Datenpipeline-Architektur: Ein kompletter Leitfaden für 2026
|
0
min. Lesezeit

Der Bericht sah um 8:00 Uhr morgens noch gut aus. Bis 9:15 Uhr hatte die Finanzabteilung ihn bereits in einem Meeting verwendet. Zur Mittagszeit bemerkte jemand, dass die Gesamtsummen nicht stimmten – nicht weil das SQL fehlerhaft war, sondern weil eine vorgelagerte Tabelle über Nacht aufgehört hatte, eine Teilmenge von Datensätzen zu empfangen. Es wurde kein Alarm ausgelöst. Die Pipeline „lief“ technisch gesehen. Das Dashboard lieferte veraltetes Vertrauen.
Das ist das Fehlerszenario, mit dem viele Unternehmen derzeit zu kämpfen haben. Keine dramatischen Ausfälle, sondern stille Korruption. Eine vergessene Datei, eine Schemaänderung, eine Transformation, die zwar immer noch ausgeführt wird, aber jetzt das falsche Feld zuordnet, ein sich verzögernder Feed, der einen aktuellen KPI in die Antwort von gestern verwandelt. Sobald das passiert, sinkt das Vertrauen schneller, als es Ihnen jede Systemmetrik anzeigen kann.
Eine starke Datenpipeline-Architektur löst mehr als nur den Transport von der Quelle zum Ziel. Sie entscheidet darüber, ob Ihre Datenplattform etwas ist, dem die Anwender unter Druck vertrauen, ob Analysten Zahlen ohne Rätselraten erklären können und ob Modelleingaben stabil bleiben, während sich die Quellsysteme weiterentwickeln. Der schwierigste Teil ist nicht das Zeichnen von Kästchen. Es geht darum, die Pipeline so zu entwerfen, dass Qualität, Aktualität und Sichtbarkeit vom ersten Diagramm an vorhanden sind, und nicht erst nach der ersten Eskalation durch die Geschäftsführung.
Teams, die mit gemischten Inputs arbeiten, stehen vor dieser Herausforderung noch deutlicher, wenn halbstrukturierte Dokumente in den Fluss gelangen. Wenn Ihre Pipeline eine Dokumentenextraktion für KI-Anwendungsfälle umfasst, lohnt sich ein Blick in diesen praktischen Leitfaden zum Konvertieren von PDFs für LLMs, da Fehler in der Dokumentenstruktur oft lange vor der Modellierung beginnen. Für eine visuelle Ausgangsbasis, wie diese Systeme zusammenpassen, hilft ein einfaches Datenarchitektur-Diagramm, das Gespräch abzustimmen, bevor Sie die Tools anfassen.
Inhaltsverzeichnis
Ihr Leitfaden für moderne Datenpipeline-Architektur
Eine nützliche Definition von Datenpipeline-Architektur ist einfach: Es ist der operative Bauplan dafür, wie Daten gesammelt, verändert, gespeichert und bereitgestellt werden, ohne dass sie unterwegs an Bedeutung verlieren. Das klingt unkompliziert, bis man ein System übernimmt, bei dem Ingestion, Transformationen, Zeitpläne, Speicherung und Dashboards alle zu unterschiedlichen Zeiten von unterschiedlichen Teams entwickelt wurden.
In der Praxis zeigt sich die Architektur in Fehlermustern. Ein unflexibles Design führt dazu, dass Teams Angst haben, irgendetwas zu ändern. Eine schwache Übergabe zwischen Ingestion und Transformation führt dazu, dass fehlerhafte Datensätze weitergegeben werden. Eine Berichterstattungsebene ohne Aktualitätsgarantie erzieht das Unternehmen dazu, Probleme manuell zu entdecken. Nichts davon lässt sich beheben, indem man einen weiteren Orchestrator oder ein weiteres Dashboard hinzufügt.
Die Architektur muss auch widerspiegeln, wie Menschen tatsächlich arbeiten. Analysten wollen stabile Tabellen. Plattform-Teams wollen wiederholbare Bereitstellungen. ML-Ingenieure wollen Inputs, die sich nicht unbemerkt verändern. Sicherheitsteams wollen, dass Daten in kontrollierten Umgebungen bleiben. Ein moderner Bauplan muss alle diese Anforderungen erfüllen, ohne zu einem Labyrinth zu werden.
Zuverlässige Pipelines sind nicht diejenigen, die niemals ausfallen. Es sind diejenigen, die so ausfallen, dass die Betreiber es schnell sehen, isolieren und beheben können.
Deshalb behandeln die besten Designs die Pipeline weniger wie ein Rohrsystem, sondern eher wie ein Produktionssystem. Jede Phase hat einen Eigentümer. Jede Abhängigkeit ist sichtbar. Jeder Bereitstellungspfad hat eine Erwartung an Aktualität und Korrektheit. Wenn Sie mit diesen Annahmen bauen, werden alle weiteren Entscheidungen viel klarer.
Die vier Säulen einer Datenpipeline
Der einfachste Weg, Pipeline-Design zu erklären, ist eine Analogie zur Küche. Die Zutaten kommen von Lieferanten an, werden sicher gelagert, von Köchen zubereitet und schließlich den Gästen serviert. Wenn an einem Schritt etwas schiefgeht, ist es dem Kunden egal, welcher Posten versagt hat. Er weiß nur, dass das Essen zu spät oder falsch ist.

Denken wie eine Betriebslinie
Die technische Version hat vier praktische Säulen:
Ingestion ruft Daten aus Quellsystemen ab. Das können APIs, transaktionale Datenbanken, SaaS-Tools, Event-Streams oder Datei-Ablagen sein.
Storage speichert rohe oder bereitgestellte Daten an einem sicheren Ort, oft auf Plattformen wie Amazon S3, Snowflake oder Databricks.
Processing transformiert die Daten in ein nutzbares Format. Dies umfasst Bereinigung, Deduplizierung, Filterung, Formatierung und Verknüpfungen.
Serving stellt das Ergebnis Dashboards, Reverse-ETL-Tools, Modellen, Anwendungen oder nachgelagerten Konsumenten zur Verfügung.
Eine der klarsten modernen Zusammenfassungen stammt aus Striims Erklärung moderner Datenpipeline-Komponenten, die den Kern als Ingestion, Transformation und Speicherung beschreibt und feststellt, dass Fehler bei der Transformation direkt zu veralteten Berichten und fehlerhaften Dashboards führen, wenn fehlerhafte Daten die Konsumschicht erreichen. Ich trenne Serving immer noch als eigene architektonische Aufgabe, da viele Teams zwar die Pipeline bauen, aber die Übergabe an die Personen und Systeme, die sie nutzen, vernachlässigen.
Wo Teams normalerweise Fehler machen
Die Fehler passieren selten an den Rändern. Sie passieren in den Übergängen.
Einige Beispiele zeigen sich immer wieder:
Rohdaten kommen ohne Vertragsprüfungen an. Die Pipeline akzeptiert Datensätze, aber niemand überprüft, ob wichtige Felder fehlen oder falsch typisiert sind.
Speicher wird zum Müllplatz. Teams heben jede Version von allem auf, unterscheiden aber nicht zwischen Landing-, kuratierten und konsumbereiten Zonen.
Transformationen werden zu einem Monolithen. Ein einziger riesiger Job verarbeitet die gesamte Logik, sodass das Debuggen einer einzigen Metrik bedeutet, das gesamte System zu durchforsten.
Serving wird als „nur BI“ abgetan. In Wirklichkeit gehören semantische Konsistenz, Aktualitätserwartungen und Zugriffsmuster genau hierhin.
Praktische Regel: Wenn ein Konsument nicht beantworten kann, woher eine Zahl stammt, ist Ihre Serving-Ebene noch nicht fertig.
Eine gute Architektur hält jede Säule so weit getrennt, dass sie unabhängig betrieben werden kann, aber so weit verbunden, dass Fehler sich nicht dazwischen verstecken können. Diese Trennung macht spätere Entscheidungen über Muster, Resilienz und Observability handhabbar statt chaotisch.
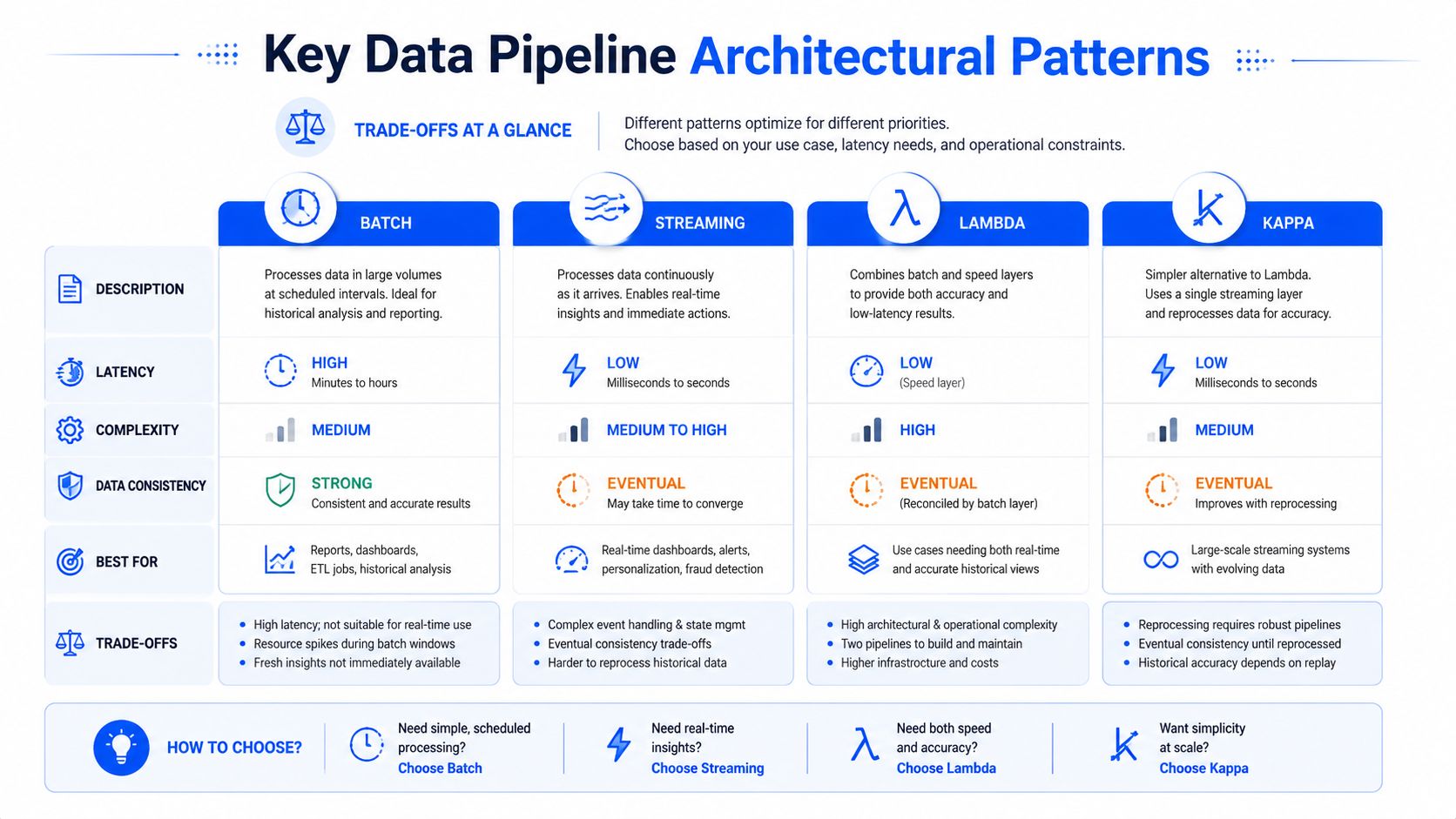
Wichtige Architekturmuster für Datenpipelines
Bei den Architekturmustern machen Teams oft teure Fehler, weil jede Option für bestimmte Zwecke gut funktioniert. Die falsche Wahl ist meist keine „schlechte Technologie“, sondern eine Diskrepanz zwischen den Latenzanforderungen, der betrieblichen Komplexität und der Art der Analysen, die das Unternehmen benötigt.
ETL und ELT lösen unterschiedliche Probleme
ETL eignet sich für Umgebungen, in denen die Transformation stattfinden muss, bevor die Daten im Ziel ankommen. Das ist üblich, wenn die Bereinigung an der Quelle streng ist, die Rechenleistung am Ziel begrenzt ist oder regulatorische Vorgaben Kontrollen vor dem Laden erfordern.
ELT funktioniert besser, wenn die Zielplattform für schwere Verarbeitung ausgelegt ist und Teams nach dem Laden flexibel bleiben wollen. Data Warehouses und Lakehouses haben dieses Muster weitaus praktischer gemacht, da man Daten schnell laden und später mit SQL-basierten Transformationen formen kann.
Keines der Muster ist paatentiert überlegen. ETL bietet eine strengere Kontrolle vor der Ingestion. ELT bietet mehr Agilität für Analyseteams. Wenn Sie Tools für den Anfang der Pipeline evaluieren, ist diese Übersicht über Daten-Ingestion-Software ein nützlicher Ausgangspunkt, um zu vergleichen, wie sich Entscheidungen zur Quellerfassung auf den Rest des Stacks auswirken.
Batch-Streaming: Lambda und Kappa
Batch und Streaming sind eine folgenschwerere Weichenstellung.
Batch ist die bessere Wahl, wenn das Unternehmen eine geplante Bereitstellung tolerieren kann und die Pipeline große historische Datenbestände konsistent verarbeiten muss. Finanzberichte zum Jahresende sind ein klassischer Fall. Streaming eignet sich für Situationen, in denen Verzögerungen den Nutzen des Anwendungsfalls schwächen, wie z. B. bei der betrieblichen Überwachung, Alarmierung oder ereignisgesteuerten Workflows.
Die Hybridformen sind wichtig, wenn Sie beides benötigen. Striims Beitrag zu Lambda- und Kappa-Architekturmustern bringt den Unterschied gut auf den Punkt. Die Lambda-Architektur gleicht Echtzeitgeschwindigkeit mit Batch-Zuverlässigkeit aus, indem sie parallele Datenströme ausführt. Ein schneller Pfad verarbeitet das Echtzeit-Streaming, ein langsamer Pfad die historische Verarbeitung, und eine Serving-Ebene führt die Ergebnisse zusammen. Die Kappa-Architektur verzichtet auf die separate Batch-Ebene und wickelt sowohl Echtzeit- als auch historische Verarbeitung über eine einzige Streaming-Pipeline ab, was den Betrieb durch den Verzicht auf duale Systeme vereinfacht.
Diese Vereinfachung ist attraktiv, aber Kappa hat einen echten Haken. Die erneute Verarbeitung der Stream-Historie durch eine einzige Pipeline ist nur dann elegant, wenn Ihre Tools, Ihre Aufbewahrungsstrategie und Ihre betriebliche Disziplin stark genug sind, um ein sicheres Replay zu unterstützen.
Datenpipeline-Muster im Vergleich
Muster | Hauptanwendungsfall | Vorteile | Nachteile |
|---|---|---|---|
Batch | Geplante Analysen und wiederkehrende Berichte | Vorhersehbar, gut für große historische Jobs, einfacher zu verstehen | Höhere Latenz, weniger geeignet für betriebliche Reaktionen |
Streaming | Ereignisgesteuerte Anwendungsfälle und Nahezu-Echtzeit-Sichtbarkeit | Geringe Latenz, stark für Alarme und Live-Betrieb | Schwierigere Fehlerbehandlung, Replays und Statusverwaltung |
Lambda | Teams, die sowohl historische Tiefe als auch sofortige Erkenntnisse benötigen | Deckt Batch-Zuverlässigkeit und Echtzeit-Geschwindigkeit gleichzeitig ab | Zwei Pfade zum Erstellen, Testen und Verwalten |
Kappa | Streaming-First-Umgebungen, die ein einziges Verarbeitungsmodell wünschen | Einfacheres Betriebsmodell als Systeme mit zwei Pfaden | Replay-Strategie und Stream-Disziplin werden kritisch |
Eine Bank könnte Batch für aufsichtsrechtliche Berichte verwenden, Streaming für Betrugssignale und ein hybrides Muster, bei dem Kundenaktivitäten sofortige Reaktionen, aber auch einen historischen Abgleich erfordern. Das ist der Punkt. Wählen Sie das Muster, das zum Entscheidungszyklus passt, nicht das, das auf einer Präsentationsfolie am modernsten aussieht.
Robuste Pipelines bauen, die nicht brechen
Die Pipelines, die am meisten Probleme verursachen, sind meist diejenigen, die „einwandfrei funktionierten“, bis sich das Geschäft änderte. Eine neue Quelle kommt hinzu. Ein Feld wird umbenannt. Ein Team fügt Logik für ein Dashboard hinzu, ein anderes fügt ML-Features hinzu, und plötzlich legt ein einziger Fehler drei voneinander unabhängige Ausgaben lahm, weil alles in derselben starren Kette hängt.

Modularität ist ein Überlebensmerkmal
Modulares Design ist kein Stilmittel. Es ist das, was verhindert, dass aus einer Änderung ein Ausfall wird.
Monte Carlos Diskussion über modulare und automatisierte Pipeline-Architektur bringt den Kernpunkt direkt auf den Punkt: Zuverlässige Pipelines müssen modular und automatisiert sein. Unmodulare Architekturen führen zu fehlerhaften Änderungen, die Teams davor zurückschrecken lassen, Anpassungen vorzunehmen. Diese Beschreibung ist schmerzhaft treffend. Sobald Menschen Angst haben, eine Pipeline zu ändern, verschlechtert sich die Qualität, weil bekannte Probleme länger bestehen bleiben, als sie sollten.
Eine praktische modulare Struktur umfasst in der Regel:
An der Quelle ausgerichtete Ingestion-Einheiten, die unabhängig voneinander ausfallen oder neu abgespielt werden können.
Transformationsschichten mit klaren Schnittstellen, damit Staging-Logik, Konformitätslogik und Geschäftslogik nicht in einem einzigen Schritt verschmelzen.
Wiederverwendbare Qualitätsprüfungen, die mit dem Modul wandern, anstatt in einer separaten Tabelle zu leben.
Bereitstellungsautomatisierung, damit Releases wiederholbar sind und Rollbacks nicht zu einer heldenhaften Leistung werden.
Lineage-Tests und parallele Ausführung
Der nächste Fehlerquelle ist die Blindheit gegenüber Abhängigkeiten. Teams glauben zu wissen, wer eine Tabelle nutzt, bis sie eine Spalte verwerfen und eine Metrik beschädigen, von der niemand mehr wusste, dass sie existiert.
Automatisierte Lineage löst dieses Problem. Menschliche Nachverfolgung übersteht die Komplexität nicht, insbesondere wenn mehrere Orchestrierungs-Tools, Warehouses und Serving-Ebenen im Spiel sind. Wenn eine Pipeline verzögert wird oder sich ein Schema ändert, verkürzt Lineage die Ursachenanalyse von der Suche im Nebel auf eine gezielte Untersuchung.
Hier ist die betriebliche Abfolge, die ich empfehle, bevor eine Pipeline als produktionsreif eingestuft wird:
Komponenten isolieren, damit eine Codeänderung kein vollständiges Refactoring erfordert.
Schnittstellenerwartungen definieren für jede Übergabe, einschließlich Schema und Aktualität.
Module und vollständige Pfade testen, da ein isolierter Unit-Test falsche Annahmen zwischen den Phasen nicht aufdeckt.
Eine nützliche Erklärung zu resilienten Pipeline-Praktiken finden Sie unten.
Und noch ein Punkt wird oft übersehen: Parallele Ausführung ist keine Optimierung, die man später hinzufügt. Bei modernen Workflows gehört sie in den Entwurf. Wenn unabhängige Aufgaben gleichzeitig ausgeführt werden können, reduzieren Sie Engpässe und sichern die Bereitstellungsfenster bei wachsendem Datenvolumen. Wenn Sie das nicht von Anfang an einplanen, wird jede Zunahme der Quellaktivität zu einem Planungsproblem.
Bauen Sie die Pipeline so auf, dass ein Team eine Komponente ändern kann, ohne fünf andere Teams um Erlaubnis fragen zu müssen.
Sichern von Datenpipelines in Ihrer Umgebung
Die Sicherheitsarchitektur beginnt mit einer direkten Frage: Wo befinden sich die Daten, während die Pipeline läuft? Viele Teams konzentrieren sich auf Verschlüsselung und Zugriffskontrolle, ignorieren aber die Datenbewegung. Das ist ein Fehler, insbesondere in der Finanzbranche, im Gesundheitswesen, in der Telekommunikation und im öffentlichen Sektor, wo Datenresidenz und Expositionswege genauso wichtig sind wie die Transformationslogik.
Datenresidenz verändert das Design
On-Premises- und Private-Cloud-Bereitstellungen zwingen zu einer besseren architektonischen Disziplin, weil man nicht einfach darüber hinwegsehen kann, wohin sensible Daten fließen. Wenn eine Pipeline Produktionsdaten in ungesicherte Staging-Zonen kopiert, den Zugriff während der Transformation ausweitet oder Payloads für Qualitätsprüfungen an externe Dienste sendet, haben Sie die Angriffsfläche vergrößert, noch bevor die Daten überhaupt die Analyseebene erreichen.
Die Ausführung innerhalb der vom Kunden kontrollierten Umgebung zu belassen, ändert diese Ausgangslage grundlegend. Es reduziert unnötige Datenbewegungen, schränkt den Zugriff auf Produktionsdaten ein und vereinfacht Audit-Prozesse erheblich. Dies ist besonders wichtig, wenn regulierte Daten in einer bestimmten Umgebung verbleiben müssen oder wenn interne Richtlinien den Zugriff von Drittanbietern auf Live-Datensätze verbieten.
Sicherheitskontrollen, die in den Bauplan gehören
Eine sichere Datenpipeline-Architektur weist in der Regel einige gemeinsame Merkmale auf:
Verschlüsselung bei der Übertragung und im Ruhezustand (in Transit / at Rest), damit Extraktion, Übertragung und Speicherung keine lesbaren Schwachstellen erzeugen.
Rollenbasierter Zugriff (RBAC), der Pipeline-Betreiber, Entwickler, Analysten und Geschäftsanwender voneinander trennt.
Segmentierung der Umgebungen, damit Entwicklung, Test und Produktion nicht miteinander verschmelzen.
Auditierbare Validierungspfade für Geschäftsregeln, die Auswirkungen auf die Compliance haben.
Minimal-Copy-Design, damit die Architektur die Erstellung doppelter sensibler Datensätze zur bloßen Überwachung vermeidet.
Sicherheit überschneidet sich auch mit den Bereitstellungserwartungen. Wenn Ihre Architektur SLAs für Aktualität und Verzögerungserkennung enthält, können Betreiber ungewöhnliche Verzögerungen sowohl als Zuverlässigkeitsproblem als auch als potenzielles Sicherheitssignal untersuchen. Ein unerwartet gestoppter Feed kann ein Quellenproblem sein. Es kann sich aber auch um ein Rechte-, Richtlinien- oder Konnektivitätsproblem handeln, das sofortige Aufmerksamkeit erfordert.
Die robustesten Konzepte behandeln Compliance als architektonische Eigenschaft und nicht als reine Dokumentationsübung. Wenn Sie Datenqualität, Anomalieerkennung und Schema-Tracking benötigen, entwerfen Sie diese Kontrollen so, dass sie dort laufen, wo sich die Daten bereits befinden. Das ist in der Regel sicherer, einfacher zu verwalten und in einer Prüfung leichter zu verteidigen.
Integrating Data Quality and Observability by Design
Viele Unternehmen glauben, sie hätten Observability, obwohl sie in Wirklichkeit nur das Ziel überwachen. Sie wissen, ob die Warehouse-Tabelle existiert. Sie wissen, ob der BI-Job abgeschlossen wurde. Sie wissen jedoch nicht, ob die Daten in einem fehlerfreien Zustand in die Pipeline gelangt sind, ob sie ihre Form auf gefährliche Weise geändert haben oder ob sie so spät angekommen sind, dass der Bericht irreführend ist.

Observability beginnt bei der Ingestion
Diese Lücke ist genau der Grund, warum Observability in der Architektur selbst verankert sein muss. Alations Diskussion über Datenpipeline-Architekturmuster und Observability macht einen wichtigen Unterschied deutlich: Die Qualitätsvalidierung gehört an den Einstiegspunkt, nicht erst nach der Verarbeitung. Wenn Sie bis zu den Prüfungen am Zielort warten, haben sich silent drift, Schemaänderungen und fehlende Werte bereits im gesamten Datenfluss ausgebreitet.
Marktdruck und betriebliche Realität treffen aufeinander. Der Markt für Datenpipeline-Tools wird auf 14,76 Milliarden US-Dollar geschätzt, bei einer jährlichen Wachstumsrate (CAGR) von 26,8 %. Dieselbe Quelle stellt fest, dass moderne Pipelines über 800 Millionen Datensätze pro Tag verarbeiten können. Bei dieser Größenordnung ist eine Observability-Ebene mit Metriken wie verarbeiteten Datensätzen pro Sekunde und Fehlerraten pro Stufe kein Luxus mehr. Sie ist eine grundlegende betriebliche Notwendigkeit.
Warum gelernte Erkennung starre Regeln schlägt
Regelbasierte Prüfungen sind nach wie vor wichtig, insbesondere für explizite Geschäftseinschränkungen. Aber sie versagen, wenn das Problem eher verhaltensbedingt als binär ist.
Die Anomalieerkennung ist für diese Aufgabe besser geeignet, da sie erwartete Muster lernen und Ausreißer ohne ständige manuelle Schwellenwertpflege melden kann. FirstEigen erklärt die KI-gestützte Anomalieerkennung in Datenströmen als einen Prozess zur Etablierung von Baselines für qualitativ hochwertige Daten, um anschließend verdächtige Abweichungen zur Überprüfung anzuzeigen. Oracles Übersicht über statistische und neuronale Methoden zur Anomalieerkennung bietet hier nützliche Tiefe. Clustering, dichte-basierte Methoden wie LOF und Autoencoder helfen dabei, lokale und subtile Anomalien zu erkennen, die einfachere Tests übersehen.
Für Teams, die dokumentenlastige Pipelines verwalten, gilt dasselbe Prinzip auf Feldebene. Dieser Leitfaden zur Datenvalidierung für Rechnungen und Bestellungen ist eine gute Erinnerung daran, dass es bei der Validierung nicht nur um Schemata geht. Es geht auch darum, Regeln auf Datensatzebene durchzusetzen, bevor sich fehlerhafte Werte in die nachgelagerte Logik einschleichen.
Schlechte Daten, die bei der Ingestion abgefangen werden, sind ein verhinderter Vorfall. Schlechte Daten, die auf einem Dashboard landen, sind ein Vertrauensproblem.
Was Sie vom ersten Tag an instrumentieren sollten
Ein natives Observability-Design sollte mindestens vier Dimensionen überwachen:
Aktualität verfolgt, wann Daten erwartet werden und ob sich die Ankunftsmuster verschieben.
Volumen erkennt plötzliche Einbrüche, Spitzen oder ungewöhnliche Verteilungsänderungen.
Schema meldet hinzugefügte Spalten, entfernte Spalten und Typänderungen, bevor Transformationen unbemerkt brechen.
Validierung setzt fachliche Regeln auf Datensatzebene durch, bei denen die Korrektheit explizit sein muss.
Wenn die Pipeline sequentielle oder ereignisgesteuerte Daten verarbeitet, verdienen zeitliche Muster besondere Aufmerksamkeit. Nile Secures Erklärung zur Datenvorverarbeitung und zeitbasierten Anomalieerkennung hebt die Rolle der Vorverarbeitung, des Feature-Engineerings und der für sequentielles Verhalten geeigneten Modelle wie LSTMs hervor. Das ist wichtig, denn viele „Pipelinefehler“ sind in Wirklichkeit Aktualitätsfehler: Daten kommen an, nur nicht dann, wenn das Unternehmen sie benötigt.
Ein nützliches mentales Modell ist dieses: Monitoring zeigt Ihnen, dass ein Job gelaufen ist. Observability sagt Ihnen, ob die Daten während des Laufs vertrauenswürdig geblieben sind. Für einen fundierten Vergleich dieser Aufgaben lohnt es sich, diesen Vergleich zwischen Data Observability und Data Quality griffbereit zu haben, wenn Sie die Steuerungsebene entwerfen.
Eine praktische Checkliste für Ihre nächste Pipeline
Der schnellste Weg, ein Pipeline-Review zu verbessern, besteht darin, nicht mehr zu fragen, ob das System funktioniert, sondern unter welchen Bedingungen es aufhört, vertrauenswürdig zu sein.

Verwenden Sie diese Checkliste, bevor Sie ein neues Design freigeben oder ein bestehendes prüfen:
Quellverträge frühzeitig definieren. Kennen Sie die Struktur, die Zuständigkeiten, die Aktualisierungsmuster und die Fehlerszenarien jeder Quelle?
Muster nach Entscheidungszyklus wählen. Ist dieser Anwendungsfall Batch, Streaming oder hybrid, basierend darauf, wie schnell jemand auf die Daten reagieren muss?
Rohdaten-, transformierte und bereitgestellte Schichten trennen. Können Sie die Ingestion erneut abspielen, ohne die Geschäftslogik von Grund auf neu aufzubauen?
Module entwerfen, keine Monster. Kann ein Team eine Komponente ändern, ohne das Risiko für unbeteiligte Konsumenten zu erhöhen?
Lineage automatisch zuordnen. Wenn sich heute ein Schema ändert, können Sie betroffene Tabellen, Dashboards und Modelle schnell identifizieren?
Parallele Ausführung einplanen. Bleibt der Durchsatz stabil, wenn die Quellen wachsen oder sich die Aktualisierungsfenster überschneiden?
Erwartungen an die Aktualität festlegen. Gibt es ein klares SLA oder eine betriebliche Vorgabe dafür, wann Daten eintreffen sollten und ab wann eine Verzögerung als Vorfall gilt?
Validierung und Observability ab dem ersten Release integrieren. Sind Aktualität, Volumen, Schema und Prüfungen auf Datensatzebene Teil der Architektur und nicht nur ein optionales Add-on?
Sensible Daten nach Möglichkeit lokal belassen. Minimiert Ihr Design Kopien und schränkt es den Zugriff während der Überwachung und Transformation ein?
Die Übergaben dokumentieren. Kann ein neuer Teamleiter verstehen, was reinkommt, was sich ändert, was gespeichert wird und wer es nutzt?
Eine gute Pipeline ist nicht die komplizierteste. Es ist diejenige, die Ihr Team sicher ändern, klar überwachen und unter Druck vertrauen kann.
Wenn Ihr Team diese Kontrollen wünscht, ohne Produktionsdaten aus Ihrer Umgebung zu bewegen, lohnt sich ein genauer Blick auf digna. Es kombiniert Datenqualität und Observability auf einer Plattform, läuft in kundenkontrollierten Private-Cloud- oder On-Premises-Umgebungen und hilft Teams, Anomalien, Schemaänderungen, Aktualitätsprobleme und Validierungsfehler auf Datensatzebene abzufangen, bevor sie zu veralteten Berichten oder fehlerhaften nachgelagerten Systemen führen.



