Arquitectura de canalización de datos: una guía completa para 2026
|
0
minuto de lectura

El informe se veía bien a las 8:00 a.m. Para las 9:15, el departamento de finanzas ya lo había utilizado en una reunión. Para la hora del almuerzo, alguien notó que los totales no cuadraban, no porque el SQL estuviera mal, sino porque una tabla ascendente había dejado de recibir un subconjunto de registros durante la noche. No se activó ninguna alerta. Técnicamente, la canalización "funcionó". El panel de control ofreció una confianza desactualizada.
Ese es el modo de fallo con el que muchas organizaciones están lidiando en este momento. No apagones dramáticos. Corrupción silenciosa. Un archivo perdido, un cambio de esquema, una transformación que aún se ejecuta pero que ahora asigna el campo incorrecto, una entrada que llega tarde y convierte un KPI fresco en la respuesta de ayer. Una vez que eso sucede, la confianza cae más rápido de lo que cualquier métrica del sistema te dirá.
Una arquitectura sólida de canalización de datos soluciona más que el movimiento del origen al destino. Decide si los operadores confían en su plataforma de datos bajo presión, si los analistas pueden explicar los números sin adivinanzas y si las entradas del modelo se mantienen estables a medida que evolucionan los sistemas de origen. La parte más difícil no es dibujar cajas. Es diseñar la canalización para que la calidad, la puntualidad y la visibilidad existan desde el primer diagrama, no después de la primera escalada ejecutiva.
Los equipos que trabajan con entradas mixtas enfrentan esto de manera aún más aguda cuando los documentos semiestructurados entran en el flujo. Si su canalización incluye la extracción de documentos para casos de uso de IA, vale la pena revisar esta guía práctica para convertir PDFs para LLMs, ya que los errores de estructura de documentos a menudo comienzan mucho antes de que lo haga el modelado. Para obtener una línea base visual de cómo encajan estos sistemas, un diagrama simple de arquitectura de datos ayuda a alinear la conversación antes de tocar las herramientas.
Tabla de Contenidos
Su Guía para la Arquitectura Moderna de Canalización de Datos
Integrando la Calidad de Datos y la Observability por Diseño
Una Lista de Verificación Práctica para su Próxima Canalización
Su Guía para la Arquitectura Moderna de Canalización de Datos
Una definición útil de la arquitectura de canalización de datos es simple: es el plano operativo de cómo se recopilan, cambian, almacenan y entregan los datos sin perder su significado en el camino. Eso suena sencillo hasta que hereda un sistema donde la ingesta, las transformaciones, los programas, el almacenamiento y los paneles de control fueron construidos en diferentes momentos por diferentes equipos.
En la práctica, la arquitectura se manifiesta en los patrones de fallo. Un diseño rígido hace que los equipos tengan miedo de cambiar cualquier cosa. Una transferencia débil entre la ingesta y la transformación permite que los registros mal formados se muevan hacia el final de la cadena. Una capa de informes sin expectativas de frescura acostumbra al negocio a descubrir los problemas de forma manual. Nada de eso se soluciona agregando un orquestador más o un panel de control adicional.
La arquitectura también tiene que reflejar cómo trabaja realmente la gente. Los analistas quieren tablas estables. Los equipos de plataforma quieren despliegues repetibles. Los ingenieros de ML quieren entradas que no se desvíen sin ser notadas. Los equipos de seguridad quieren que los datos permanezcan dentro de entornos controlados. Un plano de diseño moderno tiene que satisfacer a todos ellos sin convertirse en un laberinto.
Las canalizaciones confiables no son las que nunca fallan. Son las que fallan de maneras que los operadores pueden ver, aislar y solucionar rápidamente.
Es por eso que los mejores diseños tratan la canalización menos como plomería y más como un sistema de producción. Cada etapa tiene un propietario. Cada dependencia es visible. Cada ruta de entrega tiene una expectativa de puntualidad y corrección. Si construye con esas premisas, el resto de las decisiones se vuelven mucho más claras.
Los Cuatro Pilares de una Canalización de Datos
La forma más fácil de enseñar el diseño de canalizaciones es tomar prestada una analogía de cocina. Los ingredientes llegan de los proveedores, se almacenan de forma segura, los preparan los cocineros y finalmente se sirven a los comensales. Si algún paso falla, al cliente no le importa qué estación falló. Solo sabe que la comida llega tarde o está mal.

Pense como una línea de operaciones
La versión técnica tiene cuatro pilares prácticos:
Ingesta extrae datos de los sistemas de origen. Eso puede significar APIs, bases de datos transaccionales, herramientas SaaS, flujos de eventos o entregas de archivos.
Almacenamiento guarda los datos sin procesar o preparados en algún lugar duradero, a menudo en plataformas como Amazon S3, Snowflake o Databricks.
Procesamiento transforma los datos en algo utilizable. Implica limpieza, deduplicación, filtrado, formateo y uniones.
Servicio expone el resultado a paneles de control, herramientas de ETL inverso, modelos, aplicaciones o consumidores intermedios.
Uno de los resúmenes modernos más claros proviene de la explicación de Striim sobre los componentes modernos de la canalización de datos, que describe el núcleo como ingesta, transformación y almacenamiento, y señala que los fallos en la transformación conducen directamente a informes desactualizados y paneles de control dañados cuando los datos mal formados llegan a la capa de consumo. Yo sigo separando el servicio como una preocupación arquitectónica propia porque muchos equipos construyen la canalización pero no planifican adecuadamente la transferencia a las personas y sistemas que la consumen.
Dónde suelen equivocarse los equipos
Los errores rara vez ocurren en los extremos. Suceden en las transiciones.
Algunos ejemplos aparecen constantemente:
Los datos sin procesar llegan sin controles de contrato. La canalización acepta registros, pero nadie verifica si faltan campos clave o si contienen tipos incorrectos.
El almacenamiento se convierte en un vertedero. Los equipos guardan cada versión de todo, pero no distinguen entre zonas de aterrizaje, curadas y listas para el consumidor.
Las transformaciones se convierten en un monolito. Un solo trabajo enorme maneja toda la lógica, por lo que depurar una sola métrica significa leer todo el entorno.
El servicio se trata como "solo BI". En realidad, la consistencia semántica, las expectativas de frescura y los patrones de acceso pertenecen aquí.
Regla práctica: Si un consumidor no puede responder de dónde proviene un número, su capa de servicio no está terminada.
Una buena arquitectura mantiene cada pilar lo suficientemente distinto como para operar de forma independiente, pero lo suficientemente conectado como para que los fallos no se oculten entre ellos. Esa separación es lo que hace que las decisiones posteriores sobre patrones, resiliencia y observability sean manejables en lugar de caóticas.
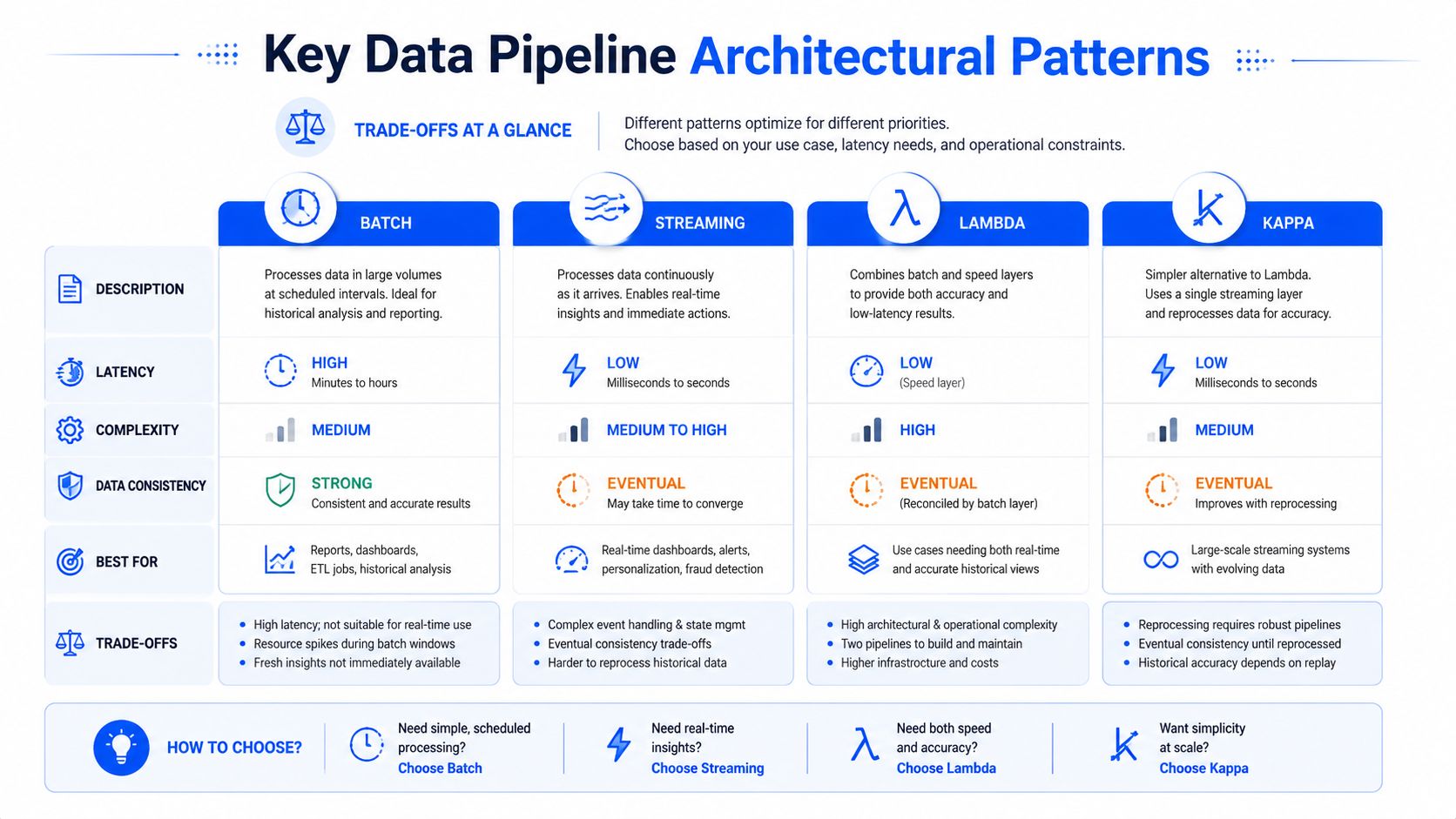
Patrones Arquitectónicos Clave de Canalización de Datos
Los patrones arquitectónicos son el lugar donde los equipos cometen errores costosos porque cada opción funciona bien para algo. La elección incorrecta rara vez es "tecnología mala". Es un desajuste entre las necesidades de latencia, la complejidad operativa y el tipo de análisis que requiere el negocio.
ETL y ELT resuelven problemas diferentes
ETL se adapta a entornos donde la transformación debe ocurrir antes de que los datos aterricen en el destino. Esto es común cuando la limpieza de origen es estricta, la capacidad de cómputo del destino es limitada o el manejo regulatorio requiere controles previos a la carga.
ELT funciona mejor cuando la plataforma de destino está diseñada para un procesamiento pesado y los equipos quieren flexibilidad después de la carga. Los almacenes y lagos de datos hicieron que este patrón fuera mucho más práctico porque se pueden cargar datos rápidamente y darles forma más tarde con transformaciones basadas en SQL.
Ningún patrón es universalmente superior. ETL ofrece un control previo a la ingesta más estricto. ELT brinda más agilidad para los equipos de análisis. Si está evaluando herramientas para la parte inicial de la canalización, este resumen de software de ingesta de datos es un lugar útil para comparar cómo las decisiones de captura de origen afectan al resto de la infraestructura.
Procesamiento por lotes, transmisión, lambda y kappa
El procesamiento por lotes y la transmisión son una bifurcación de mayor consecuencia.
El lote es la mejor opción cuando el negocio puede tolerar entregas programadas y la canalización debe procesar grandes conjuntos históricos de manera consistente. Los informes financieros de fin de día son un caso clásico. La transmisión es para situaciones en las que la tardanza debilita el caso de uso en sí, como el monitoreo operativo, las alertas o los flujos de trabajo basados en eventos.
Las formas híbridas son importantes cuando se necesitan ambas. El artículo de Striim sobre patrones de arquitectura Lambda y Kappa plasma muy bien la distinción. La arquitectura Lambda equilibra la velocidad en tiempo real con la confiabilidad de los lotes mediante la ejecución de flujos de datos paralelos. Una ruta rápida maneja la transmisión en tiempo real, una ruta lenta maneja el procesamiento histórico y una capa de servicio unifica los resultados. La arquitectura Kappa elimina la capa de lote separada y maneja tanto el procesamiento en tiempo real como el histórico a través de una única canalización de transmisión, lo que simplifica las operaciones al eliminar los sistemas duales.
Esa simplificación es atractiva, pero Kappa conlleva un compromiso real. Reprocesar el historial de transmisión a través de una sola canalización es elegante solo si sus herramientas, estrategia de retención y disciplina operativa son lo suficientemente fuertes como para admitir la reproducción de forma segura.
Comparación de Patrones de Canalización de Datos
Patrón | Caso de Uso Principal | Ventajas | Desventajas |
|---|---|---|---|
Lote | Análisis programados e informes recurrentes | Predecible, ideal para grandes trabajos históricos, más fácil de comprender | Mayor latencia, menos adecuado para respuestas operativas |
Transmisión | Casos de uso basados en eventos y visibilidad casi en tiempo real | Baja latencia, fuerte para alertas y operaciones en vivo | Manejo de errores, reproducción y gestión de estado más difíciles |
Lambda | Equipos que necesitan profundidad histórica y conocimiento inmediato a la vez | Cubre juntos la confiabilidad de lotes y la velocidad en tiempo real | Dos rutas para construir, probar y mantener |
Kappa | Entornos centrados en transmisión que quieren un único modelo de procesamiento | Modelo operativo más simple que los sistemas de ruta dual | La estrategia de reproducción y la disciplina de transmisión se vuelven críticas |
Un banco podría usar lotes para informes regulatorios, transmisión para señales de fraude y un patrón híbrido donde la actividad del cliente requiere una reacción inmediata pero también una conciliación histórica. Ese es el punto. Elija el patrón que coincida con el margen de decisión, no el que parezca más moderno en una diapositiva.
Construyendo Canalizaciones que No se Rompan
Las canalizaciones que causan más dolores de cabeza suelen ser las que "funcionaban bien" hasta que el negocio cambió. Llega una nueva fuente. Se cambia el nombre de un campo. Un equipo agrega lógica para un panel de control, otro agrega funciones de ML y de repente un fallo tumba tres salidas no relacionadas porque todo vive dentro de la misma cadena rígida.

La modularidad es un rasgo de supervivencia
El diseño modular no es una cuestión de estilo. Es lo que evita que un cambio se convierta en un apagón.
El análisis de Monte Carlo sobre arquitectura de canalización modular y automatizada señala directamente el punto clave: las canalizaciones confiables deben ser modulares y automatizadas, y los diseños no modulares crean cambios disruptivos que paralizan a los equipos a la hora de modificarlas. Esa descripción es dolorosamente precisa. Una vez que la gente tiene miedo de cambiar una canalización, la calidad comienza a degradarse porque los problemas conocidos permanecen en su lugar más tiempo del debido.
Una estructura modular práctica suele incluir:
Unidades de ingesta alineadas con el origen que pueden fallar o reproducirse de forma independiente.
Capas de transformación con contratos claros para que la lógica de preparación, la lógica de conformidad y la lógica de negocio no se unifiquen en un solo paso.
Controles de calidad reutilizables que se mueven con el módulo en lugar de vivir en una hoja de cálculo separada.
Automatización del despliegue para que los lanzamientos sean repetibles y revertirlos no sea una tarea heroica.
Pruebas de linaje y ejecución paralela
El siguiente punto de fallo es la ceguera de dependencia. Los equipos creen saber qué consume una tabla hasta que desactivan una columna y rompen una métrica que nadie recordaba que existía.
El linaje automatizado soluciona eso. El seguimiento humano no sobrevive a la complejidad, especialmente cuando entran en juego múltiples herramientas de orquestación, almacenes de datos y capas de servicio. Cuando una canalización falla o un esquema cambia, el linaje reduce el análisis de causa raíz de una adivinanza a una búsqueda delimitada.
Aquí está la secuencia operativa que recomiendo antes de considerar que una canalización está lista para producción:
Aísle los componentes para que un cambio no requiera una reestructuración completa.
Escriba expectativas de interfaz para cada transferencia, incluyendo esquema y puntualidad.
Pruebe los módulos y las rutas completas porque una prueba unitaria limpia no detectará suposiciones erróneas entre etapas.
A continuación se incluye una guía útil sobre prácticas de canalización resilientes.
Y un punto más que se pasa por alto a menudo: la ejecución paralela no es una optimización que se añade más tarde. Para las cargas de trabajo modernas, pertenece al diseño desde el principio. Cuando las tareas independientes pueden ejecutarse de forma concurrente, se reducen los cuellos de botella y se preservan los márgenes de entrega a medida que crece el volumen de datos. Si no planifica eso de antemano, cada aumento en la actividad de origen se convertirá en un problema de programación.
Construya la canalización de manera que un equipo pueda cambiar un componente sin pedir permiso a otros cinco equipos.
Asegurando las Canalizaciones de Datos en su Entorno
La arquitectura de seguridad comienza con una pregunta directa: ¿dónde residen los datos mientras se ejecuta la canalización? Muchos equipos se centran en el cifrado y el control de acceso pero ignoran el movimiento de datos. Eso es un error, especialmente en finanzas, salud, telecomunicaciones y sector público, donde las rutas de residencia y exposición importan tanto como la lógica de transformación.
La residencia de datos cambia el diseño
Los despliegues locales y de nube privada obligan a una mejor disciplina arquitectónica porque no permiten pasar por alto a dónde van los datos sensibles. Si una canalización copia datos de producción en zonas de preparación no gestionadas, amplía el acceso durante la transformación o envía cargas de datos a servicios externos para controles de calidad, ha aumentado la superficie de ataque incluso antes de que los datos lleguen a la analítica.
Mantener la ejecución dentro del entorno controlado por el cliente cambia esa postura. Reduce el movimiento innecesario, limita quién puede acceder a los datos de producción y hace que las conversaciones de auditoría sean mucho más sencillas. Esto es sumamente importante cuando los datos regulados deben permanecer residentes en un entorno específico o cuando las políticas internas prohíben el acceso de proveedores a conjuntos de datos activos.
Controles de seguridad que pertenecen al plano de diseño
Una arquitectura de canalización de datos segura suele tener algunas características en común:
Cifrado en tránsito y en reposo para que la extracción, transferencia y almacenamiento no creen puntos de exposición en texto plano.
Acceso basado en roles que separa a los operadores de canalizaciones, desarrolladores, analistas y usuarios de negocio.
Segmentación de entornos para que desarrollo, pruebas y producción no se mezclen.
Rutas de validación audtables para reglas de negocio que tengan implicaciones de Compliance.
Diseño de copia mínima para que la arquitectura evite crear conjuntos duplicados de datos sensibles solo para monitorearlos.
La seguridad también se cruza con las expectativas de entrega. Si su arquitectura incluye SLAs para puntualidad y detección de retrasos, los operadores pueden investigar tardanzas anormales tanto como un problema de confiabilidad como una señal potencial de seguridad. Un flujo de datos que se detiene inesperadamente puede ser un problema de origen o también un problema de credenciales, políticas o conectividad que merece atención inmediata.
Los diseños más sólidos tratan el Compliance como una propiedad arquitectónica, no como un ejercicio de documentación. Si necesita calidad de datos, detección de anomalías y seguimiento de esquemas, diseñe esos controles para que se ejecuten donde ya residen los datos. Eso suele ser más seguro, más fácil de gobernar y más fácil de defender en una revisión.
Integrando la Calidad de Datos y la Observability por Diseño
Muchas organizaciones creen que tienen observability cuando en realidad lo que tienen es monitoreo del destino. Saben si la tabla del almacén existe o si el trabajo de BI finalizó. No saben si los datos entraron a la canalización en un estado saludable, si cambiaron de forma de manera peligrosa o si llegaron lo suficientemente tarde como para hacer que el informe sea engañoso.

La Observability comienza en la ingesta
Esa brecha es precisamente la razón por la que la observability debe integrarse en la propia arquitectura. La discusión de Alation sobre patrones de arquitectura de canalización de datos y observability hace una distinción importante: la validación de calidad pertenece al punto de entrada, no solo después del procesamiento. Si espera hasta los controles del destino, la desviación silenciosa, los cambios de esquema y los valores faltantes ya se habrán propagado a lo largo del flujo.
La presión del mercado y la realidad operativa coinciden. El mercado de herramientas de canalización de datos está valorado en $14.76 mil millones con una CAGR del 26.8%, y la misma fuente señala que las canalizaciones modernas pueden procesar más de 800 millones de registros al día. A esa escala, una capa de observability con métricas como registros procesados por segundo y tasas de error por etapa no es un lujo. Es control operativo básico.
Por qué la detección aprendida supera a las reglas rígidas
Los controles basados en reglas siguen importando, especialmente para restricciones de negocio explícitas. Pero se desmoronan cuando el problema es de comportamiento más que binario.
La detección de anomalías se adapta mejor a esa tarea porque puede aprender patrones esperados y marcar anomalías sin un mantenimiento manual constante de umbriles. FirstEigen explica la detección de anomalías impulsada por IA en flujos de datos como un proceso para establecer líneas base para datos de alta calidad y luego resaltar desviaciones sospechosas para su revisión. La descripción general de Oracle sobre métodos estadísticos y neuronales para la detección de anomalías aporta una profundidad útil aquí. Las agrupaciones, los métodos basados en densidad como LOF y los autoencoders ayudan a detectar anomalías locales y sutiles que las pruebas más sencillas pasan por alto.
Para los equipos que manejan canalizaciones con gran volumen de documentos, se aplica el mismo principio a nivel de campo. Esta guía de validación de datos para facturas y órdenes de compra es un buen recordatorio de que la validación no se trata solo de esquemas. También se trata de imponer reglas a nivel de registro antes de que valores erróneos se extiendan a la lógica posterior.
Un dato erróneo detectado en la ingesta es un incidente evitado. Un dato erróneo detectado en un panel de control es un problema de confianza.
Qué instrumentar desde el primer día
Un diseño de observability nativo debería monitorear al menos cuatro dimensiones:
Puntualidad rastrea cuándo se esperan los datos y si los patrones de llegada cambian.
Volumen detecta caídas repentinas, picos o cambios inusuales en la distribución.
Esquema alerta sobre columnas añadidas, eliminadas y cambios de tipo antes de que las transformaciones se rompan sin que nadie lo note.
Validación impone reglas de negocio a nivel de registro donde la exactitud debe ser explícita.
Si la canalización maneja datos secuenciales o basados en eventos, los patrones de tiempo merecen una atención especial. La explicación de Nile Secure sobre preprocesamiento de datos y detección de anomalías basada en el tiempo destaca el papel del preprocesamiento, la ingeniería de características y los modelos adecuados para el comportamiento secuencial como las LSTM. Eso es importante porque muchos "fallos de canalización" son en realidad fallos de puntualidad: los datos llegan, pero no cuando el negocio los necesita.
Un modelo mental útil es este: el monitoreo le indica que un trabajo se ejecutó. La observability le indica si los datos siguieron siendo confiables mientras se ejecutaba. Para una comparación fundamentada de estas responsabilidades, vale la pena tener a mano este desglose de observability de datos frente a calidad de datos al diseñar la capa de control.
Una Lista de Verificación Práctica para su Próxima Canalización
La forma más rápida de mejorar la revisión de una canalización es dejar de preguntar si el sistema funciona y comenzar a preguntar bajo qué condiciones deja de ser confiable.

Utilice esta lista de verificación antes de dar luz verde a un nuevo diseño o de auditar uno existente:
Defina contratos de origen de manera temprana. ¿Conoce la estructura, propiedad, patrón de actualización y modos de fallo de cada origen?
Elija el patrón según las necesidades de decisión. ¿Este caso de uso es por lotes, transmisión o híbrido en función de la rapidez con la que alguien deba actuar sobre los datos?
Separe las capas de datos sin procesar, transformados y de servicio. ¿Puede reproducir la ingesta sin tener que reconstruir la lógica de negocio desde cero?
Diseñe módulos, no monstruos. ¿Puede un equipo cambiar un componente sin poner en riesgo a consumidores no relacionados?
Mapee el linaje automáticamente. Si un esquema cambia hoy, ¿puede identificar rápidamente las tablas, paneles y modelos afectados?
Planifique la ejecución paralela. ¿Se mantendrá el rendimiento cuando aumenten las fuentes de datos o se superpongan las ventanas de actualización?
Establezca expectativas de puntualidad. ¿Existe un SLA claro o una expectativa operativa de cuándo deben llegar los datos y cuándo un retraso se convierte en incidente?
Integre la validación y la observability desde el primer lanzamiento. ¿Son los controles de frescura, volumen, esquema y nivel de registro parte directa de la arquitectura y no añadidos posteriores?
Mantenga los datos sensibles residentes cuando sea posible. ¿Su diseño minimiza las copias y restringe el acceso durante el monitoreo y la transformación?
Documente las transferencias de datos. ¿Puede un nuevo líder de equipo entender fácilmente qué entra, qué cambia, qué se almacena y quién lo consume?
Una buena canalización no es la más sofisticada. Es la que su equipo puede cambiar de forma segura, monitorear con claridad y en la que puede confiar bajo presión.
Si su equipo desea estos controles sin mover los datos de producción fuera de su entorno, vale la pena analizar de cerca a digna. Combina la calidad de los datos y la observability en una sola plataforma, se ejecuta dentro de entornos locales o de nube privada controlados por el cliente, y ayuda a los equipos a detectar anomalías, cambios de esquema, problemas de puntualidad y fallas de validación a nivel de registro antes de que se conviertan en informes desactualizados o sistemas posteriores dañados.



