Reliability of Data
|
0
minuto de lectura

You're probably dealing with this already. A dashboard is on the screen, leadership is waiting for an answer, and someone says, “These numbers don't look right.” The meeting stops being about strategy and turns into a forensic exercise. Which table loaded late? Did the CRM export miss records? Did a schema change break a transformation three layers upstream?
That moment is what data reliability looks like in practice. Not an abstract quality score. Not a governance slogan. It's whether people can act without second-guessing the evidence in front of them.
Teams usually feel this problem first in the most ordinary places: sales pipeline rollups, finance close reporting, inventory feeds, product analytics, and machine learning features. Even routine extraction work can create trust gaps if nobody verifies what left the source system and what arrived downstream. For teams cleaning up brittle CRM pulls, Tutorial AI's SFDC export guide is a practical reference because export mechanics often sit at the start of bigger reliability problems. The business side of those failures is covered well in this breakdown of poor data quality and business decisions.
Table of Contents
Why Your Decisions Are Only as Good as Your Data
A bad number rarely announces itself clearly. More often, it shows up as hesitation. Marketing sees a drop that sales can't explain. Finance asks why yesterday's totals changed this morning. Product notices a usage spike that disappears after a rerun. Nobody trusts the first answer, so everyone asks for a second extraction, a backfill, or a spreadsheet check.
That uncertainty costs more than the error itself. It slows approvals, delays launches, and teaches teams to keep shadow copies of “trusted” data outside the platform. Once that behavior starts, every metric becomes negotiable.
The stakes aren't limited to company reporting. A 2020 assessment of COVID-19 data from 202 countries revealed that approximately 69% of countries showed statistical deviations suggesting their data was not trustworthy, severely undermining global public health modeling and policy decisions. If national reporting during a global emergency can break down under pressure, it should be obvious that enterprise systems can too.
What business teams actually experience
Reliable data supports decision speed. Unreliable data creates a tax on every function.
Executives pause decisions: They ask for reconciliation instead of acting on the dashboard.
Analysts lose credibility: Even correct analysis gets challenged if the underlying inputs have failed before.
Engineers get pulled into triage: Instead of building, they spend time proving whether the data can be trusted.
Operators create workarounds: CSV exports, manual checks, and side spreadsheets fill the gap.
Practical rule: If a number can change a budget, a forecast, or a customer decision, it needs explicit reliability controls, not informal trust.
The key point is simple. The reliability of data isn't a reporting detail. It's an operational condition for sound decisions.
Defining Data Reliability Beyond the Buzzwords
A lot of teams say “data quality” when they really mean something narrower and more urgent. They mean, “Can we trust this dataset right now for this decision?” That's the working definition of data reliability.
A useful definition people can operate with
Think of reliable data the way you think about a reliable car. It starts when you need it. The fuel gauge is honest. The speedometer reflects reality. The GPS points you to the right place. You don't need to open the hood every morning to decide whether it's safe to drive.
Unreliable data is the opposite. The dashboard says one thing, the system behaves another way, and every trip begins with doubt. Maybe the data arrived late. Maybe records are missing. Maybe a field changed type and the transformation automatically cast values to null. The result is the same. People stop trusting the instrument panel.
In technical terms, reliability means the data is available when needed, stable enough to use repeatedly, and trustworthy under normal operating conditions. In business terms, it means leaders can act without launching an audit every time a number matters.
Reliability versus general data quality
Data quality is the broader umbrella. Reliability is the part that determines whether the data can support real work consistently.
That distinction matters because teams often invest in one-off cleanups while leaving the operating problem untouched. They fix duplicates in one table but ignore late-arriving files. They validate records but miss schema changes. They profile distributions monthly while dashboards go stale daily.
A practical way to separate the concepts is this:
Focus | Question |
|---|---|
Data quality | Is this data generally well-formed and fit for use? |
Data reliability | Will this data remain trustworthy when the business needs it? |
The hidden cost shows up in engineering capacity. Data quality failures in enterprise pipelines cause an average of 15% of total data engineering time to be spent on remediation, with 40% of critical dashboards experiencing staleness due to late or missing loads. Those aren't abstract platform issues. They are missed SLAs, delayed reporting, and teams doing repair work instead of delivering new capabilities.
Reliable data isn't “clean once.” It's consistently usable under production conditions.
If a team can't answer when data should arrive, what should be present, what values are valid, and whether structure changed, they don't have reliability. They have hope.
The Four Pillars of Measurable Data Reliability
The reliability of data becomes manageable when you stop treating it as a vague trust problem and break it into measurable pillars. Four matter in most production environments: Timeliness, Completeness, Accuracy, and Schema Stability.

Timeliness
Timeliness asks one question: did the data arrive when the business expected it?
A sales dashboard that updates after the revenue review is functionally wrong, even if every row is technically correct. The same goes for fraud signals, support queues, and supply chain feeds. Late data creates stale decisions.
In practice, teams measure timeliness through expected-arrival windows, freshness, and delay detection. If your upstream systems publish on schedules, monitor those schedules. If they don't, learn normal arrival patterns and alert when the pattern breaks.
For a deeper look at reliability indicators teams track, data quality metrics for freshness, distribution, and schema are the right place to start.
Completeness
Completeness is about presence. Are all required records, fields, and partitions there?
This pillar catches failures that look harmless at first. A missing region file can skew a company-wide KPI. A dropped set of event records can make retention appear weaker than it is. A null-filled customer identifier can break joins downstream while leaving pipeline jobs technically “successful.”
Completeness checks usually include row-count comparisons, required-field coverage, partition monitoring, and reconciliation between source and destination counts.
Accuracy
Accuracy asks whether the data reflects operational reality. In this context, teams validate values, distributions, and business logic.
A table can be fresh and complete and still be wrong. Price fields can be shifted by a transformation bug. Currency codes can be mapped incorrectly. Event timestamps can be parsed into the wrong timezone. In analytics, those mistakes distort trends. In operations, they create bad actions.
One useful companion concept here is redundancy. Not because copying data fixes quality by itself, but because fallback copies and replicated systems change how failures are absorbed. If you need a plain-language refresher, what is data redundancy explains the trade-offs well.
Later in the section, it helps to see the concept discussed visually.
Schema Stability
Schema stability is the most underestimated pillar. Teams often notice missing data quickly, but structural changes can go unnoticed until a downstream model, dashboard, or API starts behaving strangely.
A renamed column, a changed data type, or an added nested field can invalidate transformations without causing a hard failure. That's why schema monitoring needs to be explicit, not left to chance.
Why prioritization matters
Not every table deserves the same level of monitoring. Industry benchmarks indicate that approximately 20% of data tables typically generate 80% of all data quality issues, which is why targeted monitoring of freshness, volume, distribution, and schema on high-impact datasets usually works better than spreading effort evenly across everything.
Teams get more value by protecting the data that drives decisions than by trying to score every table in the warehouse at once.
A mature approach treats these four pillars as one operating system. Timeliness without accuracy is dangerous. Accuracy without completeness is misleading. Completeness without schema stability is fragile. Reliability requires the set.
How Good Data Goes Bad Common Failure Modes
Good data usually degrades in ordinary ways. A connector changes behavior. A producer adds a column. A file lands late. A business rule that used to hold no longer does. The pipeline may still run, but the trust is gone.

The quiet failures that do the most damage
The first class of failures is silent drift. This happens when distributions or relationships change gradually enough that nobody notices at first. A customer segment starts over-indexing. Sensor values shift range. Event frequencies move off historical norms. Because nothing “breaks,” drift often reaches business users before it reaches engineers.
The second class is lateness and missing loads. These are easy to understand and still hard to manage. A source system publishes late, a batch misses its window, or an orchestrator marks success while a downstream dependency hasn't materialized the expected data.
Then there are schema changes. These are especially dangerous because they can preserve pipeline uptime while corrupting meaning. A type coercion might turn valid values into nulls. A renamed field can reroute a transformation branch. The system stays green while the outputs rot.
Mapping failures to business impact
A useful way to diagnose failures is to tie them to the pillar they break and the business symptom they create.
Failure mode | Pillar affected | Business symptom |
|---|---|---|
Late upstream delivery | Timeliness | Dashboard is stale during a reporting deadline |
Dropped records or partitions | Completeness | KPI undercounts and false trend signals |
Invalid values and rule violations | Accuracy | Bad segmentation, pricing, or compliance outputs |
Unexpected column or type changes | Schema Stability | Broken transformations and misleading reports |
This isn't just an analytics problem. Silent data drift and unmonitored schema changes are responsible for 32% of AI model performance degradation in production systems, while 28% of analytics failures are traced to unvalidated record-level anomalies. If you run machine learning pipelines, feature reliability and schema tracking aren't optional safeguards. They are part of production engineering.
The most expensive data failures are often the ones that don't throw an obvious error.
The practical lesson is that isolated checks won't hold. A row-count alert won't catch drift. A schema diff won't catch invalid records. A single “quality score” won't tell an executive whether the metric is late, incomplete, or structurally changed. Teams need a joined-up view of how data fails, not a stack of disconnected warnings.
A Practical Playbook for Improving Data Trust
Teams require a repeatable operating routine more than another philosophical definition. The most effective pattern is a continuous cycle with three motions: Assess, Monitor, Remediate.

Assess
Start with business criticality, not technical elegance. Identify the datasets that directly drive revenue reporting, executive dashboards, operational workflows, regulated outputs, and model inputs. Those assets deserve explicit reliability definitions.
Write those definitions as measurable expectations. When should the data arrive? What records must be present? Which fields are mandatory? Which business rules must never be violated? If a producer changes structure, who gets notified and what downstream assets are at risk?
A practical assessment usually includes:
Decision mapping: List the reports, models, and processes that rely on each critical dataset.
Reliability expectations: Define freshness, arrival windows, required fields, and structural assumptions.
Ownership: Assign who investigates issues and who signs off on resolution.
Failure impact: Document what happens to the business if that dataset is wrong or late.
Monitor
Once expectations exist, automate against them. Manual checking doesn't scale and usually happens only after a stakeholder has already seen something suspicious.
Monitoring should cover the four pillars in different ways, because each fails differently:
For timeliness: Watch freshness, schedule adherence, and expected arrival times.
For completeness: Check row volumes, partition presence, and required field population.
For accuracy: Validate business rules and monitor distributions for unusual shifts.
For schema stability: Track added, removed, renamed, and type-modified columns.
This is also where representativeness matters. A dataset can be technically clean and still be unreliable for decision-making if it leaves out the people affected by the decision. The National Academies discussion of coverage and underrepresented groups makes the point clearly: reliability depends not only on correctness, but also on whether the data includes the right populations.
Remediate
Detection only matters if response is fast and disciplined. Teams that improve trust over time treat data incidents much like service incidents. They triage, contain, investigate, fix, and document what should prevent recurrence.
A simple remediation loop works well:
Triage the symptom: Is the issue late data, missing data, drift, invalid records, or a schema change?
Contain downstream impact: Pause a dashboard refresh, quarantine suspect records, or mark outputs as degraded.
Find the root cause: Check source extracts, transformations, contracts, and recent code or schema changes.
Fix and backfill: Restore the pipeline, correct the logic, and reprocess affected windows.
Harden the system: Add the missing check, alert, ownership rule, or communication path.
Good teams don't just fix bad data. They fix the condition that allowed bad data to reach decision-makers.
What works is operational discipline. What doesn't work is relying on heroics, ad hoc SQL, and the memory of whoever was on call last quarter.
Operationalizing Reliability with digna
A playbook becomes real when the controls live in one operating surface instead of a patchwork of scripts, dashboard warnings, and tribal knowledge. That's where a unified observability platform changes the day-to-day work.

What a unified platform changes
Separate tools tend to fragment the problem. One system watches pipelines. Another profiles tables. A third validates business rules. Someone still has to correlate the signals manually and explain them to analytics, engineering, and business stakeholders.
A unified approach puts timeliness, anomalies, validation, historical patterns, and schema monitoring in one place. That matters because business failures are rarely isolated to one metric. A stale dashboard may trace back to a late upstream arrival. A model issue may begin with drift and get amplified by a schema change. A governance incident may start as a record-level validation failure.
For teams evaluating that model, this overview of a user-friendly data quality platform for modern business is a useful reference point.
How the capabilities map to real problems
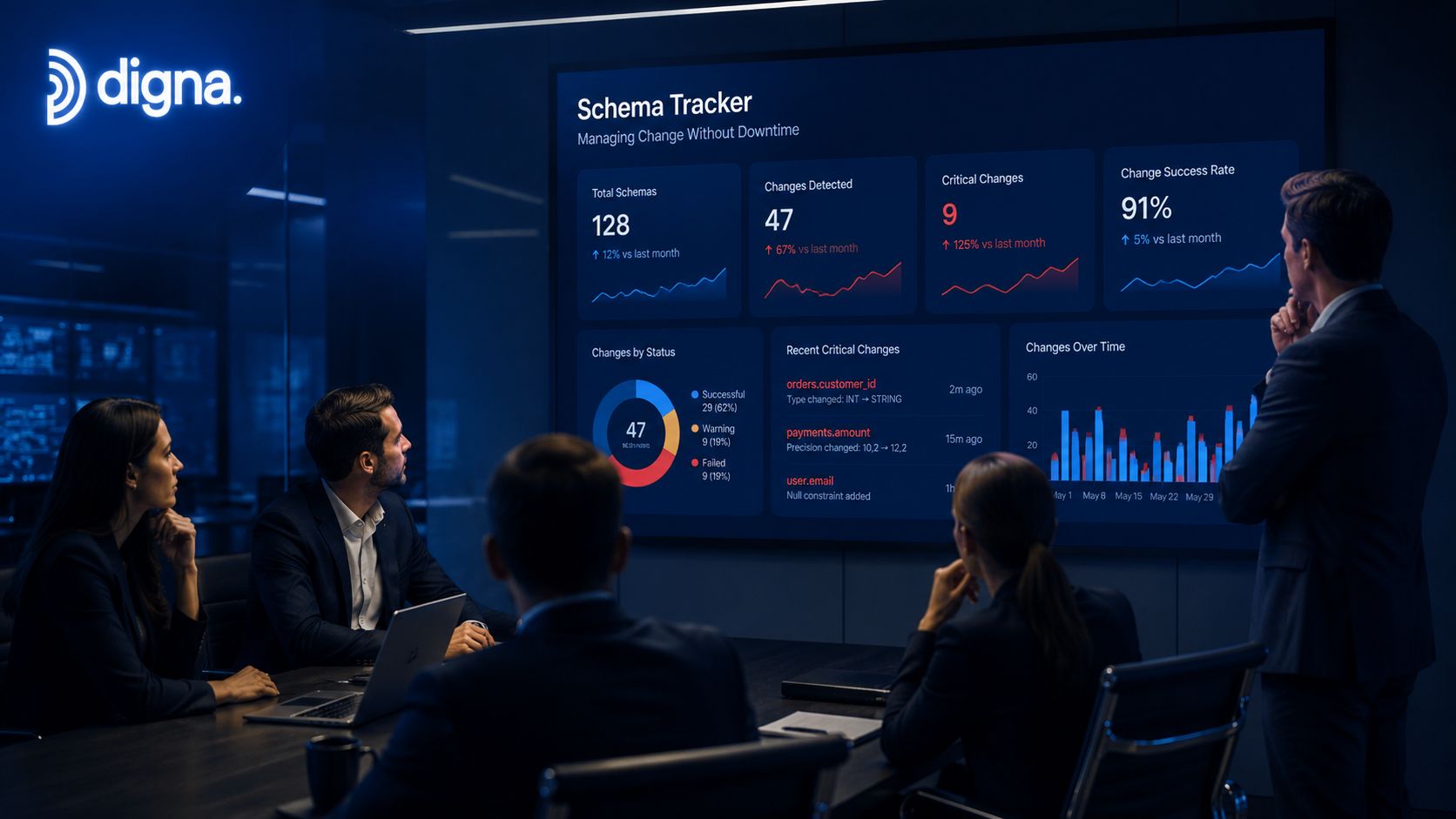
digna is one example of that unified model. Its components line up closely with the failure modes that matter operationally.
Timeliness monitoring: Expected-delivery calculations and delay detection address stale dashboards and late upstream loads.
Data anomalies: AI-based baseline learning surfaces silent drift and unusual changes without requiring constant manual rule maintenance.
Schema Tracker: Structural changes such as added or removed columns and data type modifications are flagged before they disrupt downstream assets.
Data Validation: Record-level checks enforce business logic and support audit-oriented controls.
Historical analytics: Trend views help teams distinguish a one-time anomaly from a recurring pattern.
The architecture matters too. In-database metric computation reduces data movement by up to 70% compared to external ETL-based validation, which supports a model where analyses run inside the customer's own database environment rather than copying production data out to a vendor system. In heavily regulated or privacy-sensitive settings, that changes both the security posture and the operational overhead.
Detection speed also changes when thresholds adapt. Organizations using AI-powered anomaly detection with self-adjusting thresholds detect data deviations 4.5 times faster than those relying on static rule-based systems, with early warnings issued within 12 minutes of deviation onset. That matters because the difference between a contained issue and a visible business incident is often whether the team saw the problem before the dashboard refresh, the executive review, or the model scoring run.
A reliable data operation needs fewer disconnected checks and more connected evidence.
The practical benefit isn't just better alerting. It's shared context. Engineers, analysts, and business stakeholders can inspect the same incident through different lenses without debating which tool tells the truth.
From Unreliable Data to Confident Decisions
The reliability of data isn't a one-time cleanup. It's an operating discipline. Teams earn trust when they define measurable expectations, monitor the pillars that are important, and respond to failures with clear ownership and root-cause correction.
Reliable systems don't eliminate every incident. They make incidents visible early, understandable quickly, and recoverable without turning every decision into a debate. That's the shift that matters most. Data stops being a source of hesitation and becomes something the business can use with confidence.
If your team is dealing with stale dashboards, silent drift, schema surprises, or constant data firefighting, digna is worth evaluating as a practical way to monitor timeliness, anomalies, validation, and schema changes in one environment while keeping data inside customer-controlled infrastructure.



