Dominando el modelado de datos de almacén: Conceptos y producción
|
0
minuto de lectura

Sus dashboards se están cargando, pero nadie confía en ellos. El equipo de Finanzas dice que los ingresos no cuadran. El de Operaciones ve registros faltantes. Los analistas pasan más tiempo explicando por qué se movió una métrica que qué hacer al respecto. Ese suele ser el momento en que los equipos se dan cuenta de que el almacén no está fallando por la sintaxis SQL o las herramientas de BI. Está fallando porque el modelo debajo del almacén nunca se convirtió en un sistema duradero.
Un buen modelado de datos de almacén convierte los datos operativos dispersos en algo que las personas pueden consultar, comprender y en lo que pueden confiar. También define qué tan doloroso será el cambio más adelante. Un modelo que parece limpio en un diagrama aún puede colapsar bajo datos que llegan tarde, definiciones poco claras, uniones lentas y desviaciones de esquema. Un modelo que funciona en producción tiene que sobrevivir a todas esas presiones a la vez.
Tabla de Contenidos
Por qué el modelado de datos de almacén es su base analítica
Manteniendo la salud de su modelo de datos con Observability
Por qué el modelado de datos de almacén es su base analítica
Cuando un equipo dice "nuestros datos están desordenados", el problema subyacente suele ser estructural. Las tablas reflejan el comportamiento de la aplicación en lugar del significado del negocio. Las métricas se calculan de tres maneras diferentes. Los cambios históricos se sobrescriben, por lo que nadie puede responder cómo se veía un cliente, producto o contrato en un momento anterior.
Ahí es donde el modelado de datos de almacén importa. Ofrece a los analistas un lenguaje estable para el negocio. En lugar de entrelazar pedidos sin procesar, registros de clientes, facturas y registros de estado cada vez que alguien necesita un informe, el almacén proporciona entidades duraderas, uniones consistentes y definiciones acordadas.

La confianza se rompe antes que los pipelines
Un pipeline puede terminar con éxito y aun así producir análisis deficientes. Los datos pueden llegar a tiempo, pero el modelo aún puede ocultar duplicaciones, aplanar relaciones de forma incorrecta o borrar el historial que los usuarios finales necesitan para el análisis de tendencias y el trabajo de auditoría.
La consecuencia práctica es simple. Los malos modelos crean discusiones. Los buenos modelos crean decisiones.
Regla práctica: Si un usuario de negocio necesita que un ingeniero de datos le explique cada unión de un dashboard, el modelo todavía está demasiado cerca de los sistemas de origen.
Un modelo de almacén sólido realiza tres funciones a la vez:
Crea consistencia: Las definiciones de cliente, producto e ingresos dejan de cambiar de un dashboard a otro.
Soporta el análisis histórico: Los equipos pueden responder no solo qué es verdad ahora, sino qué era verdad en un momento específico.
Mejora la mantenibilidad: Los ingenieros pueden agregar nuevas fuentes y métricas sin tener que reescribir toda la capa analítica.
El modelado es una disciplina antigua con consecuencias modernas
El almacenamiento de datos no apareció con las plataformas en la nube. La arquitectura detrás de este se remonta a décadas atrás. La historia de la arquitectura de almacenes de datos rastrea la disciplina hasta la década de 1980, cuando se desarrolló el enfoque central para transformar los datos operativos en sistemas de soporte a las decisiones. Ese cambio brindó a las organizaciones una forma de consolidar datos de dominios operativos separados y hacerlos útiles para el análisis.
El paso de almacenamiento orientado a mainframes hacia almacenes híbridos y en la nube cambió los detalles de implementación, pero no eliminó la necesidad de modelar. Elevó las expectativas. Los almacenes modernos tienen que absorber más datos, más cambios y más usuarios, al mismo tiempo que preservan el contexto histórico.
Por eso, los equipos que se apresuran directamente a la ingesta y a los dashboards a menudo se estancan. Cargar datos no es lo mismo que organizarlos. Un almacén se vuelve útil solo cuando el modelo coincide con la forma en que el negocio hace las preguntas.
Eligiendo su plano: Estrella, Copo de Nieve o Data Vault
La forma más sencilla de explicar los estilos de modelado es compararlos con el diseño de una biblioteca. Una biblioteca está organizada para una navegación rápida. Otra está organizada para una categorización precisa. Una tercera está construida como un archivo, donde preservar el linaje es tan importante como la recuperación de información.
Los modelos de almacén de datos hacen las mismas concesiones.
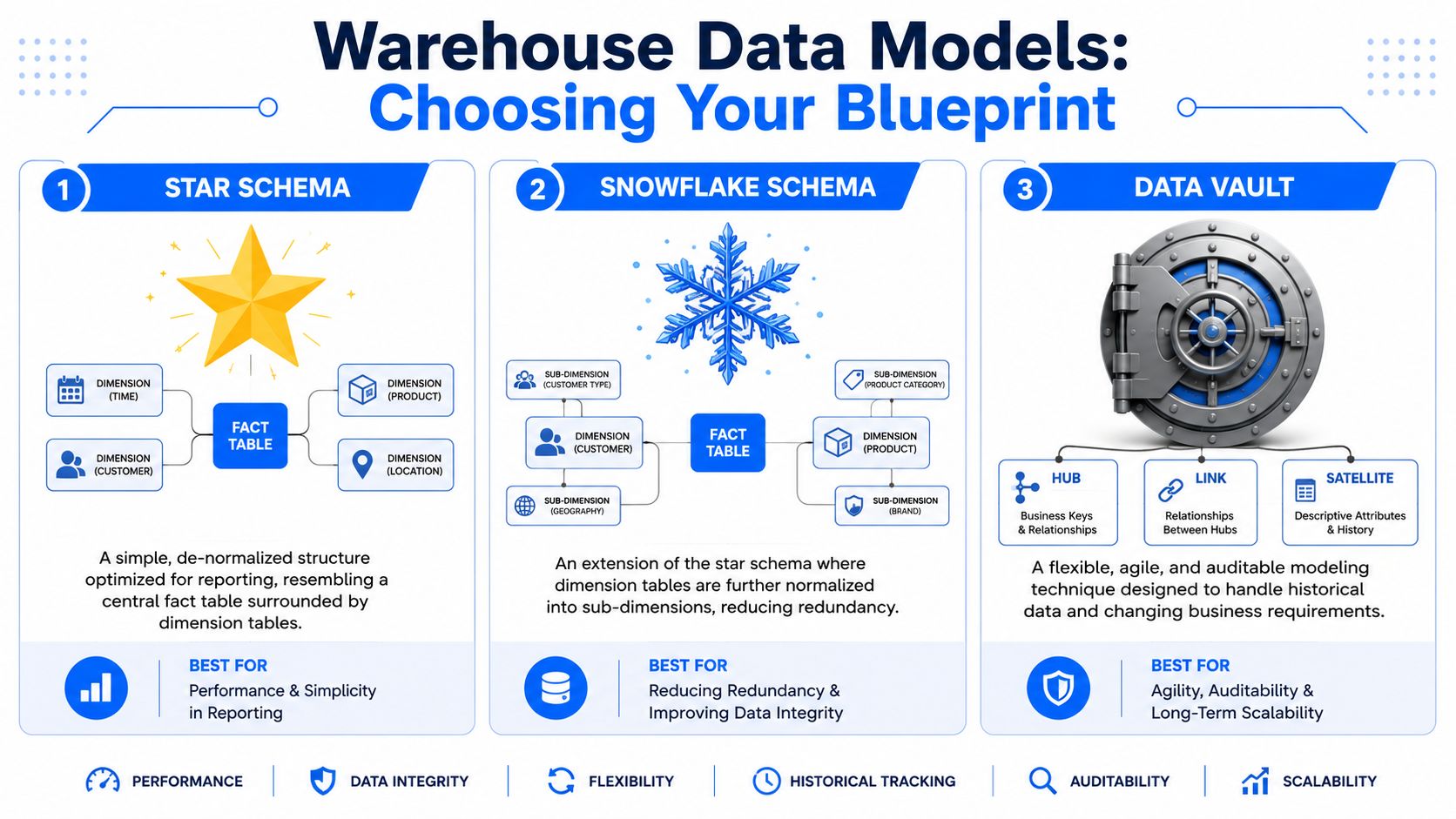
Pense de el modelo como una biblioteca
Un Esquema en Estrella es la biblioteca fácil de navegar. Una tabla de hechos central contiene eventos medibles como pedidos, reclamaciones, vistas de página o facturas. Las tablas de dimensiones proporcionan contexto como cliente, producto, región y fecha. Es fácil de enseñar, fácil de consultar y, por lo general, la elección correcta cuando el BI es la carga de trabajo principal.
Un Esquema en Copo de Nieve parte de la misma idea dimensional, pero normaliza algunas dimensiones en subdimensiones. Producto puede dividirse en tablas de marca, categoría y proveedor. Geografía puede dividirse en ciudad, región y país. Se reduce la redundancia, pero se añade complejidad a las uniones.
Un Data Vault es más cercano a un sistema de archivo. Separa las claves de negocio estables, las relaciones y el historial descriptivo en estructuras distintas. Según la descripción general de ER/Studio sobre patrones de modelado de almacenes, el Esquema en Estrella domina los requisitos de simplicidad y velocidad, mientras que Data Vault no tiene rival para las empresas que se enfrentan a entornos que cambian rápidamente y a demandas regulatorias estrictas. Esa misma fuente describe Data Vault como una estructura de hubs para entidades de negocio principales, links para relaciones y satélites para atributos descriptivos e historial de cambios.
Para los equipos que diseñan opciones visualmente, una referencia de diagrama de arquitectura de datos puede ayudar a aclarar cómo difieren estos patrones una vez que se pasa de la pizarra a la implementación.
Para qué optimiza cada patrón
Esto es lo que suele funcionar en la práctica.
El Esquema en Estrella funciona mejor cuando los analistas necesitan informes rápidos y predecibles, y el negocio puede alinearse en torno a hechos y dimensiones claros.
El Copo de Nieve funciona mejor cuando la reutilización de dimensiones y una normalización más estricta importan más que la simplicidad para el analista.
Data Vault funciona mejor cuando los sistemas de origen cambian con frecuencia, el linaje importa y preservar el historial sin procesar es esencial.
Los modelos 3NF se adaptan mejor cuando se necesita fidelidad operativa en una capa de integración fundamental, pero generalmente necesitan otra capa de presentación antes de que la mayoría de los analistas puedan utilizarlos cómodamente.
La trampa está en elegir basándose en la ideología. Muchos equipos eligen Data Vault porque suena de nivel empresarial, para luego descubrir que siguen necesitando marts dimensionales para los informes. Otros aplanan todo en estrellas demasiado pronto y se arrepienten cuando los sistemas de origen cambian cada trimestre.
Estrella para usabilidad. Copo de nieve para una normalización más estricta. Data Vault para adaptabilidad y auditabilidad.
Una arquitectura práctica a menudo mezcla patrones. Las capas crudas y centrales pueden preservar la fidelidad del origen y el historial de cambios. Los marts orientados a la analítica pueden seguir presentando un esquema en estrella porque eso es lo que las herramientas de BI y los analistas utilizan con mayor facilidad.
Más adelante en la sección, resulta útil ver las ventajas y desventajas en acción:
Comparación de enfoques de modelado de datos
Criterio | Esquema en Estrella | Esquema en Copo de Nieve | Data Vault |
|---|---|---|---|
Rendimiento de consultas | Normalmente sólido para consultas de BI porque las uniones son directas | Puede ser más lento de navegar porque las dimensiones están más normalizadas | Sólido para patrones de linaje e ingesta, pero por lo general no es la forma final para informes |
Usabilidad para el analista | Alta. Los usuarios de negocio pueden entenderlo rápidamente | Moderada. Más uniones y saltos entre tablas | Menor para usuarios de autoservicio a menos que construya marts por encima |
Eficiencia de almacenamiento | Menor que los diseños más normalizados | Mejor que la estrella en algunas dimensiones porque se reduce la redundancia | Varía, a menudo con más tablas y más registros históricos |
Flexibilidad ante cambios | Moderada | Moderada | Alta |
Seguimiento histórico | Bueno cuando se modela deliberadamente | Bueno cuando se modela deliberadamente | Excelente por diseño |
Gobernanza y auditabilidad | Buena, depende de la disciplina | Buena | Sólida |
Complejidad de implementación | Menor | Media | Alta |
La decisión debe provenir de su carga de trabajo, no de las modas. Si los ejecutivos necesitan dashboards de KPI confiables cada mañana, comience con la forma que facilite esas consultas. Si los reguladores, los auditores o los programas con uso intensivo de integración impulsan el diseño, optimice primero para el linaje y el cambio controlado.
Principios del diseño de almacenes de alto rendimiento
Un modelo de almacén puede usar diferentes patrones y aun así fallar por las mismas razones. Los puntos comunes de falla son casi siempre estratégicos. Grano incorrecto. Diseño centrado en el origen. Nombres poco claros. Sin plan de crecimiento. Sin propiedad sobre las definiciones.

Comience con los procesos de negocio, no con los sistemas de origen
El almacén debe modelar lo que hace la organización. Pedidos. Envíos. Reclamaciones. Pagos. Sesiones de aplicación. Casos de soporte. Si el diseño comienza con las tablas que resulten llegar de Salesforce, SAP o de una base de datos de productos, heredará las peculiaridades de la aplicación en lugar de la lógica de negocio.
He encontrado una regla especialmente confiable: defina primero el evento de negocio, luego decida cómo lo representará el almacén. Eso mantiene las tablas de hechos ancladas a algo medible y repetible.
Un almacén dura más cuando sus entidades principales sobreviven a una migración de sistema.
Diseñe para lectores, crecimiento y control
Los analistas y desarrolladores de BI son lectores del modelo. Los ingenieros de datos son mantenedores del modelo. Los equipos de governance son los propietarios del riesgo del modelo.
Utilice esto como una lista de verificación esencial:
Claridad sobre ingenio: Prefiera nombres de tablas y columnas que un nuevo analista pueda entender sin tener que abrir cinco archivos de transformación.
Grano estable: Cada tabla de hechos necesita una definición explícita a nivel de fila. Si no puede expresar el grano en una sola frase, la tabla no está lista.
Escalabilidad desde el primer día: Asuma que el volumen, la concurrencia y las nuevas áreas temáticas crecerán. Adaptar la escala a posteriori es costoso.
Consciencia del rendimiento: La elegancia lógica no es suficiente. Si las consultas comunes requieren escaneos y uniones excesivas, los usuarios exportarán los datos a hojas de cálculo y buscarán alternativas al almacén.
Gobernanza integrada: Las reglas de acceso, el linaje, los controles de calidad y la propiedad no pueden posponerse para "más adelante".
La contratación de personal también importa aquí. Con frecuencia, los equipos cuentan con ingenieros de pipelines capacitados, pero carecen de alguien que pueda conectar el modelado, las limitaciones de la plataforma y la semántica de negocio. Si está construyendo o reelaborando un programa de almacenamiento, un socio de contratación especializado en Cloud Data Architect recruitment puede ser de utilidad, ya que los errores de arquitectura suelen aparecer mucho después de haber tomado la decisión de contratación.
El modelo también debe dar espacio a un diseño por capas. Las capas cruda, de staging, central, analítica y agregada resuelven cada una un problema diferente. El error es colapsarlas en una sola porque parece más veloz. Es más rápido al principio. Es más lento cada mes posterior.
De preguntas de negocio a esquemas de almacén
Los mejores modelos lógicos comienzan con conversaciones incómodas. Las partes interesadas suelen pedir "un dashboard de ventas" o "visión de cliente 360" cuando lo que necesitan es respaldar bien un puñado de decisiones muy específicas. Su trabajo consiste en forzar la precisión antes de diseñar una sola tabla de hechos.

Convierta las preguntas en grano
Tome una pregunta de negocio como: "¿Cuáles fueron nuestros ingresos mensuales por producto por región?"
Esa pregunta ya sugiere la estructura:
El proceso de negocio son las ventas o la facturación.
La medida son los ingresos.
La perspectiva temporal es mensual.
Las dimensiones de desglose son producto y región.
Pero el modelo no debería saltar directamente a una tabla mensual. La primera tarea consiste en definir el grano útil más bajo. ¿Es una fila una línea de pedido, una línea de factura, un envío o un registro resumido diario? En la mayoría de los almacenes, elegir el evento de negocio confiable más atómico mantiene abierto el análisis futuro.
Una secuencia práctica se ve así:
Entreviste para tomar decisiones, no para crear dashboards: Pregunte qué acción se deriva de la métrica. Si nadie actúa en consecuencia, no la modele primero.
Haga una lista de los procesos principales: Las ventas, devoluciones, suscripciones, reclamaciones, tickets o eventos de sensores suelen convertirse en dominios de hechos separados.
Declare el grano temprano: "Una fila por línea de factura" es claro. "Una fila por resumen de transacción de cliente" normalmente no lo es.
Nombre las dimensiones a partir del lenguaje de negocio: Cliente, producto, región, canal, representante de ventas y fecha son más fáciles de gobernar que las etiquetas específicas de origen.
Resuelva la semántica de las métricas antes de la construcción: Los ingresos, el cliente activo y el churn son conocidos por parecer sencillos mientras ocultan decisiones de política interna.
Nota de campo: La mayor parte del retrabajo ocurre porque los equipos se saltaron la definición del grano y descubrieron más tarde que una tabla mezclaba eventos, instantáneas y resúmenes derivados.
Una guía enfocada en la planificación de integración de almacenes es útil durante esta etapa porque la incorporación de fuentes afecta elecciones clave de diseño, como las claves de negocio, los registros que llegan tarde y la uniformidad entre sistemas.
Pase de entidades a esquemas funcionales
Una vez que las preguntas estén claras, asocie primero los conceptos en un modelo conceptual. Manténgalo orientado al negocio. El cliente compra el producto. El pedido pertenece a la región. La factura hace referencia al contrato. El pensamiento de entidad-relación ayuda en este proceso, incluso si el almacén final no va a ser un diseño puramente ER.
El modelo lógico viene a continuación. Ahí es donde se definen las claves, los atributos y las relaciones con la suficiente precisión para que ingeniería pueda implementarlos. Los hechos obtienen claves foráneas hacia las dimensiones. Las dimensiones obtienen identificadores estables y atributos descriptivos. Las dimensiones compartidas se unifican para que el mismo cliente o producto signifique lo mismo en todos los marts.
Una buena sesión de revisión en este punto plantea preguntas como:
Pregunta de revisión | Por qué importa |
|---|---|
¿Qué representa la fila en esta tabla? | Evita la confusión por mezcla de granos |
¿Qué proceso de negocio representa? | Mantiene los modelos anclados a la realidad |
¿Qué dimensiones se reutilizan en otros lugares? | Sostiene la uniformidad y la consistencia |
¿Qué historial debe conservarse? | Evita sobrescrituras destructivas |
¿Qué métricas corresponden a la parte inicial frente a BI? | Reduce la lógica duplicada |
El modelo físico viene después. Pero si el modelo lógico es ambiguo, la optimización física no lo salvará.
Implementación física y optimización del rendimiento
Un diseño lógico puede ser perfectamente sensato y, aun así, tener un rendimiento deficiente cuando se enfrenta a patrones de consulta reales. En este punto, el modelado de datos de almacén deja de ser conceptual y se convierte en ingeniería.
Los modelos lógicos no garantizan consultas rápidas
La capa física importa porque los motores de consulta no ejecutan diagramas. Ejecutan diseños de almacenamiento, patrones de agrupamiento, reglas de poda de particiones y estrategias materializadas. Las pautas de modelado físico sobre opciones de diseño específicas para motores hacen esto concreto: particionar una tabla de hechos por fecha puede reducir la carga por escaneo entre un 60 y un 80 % para las consultas que filtran registros recientes, y el agrupamiento en claves de dimensión de alta cardinalidad puede mejorar la eficiencia de las uniones hasta en un 45 % en implementaciones de esquemas en estrella.
Eso cambia la forma en que debe pensar sobre la implementación. Una tabla de hechos con un filtro order_date en casi todos los dashboards normalmente debería estar organizada físicamente para aprovechar ese patrón de acceso. Un esquema en estrella que realiza uniones constantemente mediante customer_id u otra clave de dimensión selectiva debería reflejar eso en el agrupamiento o diseño equivalente específico del motor.
Las prioridades habituales de optimización son:
Particionar según filtros temporales comunes: Si los usuarios consultan períodos recientes constantemente, la partición basada en fechas suele ser la primera victoria.
Agrupar en torno a uniones selectivas: Las claves de alta cardinalidad pueden mejorar la localización para uniones repetidas.
Materializar con intención: No todas las transformaciones deben seguir siendo una vista. El uso recurrente y las uniones costosas suelen justificar la materialización en tablas.
Separar las capas de servicio de la ingesta de datos brutos: Las tablas de datos brutos preservan la fidelidad. Las tablas de entrega de informes deben adaptarse a la estructura de la carga de trabajo.
Para los equipos que gestionan opciones de optimización específicas de la plataforma, esta guía para optimizar su almacén de datos para lograr la máxima eficiencia con herramientas modernas de calidad de datos es un complemento útil para el trabajo de diseño lógico.
Gestione el historial deliberadamente
El seguimiento histórico es uno de las primeras áreas donde los atajos de diseño resultan ser costosos. Si un cliente cambia de región, segmento o categoría de precios, usted necesita saber si los informes deben reflejar el valor actual o el valor en el momento del evento.
En los modelos dimensionales, las Dimensiones de Cambio Lento de Tipo 2 son el mecanismo estándar para preservar el historial. La idea básica es sencilla: cerrar la fila de la dimensión antigua, insertar una nueva y utilizar fechas de vigencia o ventanas de validez para que los hechos puedan unirse a la versión histórica correcta.
Un patrón sencillo se ve así:
Este patrón no es glamuroso, pero protege el análisis de tendencias, los informes históricos a fecha pasada y la auditabilidad. Los equipos que sobrescriben dimensiones porque les parece más sencillo suelen acabar reconstruyendo la lógica histórica más adelante bajo la presión de plazos urgentes.
Manteniendo la salud de su modelo de datos con Observability
Un modelo de almacén no mantiene su confianza solo porque el diseño original fuera sólido. Se degrada a través de los cambios operativos habituales. Un equipo de origen agrega una columna. Un trabajo de ingesta llega tarde. Un campo comienza a desviarse sutilmente. Una unión sigue funcionando, pero el significado de negocio cambia.

Un modelo de almacén se degrada silenciosamente
Es por esto que la observabilidad pertenece al ciclo de vida del modelado de datos de almacén, no como una idea tardía. El modelo que diseñó solo es útil si se mantiene estructuralmente estable, oportuno y semánticamente creíble en producción.
El riesgo operativo es mayor de lo que muchos equipos admiten. El impacto documentado de los problemas de calidad de datos en sistemas de IA señala que los problemas de calidad de datos causan un promedio de 15–30 % de las fallas en modelos de IA, siendo la desviación silenciosa de datos y los cambios de esquema los principales contribuyentes. Esos mismos modos de falla afectan a los modelos de almacén mucho antes de que se muestren como un incidente de IA. Los dashboards se rompen. Las comparaciones históricas se distorsionan. Los trabajos downstream comienzan a tener éxito técnicamente mientras fallan analíticamente.
Un almacén saludable no es el que tiene el esquema más bonito. Es el que le avisa rápidamente cuando la realidad ya no coincide con el modelo.
Qué monitorear después de la puesta en marcha
Una vez que un modelo está en producción, cuatro categorías de monitoreo importan más que la mayoría.
Estabilidad del esquema: Vigile las columnas añadidas o eliminadas, los cambios de tipo y los campos renombrados que puedan invalidar transformaciones o alterar el significado.
Puntualidad: Sepa cuándo las cargas esperadas se retrasan, faltan o están incompletas para que los dashboards desactualizados no se confundan con la realidad.
Comportamiento de métricas: Monitoree cambios inusuales en volúmenes, tasas de nulos, distribuciones y patrones de relación que las verificaciones estándar de pipelines no detectarán.
Reglas de cumplimiento: Aplique restricciones de negocio a nivel de registro cuando los requisitos de governance o auditoría exijan precisión.
Las plataformas modernas de observabilidad demuestran su valor. De acuerdo con la descripción verificada de la plataforma, digna combina la detección de anomalías asistida por IA, el monitoreo de puntualidad, la validación a nivel de registro y el seguimiento de esquemas, ejecutando los análisis dentro de entornos controlados por el cliente. Su arquitectura está diseñada para la ejecución en base de datos, implementación en nube privada o local, y cero acceso de datos por parte del proveedor.
Eso importa operativamente porque la observabilidad debe estar cerca del almacén, sin depender de extraer conjuntos de datos sensibles hacia otro software adicional. También cambia la respuesta a incidentes. En lugar de descubrir problemas después de que un director financiero cuestione un dashboard, los ingenieros pueden detectar problemas estructurales y de comportamiento antes.
El punto de fondo es arquitectónico. Un modelo de almacén es un activo vivo. Si no monitorea si los supuestos detrás del modelo aún se mantienen, en realidad no tiene un almacén gobernado. Tiene un diagrama y algo de suerte.
Modelado para hoy y mañana
El modelado de datos de almacén nunca se trata solo de elegir un patrón de esquema. Se trata de alinear las preguntas de negocio, la estructura lógica, el rendimiento físico y la confianza operativa en un único sistema capaz de sobrevivir al cambio.
El entregable real es la confianza
Los equipos que logran esto bien no se obsesionan con la pureza de los libros de texto. Hacen concesiones deliberadas. Eligen Estrella cuando los analistas necesitan velocidad y claridad. Utilizan patrones de núcleo más flexibles cuando la volatilidad del origen y el linaje de datos importan. Definen el grano temprano, preservan el historial con propósito y optimizan la capa física para las consultas que la gente ejecuta.
De igual importancia, tratan el almacén como algo que requiere atención continua. Los modelos se desvían. Las definiciones se expanden. Las plataformas evolucionan. Un diseño que funcionó el año pasado puede seguir siendo lógicamente correcto y operativamente frágil.
Por eso, los programas de almacén de datos más sólidos piensan en un ciclo de vida completo. Elija el plano adecuado. Construya para legibilidad y escala. Implemente según la realidad de la carga de trabajo. Monitoree el modelo tras su puesta en marcha. Cuando esas piezas se mantienen conectadas, el almacén se convierte en una fuente duradera de verdad en lugar de un proyecto recurrente de corrección de errores.
Si desea una forma práctica de proteger el almacén que ya ha construido, digna ayuda a los equipos a monitorear cambios de esquema, anomalías de datos, puntualidad y validación directamente en entornos controlados por el cliente, para de esta forma detectar los problemas de datos antes de que dañen los dashboards, la analítica o los modelos downstream.



