Data Ingestion Software: Choosing the Right Tool for 2026
|
7
min read

If you're dealing with data from Salesforce, product databases, support platforms, IoT devices, and event streams all at once, you already know the problem isn't collecting data. It's getting the right data to the right place, in a form downstream systems can trust. Organizations often don't fail because they lack dashboards or models. They fail because the plumbing underneath is brittle, delayed, or opaque.
That's where data ingestion software stops being a background utility and becomes part of your core platform design. The way you ingest data affects report freshness, model inputs, incident response, compliance posture, and whether anyone trusts the numbers in a board deck. Move data badly and every downstream layer inherits that instability. Move it well and the rest of the stack gets simpler.
Table of Contents
The Foundation of Modern Data Analytics
A common enterprise setup looks deceptively mature. Every team has a system they rely on. Finance lives in one platform, operations in another, customer support in a third, and engineering produces a constant stream of application events. Yet analytics still stalls because the data arrives late, lands in inconsistent formats, or never reaches the warehouse cleanly enough to use.
Data ingestion software is the layer that imposes order on that mess. It functions as the logistics network for a data factory. Raw materials arrive from many origins, each with different packaging, timing, and handling requirements. Ingestion software collects them, routes them, and delivers them to warehouses, lakes, or operational stores where analysts, BI tools, and ML systems can work with them.

Why ingestion sits at the center
The mistake I see most often is treating ingestion as a one-time integration task. It isn't. It's a continuous operational system with failure modes. APIs change. Source schemas drift. Event volume spikes. Access policies tighten. A pipeline that worked perfectly during a proof of concept can gradually become the least reliable part of the platform once production traffic and organizational complexity show up.
That matters because downstream systems are unforgiving. A late load can make a finance dashboard stale. An unnoticed dropped column can break a transformation model. A malformed event can pollute features used by a recommendation service. Teams often investigate those issues at the reporting or model layer first, even though the actual fault started at ingestion.
Practical rule: If the first mile of data movement is unstable, every later control becomes more expensive.
Why teams are investing now
The market direction reflects that shift in thinking. The global data integration software market, which includes ingestion solutions, is projected to grow from USD 6.8 billion in 2026 to USD 16.1 billion by 2033, with a 13.1% CAGR, according to Persistence Market Research on the data integration software market. That isn't just tool churn. It's a signal that organizations are redesigning how data moves across multi-cloud systems, data lakes, and analytics programs.
In practice, the business case is straightforward:
Faster access to usable data means analysts spend less time waiting and more time shipping decisions.
More reliable movement between systems reduces firefighting in engineering and analytics.
Cleaner handoffs to downstream platforms make quality and observability easier to enforce.
Lower operational drag helps teams scale integrations without turning every new source into a custom project.
Data ingestion software isn't the whole platform. But it's the foundation every reliable data product stands on.
Batch Streaming and Hybrid Ingestion Architectures
Architecture choice decides how your data arrives, how much operational overhead you take on, and what kinds of downstream guarantees you can make. Most ingestion designs land in one of three buckets: batch, streaming, or hybrid.
Batch ingestion
Batch ingestion is the scheduled mail truck. It shows up at known times, collects a lot of material, and drops it off in bulk. That's still the right model for many warehouse loads, ERP extracts, historical backfills, and systems where source APIs have strict limits or limited event support.
Batch designs are easier to reason about. They create natural recovery boundaries, and they work well when consumers care more about completeness than immediacy. If you're refreshing finance, procurement, or monthly planning datasets, predictable bulk movement is often a feature, not a compromise.
What doesn't work is forcing batch into use cases that require immediate reaction. If fraud logic, customer notifications, or operational alerting depend on minute-level freshness, an overnight or hourly truck is the wrong vehicle.
Streaming ingestion
Streaming ingestion is the water pipe. Data keeps flowing, and downstream systems can consume it almost immediately. That gives teams better freshness, but it also raises the engineering bar. Continuous pipelines need stronger thinking around ordering, retry behavior, backpressure, idempotency, and schema evolution.
Modern tools increasingly rely on change data capture, or CDC, to make this practical. CDC-based ingestion can reduce latency from hours to milliseconds, and tools such as Fivetran and Estuary Flow sync only changed data instead of full extracts, which can cut API load by up to 90%, according to Valiotti's overview of data ingestion tools. That matters when you're ingesting from SaaS platforms with rate limits or source systems that can't tolerate heavy polling.
Streaming is powerful, but it isn't free. Teams often underestimate the operational work required to keep a fast pipe healthy once upstream contracts start changing.
Hybrid ingestion
Hybrid ingestion combines both models. It uses a fast path for recent changes and a bulk path for completeness and reconciliation. If batch is the mail truck and streaming is the water pipe, hybrid is the facility that uses both because each solves a different problem.
This pattern is common in large platforms because it maps better to reality. Business users want fresh numbers quickly, but data teams also need a reliable historical layer they can reconcile, replay, and audit. Hybrid designs are especially useful when streaming captures immediate changes while batch jobs correct late-arriving records, rebuild partitions, or validate long-range consistency.
Use hybrid when freshness matters, but trust still depends on periodic reconciliation.
Data Ingestion Architectures Compared
Characteristic | Batch Ingestion | Streaming Ingestion | Hybrid Ingestion |
|---|---|---|---|
Delivery pattern | Scheduled bulk loads | Continuous event or CDC flow | Continuous flow plus scheduled reconciliation |
Best fit | Historical analytics, warehouse refreshes, backfills | Alerts, operational systems, low-latency analytics | Mixed environments with both real-time and historical needs |
Latency profile | Higher latency by design | Very low latency when engineered well | Low latency for recent data, stronger completeness over time |
Operational complexity | Lower | Higher | Highest |
Recovery model | Easier to rerun in chunks | Requires careful replay and state handling | Flexible, but more moving parts |
Cost shape | Predictable compute windows | Ongoing processing overhead | Broader spend across both modes |
Schema change handling | Often caught at load time | Must be handled continuously | Needs both fast-path resilience and batch verification |
Common failure mode | Stale data | Silent drift or event handling issues | Coordination gaps between fast and slow paths |
A lot of teams choose architecture by habit. That's a mistake. Choose it based on consumer expectations, source behavior, recovery needs, and the quality guarantees you must uphold after data lands.
Evaluating Data Ingestion Software Features
Most vendor demos make every platform look interchangeable. They aren't. When you're evaluating data ingestion software, the useful question isn't "Can it connect to my systems?" It's "Can it keep those connections reliable when production gets messy?"

Connector depth matters more than connector count
A long connector catalog looks good on a pricing page. In practice, depth matters more than breadth. A good connector handles authentication changes, pagination quirks, evolving fields, and incremental syncs without forcing your team into constant patchwork.
Ask questions like these during evaluation:
How does the connector handle schema change? You want more than a warning email. You want predictable behavior when columns appear, disappear, or change type.
Does it support incremental extraction cleanly? Full reloads are expensive and often unnecessary.
What breaks when the source API changes? Mature products make this survivable.
Can you extend connectors for internal systems? Most enterprises have at least one source no vendor supports out of the box.
If your roadmap includes unstructured documents, PDFs, forms, or semi-structured business content, it's also worth reviewing tools outside traditional SaaS sync products. An AI-powered data extraction engine can be useful when ingestion starts with raw documents rather than clean tables or APIs.
What good processing looks like
In-flight processing should be flexible without turning the ingestion layer into an uncontrolled transformation jungle. The strongest setups usually apply lightweight transformations during ingestion, then leave heavier business logic for warehouse-native modeling.
Look for these capabilities:
Filtering and selection so you don't move irrelevant records just because a source exposes them.
Schema mapping that supports controlled alignment into destination models.
Masking or field-level protection when sensitive values shouldn't move in raw form.
Support for both ETL and ELT patterns because different sources and compliance needs call for different approaches.
If your platform strategy includes a broader reliability layer, make sure the ingestion tool can connect cleanly to the rest of your ecosystem. Teams often underestimate the value of straightforward data platform integrations until they start wiring monitoring, warehouse workflows, and downstream controls together.
Performance and operational fit
Performance claims are easy to inflate, so anchor your evaluation in concrete operational metrics. Benchmarks for ingestion speed typically measure throughput, latency, and resource efficiency. In high-throughput pipelines, Apache Kafka has been cited at 1M+ messages/sec with sub-10ms end-to-end latency under typical enterprise loads in Improvado's overview of ingestion tooling and benchmarks. Even if you never run Kafka directly, those are the categories your vendor should be able to discuss clearly.
The right performance question isn't "How fast is it?" It's "How fast is it under my failure modes, my schema churn, and my recovery windows?"
A practical checklist for vendor review:
Measure steady-state behavior. Ask how the tool behaves during normal daily load, not just synthetic peak demos.
Probe degraded conditions. What happens during retries, source throttling, or partial destination outages?
Inspect resource efficiency. Low-latency movement that burns excessive compute isn't a win.
Test replay and backfill. Many tools look great on day one and painful on day one hundred, when you need to rerun history.
Check monitoring hooks. If the platform can't surface lag, failure states, and schema events cleanly, operations will suffer.
Good data ingestion software doesn't just move data fast. It behaves predictably when data contracts, source systems, and business expectations all change at once.
Securing Ingestion Pipelines On-Prem and in the Cloud
Security failures in ingestion pipelines are rarely dramatic at first. They usually show up as over-permissioned service accounts, copied raw data in the wrong environment, or sensitive fields landing somewhere they never should have been. Because ingestion sits at the boundary between systems, it's one of the first places to tighten.

Deployment model is a security decision
The first question is where the software runs. SaaS ingestion platforms offer speed and convenience, especially for common cloud sources. Private cloud gives you more control over network boundaries and operational policies. On-prem deployments still matter when residency, internal access rules, or regulated environments limit what can leave your estate.
That trade-off isn't only about comfort with cloud. It's about who controls execution, where credentials live, how logs are stored, and whether raw datasets cross vendor-managed infrastructure. In finance, healthcare, telecom, and public sector environments, these questions often decide the shortlist before feature comparisons even begin.
A practical way to frame it:
SaaS fits teams that prioritize rapid rollout and broad managed connectivity.
Private cloud works when you need managed patterns with stronger environmental control.
On-prem suits organizations that can't accept vendor-side data access or externalized processing for critical datasets.
If your team needs outside support while tightening the surrounding security posture, a provider with experience in operational hardening can help. Resources like REDCHIP IT Solutions cyber security are useful when ingestion security has to be aligned with broader infrastructure controls rather than treated as a standalone tool setting.
Security controls that should be non-negotiable
Deployment is only half the story. The software also needs strong controls over how data moves and who can touch it.
The baseline list is short, but serious:
Encryption in transit and at rest so data isn't exposed while moving or sitting in intermediate storage.
Role-based access control to limit who can configure connectors, view payloads, or trigger replays.
Credential isolation and rotation support because long-lived secrets become operational debt.
Data masking and selective field handling for sensitive elements that don't need to travel in raw form.
Logging and auditability so teams can investigate changes, failures, and access events.
Network and deployment controls that match the rest of your platform standards.
One more artifact is worth sharing with engineering and security together:
Security reviews often focus on the destination warehouse because that's where data accumulates. In practice, the ingestion path deserves equal attention. That's where credentials, transformations, retries, temporary buffers, and external interfaces all meet. If you don't secure that path, the rest of the platform inherits avoidable risk.
Why Ingestion Needs Data Quality and Observability
A pipeline can be green and still be wrong. That's the core reason ingestion alone isn't enough. Shipping data from source to destination only proves movement happened. It doesn't prove the data arrived complete, on time, structurally consistent, or logically valid.
Shipping data is not the same as trusting it
The simplest analogy is shipping versus inspection. Ingestion is the carrier that gets packages to the dock. Quality and observability are the inspection layer that checks whether the right packages arrived, whether anything is missing, and whether the contents match expectation.

Many teams often succumb to false confidence. Their orchestrator says the job completed. The connector didn't error. The destination table exists. But analysts still complain that yesterday's dashboard is stale, a KPI suddenly shifted, or a model started making odd decisions. The root issue is usually one of these:
Timeliness failures where data arrives late or not at all.
Schema changes that alter downstream assumptions without obvious breakage.
Value drift that changes the meaning or distribution of important fields.
Record-level quality issues such as null spikes, malformed keys, or duplicated events.
A reliable platform watches those conditions from the moment data lands, not only after users notice something broke. If you're comparing the boundaries between these disciplines, this explanation of data observability vs data quality is a useful framing reference because teams often blur them in design discussions.
A successful ingestion program doesn't stop at delivery. It establishes evidence that the delivered data is usable.
Duplicates and anomalies are not the same problem
One nuance that gets mishandled constantly is the difference between a duplicate and an anomaly. They sound related, but they point to different remediation paths.
According to IBM's overview of data ingestion, the confusion between duplication and anomaly in ingestion monitoring is rarely addressed, and that gap leads teams to apply anomaly rules to duplicate records, wasting resources. That's a practical failure, not a semantic one.
Here's the clean distinction:
Issue | What it usually means | Best response |
|---|---|---|
Duplicate record | The same business event or entity was loaded more than once | Deduplicate, inspect keys, review idempotency and replay logic |
Anomaly | Something changed in the shape, timing, or statistical behavior of the data | Investigate upstream changes, pipeline health, or business process shifts |
If you treat duplicates like anomalies, you escalate noise instead of fixing ingestion semantics. If you treat anomalies like duplicates, you can erase evidence of a real upstream problem. Strong observability separates these classes early so engineers know whether to fix pipeline mechanics, source behavior, or business rules.
A sound operating model usually includes both:
Validation rules for explicit record-level expectations
Timeliness monitoring for arrivals and delays
Schema tracking for structural change
Anomaly detection for unexpected distribution or pattern shifts
That's how ingestion becomes a trustworthy foundation instead of just a transport layer.
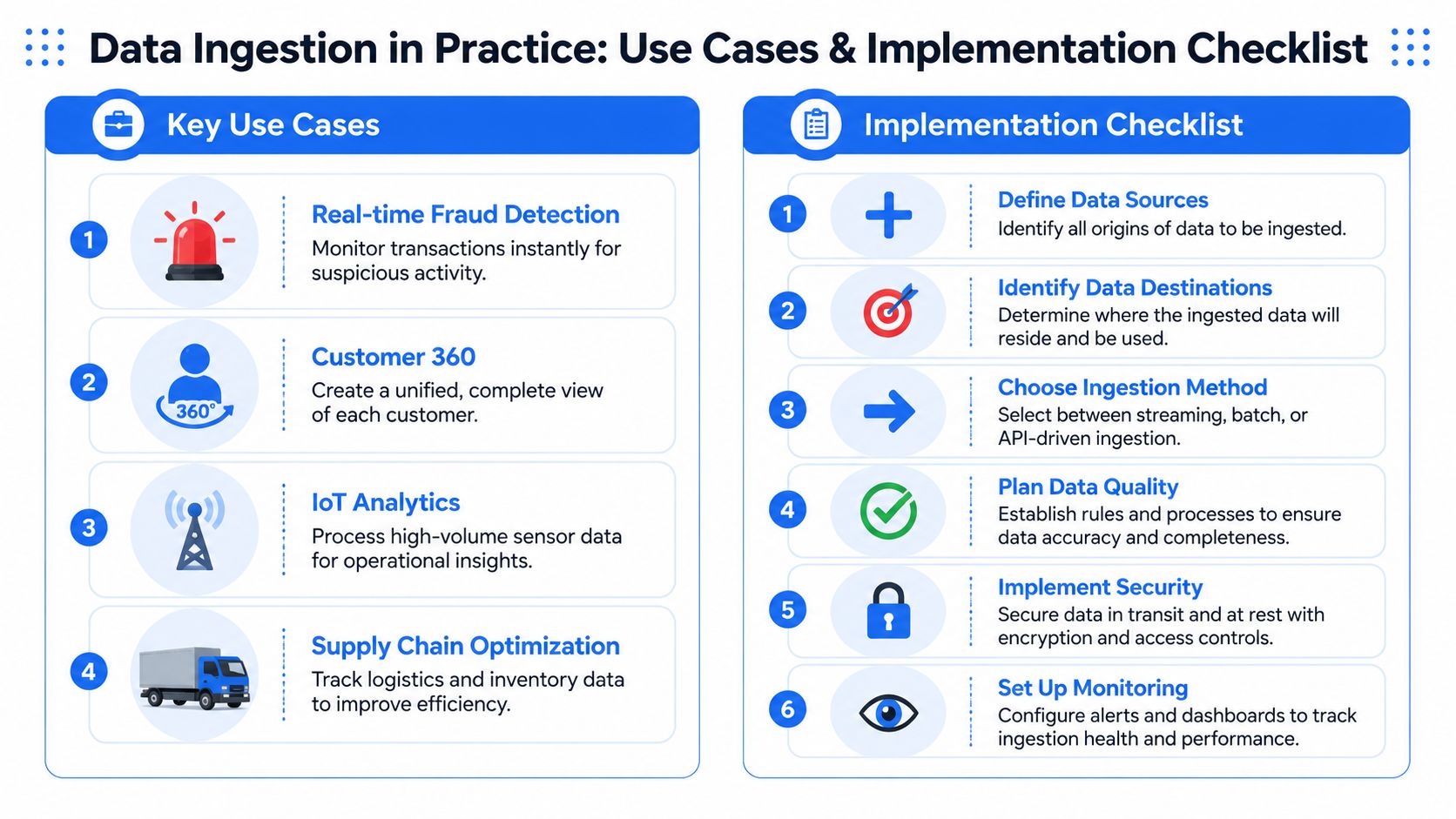
Data Ingestion in Practice Use Cases and a Checklist
The value of data ingestion software is easiest to see when it fails under real workloads. Use cases expose architecture decisions quickly because each one cares about a different combination of speed, completeness, and tolerance for noise.
Where ingestion choices show up in real systems
In finance, streaming ingestion supports transaction monitoring and suspicious activity workflows where waiting for a nightly refresh isn't acceptable. In warehouse modernization projects, batch ingestion is often the practical answer because teams need controlled movement of large historical datasets before they optimize for freshness. In customer analytics, hybrid patterns are common because business teams want near-current activity, while data engineers still need reconciliation for late or corrected records.
AI and ML pipelines add another wrinkle. Teams often reduce the design choice to "real-time or batch," but that's too simple. As Skyvia's explanation of data ingestion notes, latency trade-offs for AI and ML pipelines are often oversimplified, and excessive real-time ingestion can destabilize models by introducing noise faster than models can adapt. That shows up in practice when feature pipelines push every new signal immediately, even when the model or training process isn't designed to absorb that volatility.
Fast ingestion is only useful when downstream consumers can interpret the arriving data without becoming less stable.
That same principle applies to operational analytics. Real-time isn't necessarily better. It's better only when the consuming workflow benefits from it and the platform can preserve trust under that speed.
A practical rollout checklist
A rollout usually succeeds when teams make a few decisions early and make them explicitly.
Inventory sources and owners
List every source, who owns it, how often it changes, and what failure looks like. Unknown ownership creates slow incident response later.Define destinations by use case
Don't route everything to the same place by default. Warehouses, lakes, feature stores, and operational sinks often need different ingestion contracts.Choose architecture per data product
Use batch, streaming, or hybrid based on consumer requirements, not tool defaults.Set quality expectations before first load
Document required fields, key uniqueness assumptions, timeliness expectations, and acceptable schema evolution.Secure the path early
Lock down credentials, access scopes, logging, and sensitive field treatment before pipelines multiply.Plan monitoring from day one
Track failures, lag, missing arrivals, schema changes, and suspicious value shifts as part of launch criteria.Design replay and recovery
Every pipeline eventually needs backfill, reconciliation, or partial rerun support.Create an operating checklist for teams
A shared framework helps when analytics engineers, data engineers, and platform owners are all touching the same system. This data reliability checklist for data teams is a useful reference point for turning reliability into an operational habit instead of an afterthought.
The teams that do this well don't just implement ingestion. They define what "healthy arrival" means before data starts moving.
Choosing the Right Ingestion Strategy for 2026
Choosing data ingestion software for 2026 isn't really about picking the product with the most connectors or the slickest setup flow. It's about choosing a strategy that fits your data products, your operating model, and your tolerance for risk. The wrong tool can absolutely slow you down. But the more common failure is buying a decent tool and surrounding it with weak assumptions.
The key decisions are straightforward. Match the architecture to the use case. Decide where the software should run based on control and compliance needs. Evaluate connectors for resilience, not just breadth. Make performance a question of operational behavior, not brochure speed. Then add the controls that turn movement into trust: timeliness checks, validation rules, schema awareness, and anomaly monitoring.
That's the key shift mature teams make. They stop asking, "How do we ingest more data?" and start asking, "How do we ensure every downstream consumer gets data that's fresh, complete, and dependable enough to act on?" That change in mindset improves more than pipeline health. It reduces wasted debugging cycles, gives analysts confidence in outputs, and protects ML systems from brittle inputs.
Ingestion is the first promise your data platform makes. It promises that data will arrive. A modern platform has to make a second promise too. The arriving data will be usable.
If you want that second promise built into your stack, digna helps teams monitor timeliness, detect anomalies, validate records, and track schema changes inside customer-controlled environments so ingestion doesn't stop at delivery.



