete too aggressively. Both create risk.
Common lifecycle decisions include:
Retention periods: How long records must remain available for business or legal reasons.
Archival rules: When older data moves to lower-cost or lower-access environments.
Disposal standards: How data is deleted or retired when it's no longer required.
Exception handling: Which cases justify extending retention or limiting deletion.
A short explainer can help anchor the operational side of those decisions:
Data lineage and documentation
Many ownership failures happen because the owner has accountability without visibility. If you can't trace where data came from, how it changed, and where it is used, you can't govern it well.
Owners should require current documentation for:
business definitions
critical fields and their meaning
upstream sources
downstream reports, models, and applications
known limitations and control points
This isn't documentation for its own sake. It's what allows the owner to judge impact when something changes.
Incident response
The owner plays a decisive role when data incidents happen. They may not diagnose the root cause personally, but they must be part of the decision chain when a dataset is unreliable, exposed, delayed, or structurally changed.
Good incident ownership includes:
Confirming business impact so the organization knows what decisions or reports are affected.
Approving remediation priorities when teams have several possible fixes.
Directing communication to stakeholders who depend on the dataset.
Demanding follow-up controls so the same issue is prevented from repeating.
The owner is the person who closes the loop between technical recovery and business accountability. Without that, incidents get fixed narrowly and then recur in a slightly different form.
A Practical RACI Matrix for Data Governance
If ownership is clear in theory but fuzzy in practice, use a RACI matrix. It forces a team to decide who is Responsible, Accountable, Consulted, and Informed for each recurring governance task.
That distinction matters. Responsible means doing the work. Accountable means answering for the outcome. In healthy governance models, the data owner is very often the A, even when someone else is doing the daily execution.
How to read the matrix
A useful RACI prevents two common failures. First, the same task doesn't end up with three teams all assuming someone else has it. Second, the owner doesn't get dragged into routine execution that should stay with stewards or technical teams.
Tacto notes that data owners must establish quantifiable thresholds for accuracy, completeness, and timeliness, and that when owners explicitly approve record-level validation rules aligned with business logic, organizations see a 30-40% reduction in data incident response times in the context of that ownership model, as described in this data owner glossary entry from Tacto. If you want a broader operating context for that kind of role clarity, this overview of what data governance is is a helpful reference.
Operating advice: If the data owner is marked Responsible for too many technical tasks, the matrix is wrong. If the owner is missing from Accountable on high-risk tasks, the matrix is also wrong.
Sample RACI for common governance tasks
Governance task | Data owner | Data steward | Data custodian | Data engineer |
|---|---|---|---|---|
Define business meaning of critical fields | A | R | I | C |
Set data quality thresholds | A | R | I | C |
Approve record-level validation rules | A | C | I | R |
Grant access policy approval | A | C | R | I |
Implement technical access controls | I | C | A/R | I |
Monitor pipeline failures | I | C | C | A/R |
Assess business impact of bad data | A | R | I | C |
Approve retention and disposal policy | A | C | R | I |
Archive or delete data per policy | I | C | A/R | C |
Coordinate incident communications | A | R | I | C |
A few patterns are worth keeping.
The owner holds accountability for business rules. They shouldn't be optional in quality, access, retention, or incident impact decisions.
The steward carries operational continuity. This role keeps standards alive day to day.
The custodian owns technical enforcement in the environment. Storage, system permissions, and platform controls sit here.
The engineer handles delivery mechanics. Pipelines, tests, and runtime fixes belong with engineering.
If your current matrix puts accountability with whichever team gets paged first, you don't have governance. You have escalation by exhaustion.
How Modern Observability Enables Data Owners
A newly appointed data owner usually hits the same wall within weeks. The policy is signed, the domain is assigned, and the first serious issue still arrives as a surprise. A board metric is wrong, a regulatory extract is late, or a product team is using a field whose meaning changed three releases ago. Accountability stays with the owner, even when the warning signs were buried in pipeline logs and scattered team dashboards.
That is the operating gap modern observability closes. It gives data owners a practical way to see whether the controls they approved are still holding in production, across systems they will never inspect by hand.
Why dashboards alone don't solve owner accountability
Dashboards report outcomes. Data ownership requires earlier signals.
A dashboard can show that yesterday's KPI loaded successfully and still miss the fact that key records arrived six hours late, a join started dropping rows after a schema change, or a distribution shift made the number technically complete but operationally misleading. By the time the issue appears in an executive report, the owner is already in incident mode.
Owners need monitoring that reflects business commitments, not just system health. They need evidence tied to the policies they approve, such as freshness standards, quality tolerances, access expectations, and high-risk structural changes. In private cloud and on-prem environments, that requirement gets harder because governance teams often cannot depend on broad vendor-side access to production data. Egnyte discusses these control boundary issues in its data ownership guide. The practical implication is straightforward. Observability has to work within the environment the enterprise operates, not the one a tool vendor wishes existed.
What capable observability changes
Good observability gives the owner usable evidence at the points where governance usually breaks down.
Anomaly detection: Owners need automated detection of unusual volume, null rates, value distributions, and other changes that matter to business use. Manual threshold tuning does not scale across a large portfolio of datasets, especially when normal behavior shifts over time. That kind of monitoring is reflected in digna's Data Anomalies capability.
Timeliness monitoring: Data can be accurate and still create business risk if it arrives too late for finance, operations, or compliance use. Timeliness checks should compare actual delivery behavior to expected schedules and learned patterns, as described in digna's timeliness monitoring overview.
Schema tracking: A column added, removed, renamed, or changed in type can break downstream logic long before a business user can explain what went wrong. Continuous structural tracking helps owners identify changes that require a policy decision, an exception, or a communication plan. That capability is described in digna's schema tracking and validation expansion.
Record-level validation: Many governance failures sit below the dashboard layer. Multi-column uniqueness, referential integrity, conditional rules, and row-level checks are often what separate a trusted dataset from one that creates audit findings and operational rework. Those controls were highlighted in digna's platform release with validation features.
The practical value is not more alerts. It is better triage.
A strong observability setup helps the owner answer four questions quickly. What changed? Which business process is exposed? Has a policy threshold been breached? Who owns the next action? Without those answers, accountability turns into routine escalation and delayed decisions.
It also helps to separate two ideas that often get blurred together. Quality defines the standards. Observability shows whether those standards are holding under real operating conditions, including failure modes nobody wrote a rule for in advance. This comparison of data observability vs data quality is a useful short reference for that distinction.
For data owners, that difference matters. Strategy sets the expectation. Observability shows whether the expectation survives contact with live systems.
An Enterprise Checklist for Implementing Data Ownership
A new data owner gets named after a reporting failure, an audit issue, or a customer-impacting data incident. That is common. The harder part starts the next day, when the title exists but decision rights, controls, and monitoring still do not.
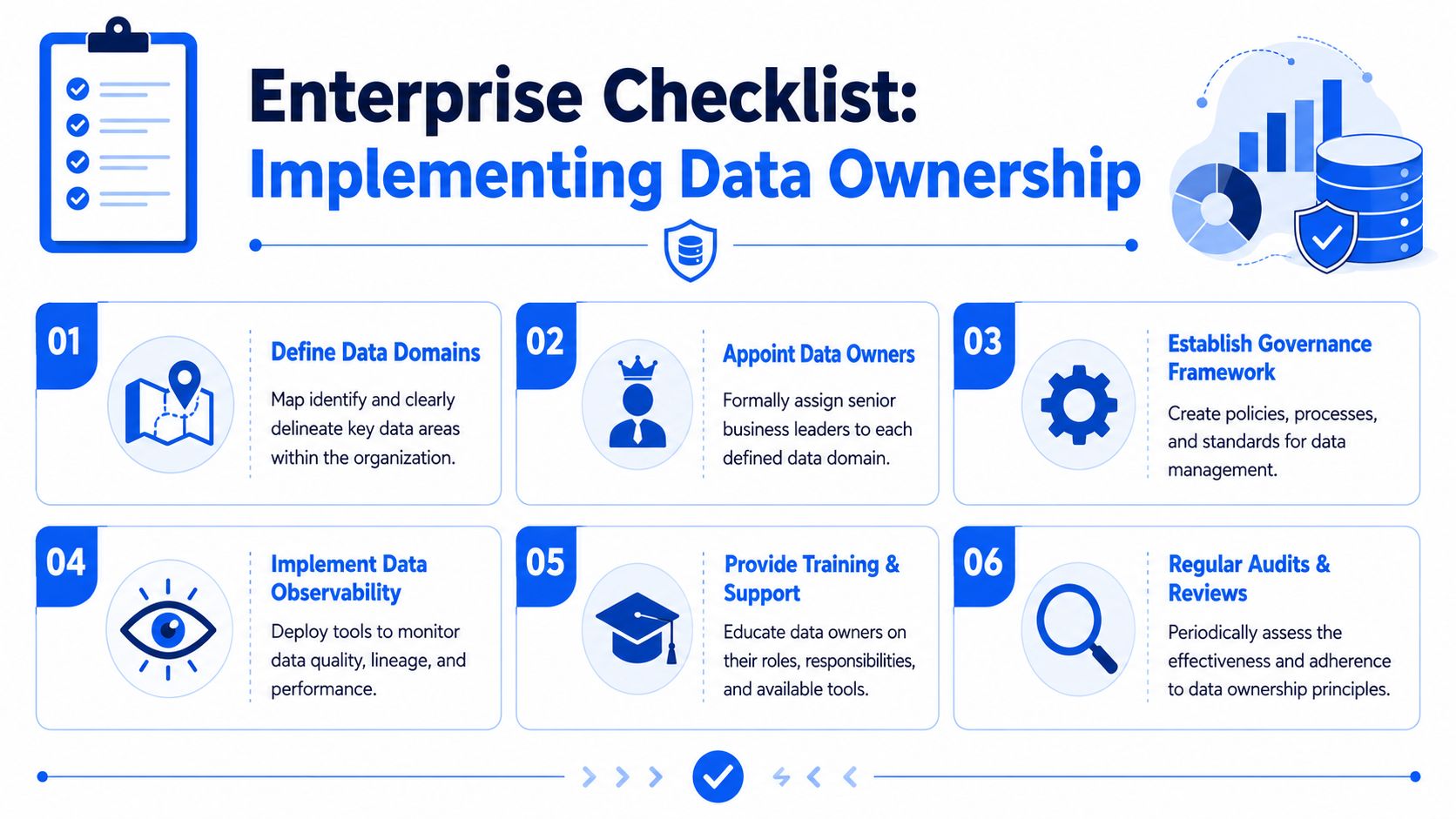
Ownership becomes real only when the organization gives the owner a defined scope, clear authority, and evidence they can act on. Without that, the role turns into a name on a slide deck while operational teams continue to make fragmented decisions.
What to put in place first
Use this checklist to build an ownership model that holds up under day-to-day operating pressure.
Define data domains clearly. Start with the datasets tied to executive reporting, regulated processes, customer operations, or revenue execution. Keep boundaries specific enough that one owner can make decisions without overlap or constant arbitration.
Appoint senior business owners formally. Assign the role to the executive or business leader who can approve trade-offs, fund remediation, and accept the consequences of bad data decisions. Technical leads, stewards, and platform teams support the role, but they should not carry business accountability by default.
Document the policies the owner is expected to approve. Focus on quality thresholds, access rules, retention expectations, and incident escalation. The point is not paperwork. The point is giving the owner a clear standard to govern against when a team asks for an exception or when an audit trail is needed.
Create a working RACI. Keep it practical. Who approves access? Who sets quality thresholds? Who investigates failures? Who communicates business impact? If those answers still depend on who joins the meeting, ownership is not in place yet.
Put observability on the highest-risk domains first. Data owners are accountable for outcomes, but they still need operating evidence. Start where late pipelines, schema drift, failed validations, or silent anomalies would affect compliance, financial reporting, or customer experience. That is the link between strategic accountability and operational control.
Set a review cycle for ownership assignments. Reorgs, system migrations, acquisitions, and new regulations can all break an ownership model that once made sense. Review domain scope, named owners, and escalation paths on a set cadence instead of waiting for a failure.
The trade-off is straightforward. A lightweight model is faster to launch, but it usually leaves owners blind when incidents cross systems or teams. A stricter model takes more setup, yet it gives the business a clear chain of accountability and a practical way to monitor whether controls are holding.
A mature program does not expect data owners to inspect pipelines or write validation rules themselves. It gives them policy authority, reliable reporting on the health of their domains, and a clear path to trigger action when risk crosses a threshold.
If you're building a practical ownership model and need observability that works in private cloud or on-prem environments without vendor access to production data, digna is worth evaluating. It supports anomaly detection, record-level validation, schema tracking, and timeliness monitoring in customer-controlled environments, which makes it easier for data owners to stay accountable without taking on day-to-day technical monitoring themselves.



