Warehouse-Datenmodellierung meistern: Konzepte & Produktion
|
0
min. Lesezeit

Ihre Dashboards werden geladen, aber niemand vertraut ihnen. Die Finanzabteilung sagt, dass der Umsatz nicht stimmt. Die operativen Teams sehen fehlende Datensätze. Analysten verbringen mehr Zeit damit zu erklären, warum sich eine Kennzahl verändert hat, als damit, was dagegen zu tun ist. Das ist meistens der Moment, in dem Teams erkennen, dass das Warehouse nicht an der SQL-Syntax oder dem BI-Tooling scheitert. Es scheitert, weil das dem Warehouse zugrunde liegende Modell nie zu einem langlebigen System geworden ist.
Gute Warehouse-Datenmodellierung verwandelt verstreute operative Daten in etwas, das Benutzer abfragen, verstehen und dem sie vertrauen können. Sie entscheidet auch darüber, wie schmerzhaft zukünftige Änderungen sein werden. Ein Modell, das in einem Diagramm sauber aussieht, kann unter verspätet eintreffenden Daten, unklaren Definitionen, langsamen Joins und Schema-Drift immer noch zusammenbrechen. Ein Modell, das in der Produktion funktioniert, muss all diesen Belastungen gleichzeitig standhalten.
Inhaltsverzeichnis
Warum Warehouse-Datenmodellierung Ihr Analyse-Fundament ist
Wenn ein Team sagt: „Unsere Daten sind unordentlich“, ist das zugrunde liegende Problem meist struktureller Natur. Tabellen spiegeln das Applikationsverhalten wider anstatt der geschäftlichen Bedeutung. Kennzahlen werden auf drei verschiedene Arten berechnet. Historische Änderungen werden überschrieben, sodass niemand beantworten kann, wie ein Kunde, ein Produkt oder ein Vertrag zu einem früheren Zeitpunkt aussah.
Genau hier kommt die Warehouse-Datenmodellierung ins Spiel. Sie gibt Analysten eine stabile Sprache für das Unternehmen an die Hand. Anstatt rohe Bestellungen, Kundendaten, Rechnungen und Statusprotokolle jedes Mal neu zusammenzufügen, wenn jemand einen Bericht benötigt, bietet das Warehouse langlebige Entitäten, konsistente Joins und abgestimmte Definitionen.

Vertrauen bricht, bevor Pipelines versagen
Eine Pipeline kann erfolgreich abgeschlossen werden und dennoch fehlerhafte Analysen liefern. Die Daten kommen vielleicht pünktlich an, aber das Modell kann immer noch Duplikate verbergen, Beziehungen fälschlicherweise verflachen oder die Historie löschen, die nachgelagerte Benutzer für Trendanalysen und Audits benötigen.
Die praktische Konsequenz ist simpel: Schlechte Modelle erzeugen Diskussionen. Gute Modelle führen zu Entscheidungen.
Praxistipp: Wenn ein Geschäftsanwender einen Data Engineer benötigt, um jeden Dashboard-Join zu erklären, ist das Modell noch zu nah an den Quellsystemen.
Ein solides Warehouse-Modell erfüllt drei Aufgaben gleichzeitig:
Schafft Konsistenz: Kunden-, Produkt- und Umsatzdefinitionen ändern sich nicht mehr von Dashboard zu Dashboard.
Unterstützt historische Analysen: Teams können nicht nur beantworten, was jetzt gilt, sondern auch, was zu einem bestimmten Zeitpunkt der Fall war.
Verbessert die Wartbarkeit: Engineers können neue Quellen und Metriken hinzufügen, ohne die gesamte Analyseschicht neu schreiben zu müssen.
Modellierung ist eine alte Disziplin mit modernen Konsequenzen
Daten-Warehousing entstand nicht erst mit den Cloud-Plattformen. Die dahinter stehende Architektur reicht Jahrzehnte zurück. Die Geschichte der Data-Warehouse-Architektur führt die Disziplin auf die 1980er Jahre zurück, als der grundlegende Ansatz entwickelt wurde, um operative Daten in Systeme zur Entscheidungsunterstützung zu transformieren. Dieser Wandel gab Unternehmen die Möglichkeit, Daten aus separaten operativen Bereichen zu konsolidieren und für Analysen nutzbar zu machen.
Der Übergang von Mainframe-orientiertem Speicher zu Cloud- und Hybrid-Warehouses veränderte die Implementierungsdetails, beseitigte jedoch nicht den Bedarf an Modellierung. Er erhöhte vielmehr die Anforderungen. Moderne Warehouses müssen mehr Daten, mehr Änderungen und mehr Benutzer aufnehmen und gleichzeitig den historischen Kontext wahren.
Deshalb geraten Teams, die sich direkt auf Datenaufnahme und Dashboards stürzen, oft ins Stocken. Daten zu laden ist nicht dasselbe wie sie zu strukturieren. Ein Warehouse wird erst dann nützlich, wenn das Modell dazu passt, wie das Unternehmen seine Fragen stellt.
Wahl Ihres Entwurfs: Star-, Snowflake- oder Data-Vault-Schema
Am einfachsten lassen sich Modellierungsstile mit der Gestaltung einer Bibliothek vergleichen. Eine Bibliothek ist für schnelles Stöbern eingerichtet. Eine andere ist für eine präzise Kategorisierung organisiert. Eine dritte ist wie ein Archiv aufgebaut, in dem die Bewahrung der Herkunft (Lineage) ebenso wichtig ist wie das Auffinden von Werken.
Warehouse-Modelle gehen dieselben Kompromisse ein.
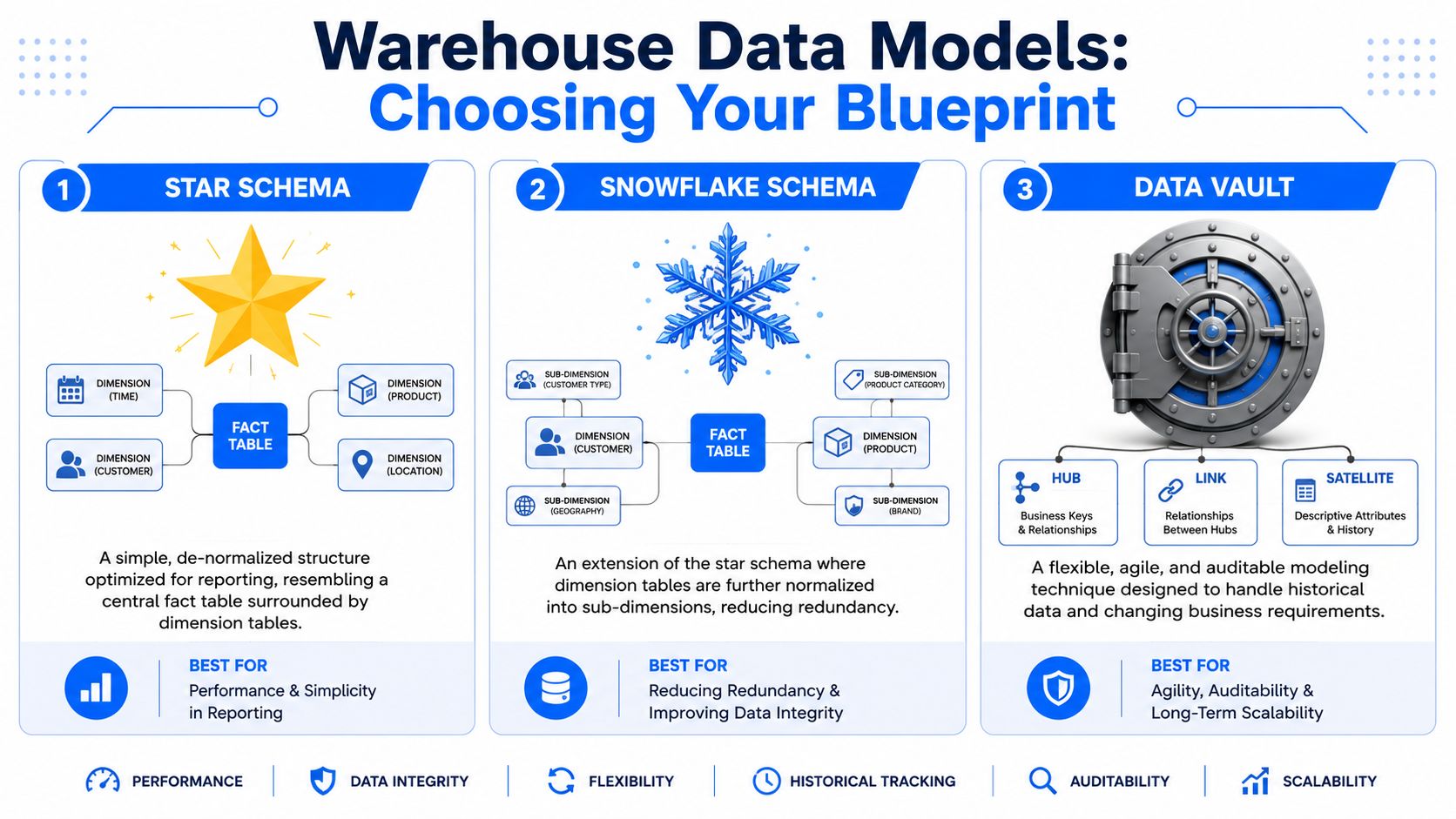
Stellen Sie sich das Modell wie eine Bibliothek vor
Ein Star-Schema entspricht einer stöberfreundlichen Bibliothek. Eine zentrale Faktentabelle enthält messbare Ereignisse wie Bestellungen, Schadensfälle, Seitenaufrufe oder Rechnungen. Dimensionstabellen liefern den Kontext wie Kunde, Produkt, Region und Datum. Es ist leicht zu vermitteln, einfach abzufragen und meist die richtige Wahl, wenn BI die Hauptarbeitslast darstellt.
Ein Snowflake-Schema basiert auf derselben dimensionalen Idee, normalisiert jedoch einige Dimensionen in Unterdimensionen. Die Dimension „Produkt“ kann in Tabellen für Marke, Kategorie und Lieferant aufgeteilt werden. „Geographie“ teilt sich eventuell in Stadt, Region und Land auf. Sie reduzieren Redundanzen, erhöhen jedoch die Komplexität der Joins.
Ein Data Vault ähnelt eher einem Archivsystem. Es trennt stabile Business Keys, Beziehungen und beschreibende Historie in eigenständige Strukturen. Laut ER/Studios Übersicht zu Warehouse-Modellierungsmustern dominiert das Star-Schema bei Anforderungen an Einfachheit und Geschwindigkeit, während Data Vault unschlagbar ist für Unternehmen in sich schnell verändernden Umgebungen mit strengen regulatorischen Anforderungen. Dieselbe Quelle beschreibt Data Vault als eine Struktur bestehend aus Hubs für zentrale Geschäftsentitäten, Links für Beziehungen und Satellites für beschreibende Attribute und Änderungshistorie.
Für Teams, die Optionen visuell entwerfen, kann eine Datenarchitektur-Diagrammreferenz dabei helfen zu verdeutlichen, wie sich diese Muster unterscheiden, sobald man vom Whiteboard zur Implementierung übergeht.
Worauf das jeweilige Pattern optimiert ist
In der Praxis bewährt sich meist Folgendes:
Star-Schema funktioniert am besten, wenn Analysten ein schnelles, vorhersagbares Reporting benötigen und sich das Unternehmen auf klare Fakten und Dimensionen einigen kann.
Snowflake funktioniert am besten, wenn die Wiederverwendbarkeit von Dimensionen und eine stärkere Normalisierung wichtiger sind als die Einfachheit für den Analysten.
Data Vault funktioniert am besten, wenn sich Quellsysteme häufig ändern, Lineage wichtig ist und die Bewahrung der Rohhistorie essenziell ist.
3NF-Modelle eignen sich am besten, wenn Sie operative Genauigkeit in einer zentralen Integrationsschicht benötigen. Meist erfordern sie jedoch eine weitere Präsentationsschicht, bevor die meisten Analysten sie komfortabel nutzen können.
Die Falle besteht darin, Entscheidungen aus ideologischen Gründen zu treffen. Viele Teams wählen Data Vault, weil es nach Enterprise-Klasse klingt, stellen dann aber fest, dass sie für das Reporting immer noch dimensionale Marts benötigen. Andere verflachen alles zu früh in Star-Schemata und bereuen es, wenn sich die vorgelagerten Systeme vierteljährlich ändern.
Star-Schema für Benutzerfreundlichkeit. Snowflake für engere Normalisierung. Data Vault für Anpassungsfähigkeit und Revisionssicherheit.
Eine praxistaugliche Architektur mischt oft verschiedene Muster. Raw- und Core-Schichten bewahren möglicherweise die Quellentreue und Änderungshistorie. Dem Analyse-Bereich zugewandte Marts präsentieren meist ein Star-Schema, da BI-Tools und Analysten damit am besten arbeiten können.
Im Folgenden hilft es, die Kompromisse in der Praxis zu betrachten:
Datenmodellierungsansätze im Vergleich
Kriterium | Star-Schema | Snowflake-Schema | Data Vault |
|---|---|---|---|
Abfrage-Performance | Meist stark bei BI-Abfragen, da die Joins unkompliziert sind | Kann langsamer navigierbar sein, da die Dimensionen stärker normalisiert sind | Stark bei Lineage- und Ingestion-Mustern, aber meist nicht die finale Reporting-Form |
Analysten-Nutzerfreundlichkeit | Hoch. Geschäftsanwender können es schnell verstehen | Mittelmäßig. Mehr Joins und Tabellensprünge erforderlich | Geringer für Self-Service-Nutzer, sofern keine Marts darauf aufgesetzt werden |
Speichereffizienz | Geringer als bei stärker normalisierten Designs | In einigen Dimensionen besser als Star, da Redundanzen reduziert werden | Variiert, meist mehr Tabellen und historische Datensätze |
Flexibilität bei Änderungen | Mittelmäßig | Mittelmäßig | Hoch |
Historische Nachverfolgung | Gut, bei bewusster Modellierung | Gut, bei bewusster Modellierung | Hervorragend per Design |
governance und Revisionssicherheit | Gut, hängt von der Disziplin ab | Gut | Stark |
Implementierungskomplexität | Geringer | Mittel | Hoch |
Die Entscheidung sollte auf Ihrem Workload basieren, nicht auf aktuellen Trends. Wenn Führungskräfte jeden Morgen verlässliche KPI-Dashboards benötigen, beginnen Sie mit der Form, die diese Abfragen vereinfacht. Wenn Regulierungsbehörden, Auditoren oder integrationsintensive Programme das Design vorgeben, optimieren Sie zuerst für Lineage und kontrollierte Änderungen.
Prinzipien für hochperformantes Warehouse-Design
Ein Warehouse-Modell kann verschiedene Muster verwenden und dennoch aus denselben Gründen scheitern. Die typischen Fehlerquellen sind fast immer strategisch: Falsche Granularität, quellenzentriertes Design, unklare Benennungen, fehlende Skalierungspläne oder mangelnde Ownership für Definitionen.

Beginnen Sie mit Geschäftsprozessen, nicht mit Quellsystemen
Das Warehouse sollte abbilden, was das Unternehmen tatsächlich tut: Bestellungen, Lieferungen, Schadensfälle, Zahlungen, App-Sitzungen, Support-Tickets. Wenn das Design mit den Tabellen startet, die zufällig aus Salesforce, SAP oder einer Produktdatenbank eintreffen, übernehmen Sie funktionale Eigenheiten der Applikationen statt reiner Geschäftslogik.
Ich habe eine Regel als besonders zuverlässig erlebt: Definieren Sie zuerst das geschäftliche Ereignis und entscheiden Sie erst danach, wie das Warehouse dieses darstellen wird. Das sorgt dafür, dass Faktentabellen an messbaren, wiederholbaren Vorgängen verankert bleiben.
Ein Warehouse hält länger, wenn seine Kernentitäten eine Systemmigration überstehen.
Design für Leser, Wachstum und Kontrolle
Analysten und BI-Entwickler lesen das Modell. Data Engineers warten das Modell. Governance-Teams tragen das Risikomanagement für das Modell. Ein gutes Design respektiert alle drei Rollen.
Nutzen Sie diese essenzielle Checkliste:
Klarheit vor Raffinesse: Bevorzugen Sie Tabellen- und Spaltennamen, die ein neuer Analyst verstehen kann, ohne fünf Transformationsdateien öffnen zu müssen.
Stabile Granularität: Jede Faktentabelle benötigt eine explizite Definition auf Zeilenebene. Wenn Sie die Granularität nicht in einem Satz erklären können, ist die Tabelle noch nicht bereit.
Skalierbarkeit von Tag eins an: Gehen Sie davon aus, dass Volumen, Parallelität und neue Themenbereiche wachsen werden. Eine nachträgliche Skalierung ist teuer.
Performance-Bewusstsein: Logische Eleganz reicht nicht aus. Wenn gängige Abfragen zu viele Scans und Joins erfordern, werden Benutzer Daten in Tabellenkalkulationen exportieren und das Warehouse umgehen.
Integrierte governance: Zugriffsregeln, Lineage, Qualitätsprüfungen und Eigentumsrechte können nicht auf „später“ verschoben werden.
Auch die Personalauswahl spielt hier eine Rolle. Teams haben oft starke Pipeline-Engineers, aber niemanden, der Modellierung, Platform-Constraints und Business-Semantik verbinden kann. Wenn Sie ein Warehouse-Programm aufbauen oder überarbeiten, kann ein spezialisierter Partner für Cloud Data Architect-Rekrutierung nützlich sein, da sich Architekturfehler meist erst lange nach der Einstellungsentscheidung zeigen.
Das Modell sollte zudem Raum für ein mehrschichtiges Design lassen. Raw-, Staging-, Core-, Analytics- und Aggregate-Schichten lösen jeweils ein anderes Problem. Der Fehler liegt darin, sie zusammenzufassen, weil es sich schneller anfühlt. Anfangs ist es schneller. Danach ist es jeden Monat zäher.
Von Geschäftsfragen zu Warehouse-Schemata
Die besten logischen Modelle entstehen aus unbequemen Gesprächen. Stakeholder fordern oft ein „Umsatz-Dashboard“ oder eine „360-Grad-Kundensicht“, obwohl sie eigentlich Unterstützung für eine Handvoll sehr spezifischer Entscheidungen benötigen. Ihre Aufgabe ist es, Präzision einzufordern, bevor die erste Faktentabelle entworfen wird.

Fragen in Granularität übersetzen
Nehmen Sie eine geschäftliche Frage wie: „Wie hoch war unser monatlicher Produktumsatz nach Region?“
Diese Frage deutet bereits die Struktur an:
Der Geschäftsprozess ist der Verkauf oder die Rechnungsstellung.
Die Kennzahl ist der Umsatz.
Die zeitliche Perspektive ist monatlich.
Die Dimensionen zur Filterung sind Produkt und Region.
Das Modell sollte jedoch nicht direkt mit einer monatlichen Tabelle starten. Die erste Aufgabe besteht darin, die kleinste sinnvolle Granularität zu definieren. Entspricht eine Zeile einer Bestellposition, einer Rechnungsposition, einer Lieferung oder einem täglich zusammengefassten Datensatz? In den meisten Warehouses hält die Wahl des atomarsten, verlässlichsten geschäftlichen Ereignisses den Weg für zukünftige Analysen offen.
Ein praxistauglicher Ablauf sieht so aus:
Befragen Sie Stakeholder für Entscheidungen, nicht für Dashboards: Fragen Sie, welche Aktion aus der Kennzahl folgt. Wenn niemand darauf reagiert, modellieren Sie sie nicht zuerst.
Listen Sie die Kernprozesse auf: Verkäufe, Retouren, Abonnements, Reklamationen, Tickets oder Sensorereignisse werden meist zu separaten Faktendomänen.
Legen Sie die Granularität frühzeitig fest: „Eine Zeile pro Rechnungsposition“ ist verständlich. „Eine Zeile pro Kundentransaktionszusammenfassung“ ist es meistens nicht.
Benennen Sie Dimensionen nach der Geschäftssprache: Kunde, Produkt, Region, Vertriebskanal, Vertriebsmitarbeiter und Datum sind einfacher zu verwalten als quellenspezifische Bezeichnungen.
Klären Sie die Metrik-Semantik vor dem Build: Umsatz, aktive Kunden und Churn sehen oft simpel aus, verbergen jedoch interne weichenstellende Definitionen.
Erfahrungswert: Die meisten Nacharbeiten fallen an, weil Teams die Granularitätsdefinition übersprungen haben und später feststellten, dass eine Tabelle Ereignisse, Snapshots und abgeleitete Daten vermischte.
Ein strukturierter Leitfaden zur Warehouse-Integrationsplanung ist in dieser Phase hilfreich, da die Anbindung von Quellen wichtige Designentscheidungen wie Business Keys, verspätet eintreffende Datensätze und die systemübergreifende Abstimmung beeinflusst.
Der Schritt von Entitäten zu praxistauglichen Schemata
Sobald die Fragen klar sind, bilden Sie die Konzepte zunächst in einem konzeptionellen Modell ab. Halten Sie es geschäftsorientiert: Kunde kauft Produkt. Bestellung gehört zu Region. Rechnung bezieht sich auf Vertrag. Entity-Relationship-Denken hilft bei diesem Prozess, selbst wenn das finale Warehouse kein reines ER-Design sein wird.
Es folgt das logische Modell. Hier definieren Sie Keys, Attribute und Beziehungen so präzise, dass das Engineering sie umsetzen kann. Fakten erhalten Foreign Keys zu Dimensionen. Dimensionen erhalten stabile Identifikatoren und beschreibende Attribute. Gemeinsam genutzte Dimensionen werden harmonisiert (conformed), damit derselbe Kunde oder dasselbe Produkt über alle Marts hinweg dasselbe bedeutet.
Eine gute Review-Sitzung an dieser Stelle stellt Fragen wie:
Review-Frage | Warum es wichtig ist |
|---|---|
Was stellt eine Zeile in dieser Tabelle dar? | Verhindert Verwirrung durch gemischte Granularität |
Welchen Geschäftsprozess bildet sie ab? | Hält Modelle an der Realität verankert |
Welche Dimensionen werden andernorts wiederverwendet? | Unterstützt Harmonisierung und Konsistenz |
Welche Historie muss aufbewahrt werden? | Verhindert destruktives Überschreiben |
Welche Kennzahlen gehören ins Backend statt ins BI-Tool? | Reduziert duplizierte Logik |
Das physische Modell folgt erst danach. Wenn das logische Modell jedoch ungenau ist, wird auch eine physische Optimierung nichts mehr retten.
Physische Implementierung und Performance-Tuning
Ein logisches Design kann absolut vernünftig sein und dennoch schlecht performen, sobald es auf reale Abfragemuster trifft. An diesem Punkt verlässt die Warehouse-Datenmodellierung die konzeptionelle Ebene und wird zum reinen Engineering.
Logische Modelle garantieren keine schnellen Abfragen
Die physische Ebene ist entscheidend, da Engines keine Diagramme ausführen. Sie führen Speicherlayouts, Clustering-Muster, Partition Pruning-Regeln und Materialisierungsstrategien aus. Die physischen Modellierungsrichtlinien für engine-spezifische Designentscheidungen verdeutlichen dies: Das Partitionieren einer Faktentabelle nach Datum kann den Scan-Overhead um 60–80 % reduzieren für Abfragen, die aktuelle Datensätze filtern. Und Clustering auf hochkardinalen Dimensionsschlüsseln kann die Join-Effizienz um bis zu 45 % verbessern in Star-Schema-Implementierungen.
Das verändert die Sicht auf die Implementierung. Eine Faktentabelle mit einem order_date-Filter, der in fast jedem Dashboard vorkommt, sollte physisch so strukturiert sein, dass dieses Zugriffsmuster optimal genutzt wird. Ein Star-Schema, das sich ständig mit customer_id oder einem anderen selektiven Dimensionsschlüssel verbindet, sollte dies im Clustering oder in entsprechenden engine-spezifischen Designs widerspiegeln.
Die praktischen Tuning-Prioritäten sind in der Regel:
Partitionierung auf häufige zeitliche Filter: Wenn Benutzer ständig nach aktuellen Zeiträumen fragen, ist die datumsbasierte Partitionierung oft der erste große Gewinn.
Clustering bei selektiven Joins: Hochkardinale Schlüssel können die Lokalität für wiederholte Joins verbessern.
Gezielte Materialisierung: Nicht jede Transformation sollte ein View bleiben. Häufige Wiederverwendung und teure Joins rechtfertigen oft Tabellenmaterialisierungen.
Trennung der Serving-Schichten von der rohen Ingestion: Rohdaten-Tabellen wahren die Datentreue. Reporting-Tabellen sollten sich nach der Form des Workloads richten.
Für Teams, die sich durch plattformspezifische Tuning-Entscheidungen arbeiten, ist dieser Leitfaden zur Optimierung Ihres Data Warehouses für maximale Effizienz mit modernen Datenqualitätstools eine nützliche Ergänzung zur logischen Designarbeit.
Verlaufshistorie bewusst verwalten
Die historische Nachverfolgung ist einer der ersten Bereiche, in denen sich Abkürzungen beim Design später rächen. Wenn ein Kunde die Region, das Segment oder die Preisstufe wechselt, müssen Sie wissen, ob Berichte den aktuellen Wert oder den Wert zum Zeitpunkt des Ereignisses widerspiegeln sollen.
In dimensionalen Modellen sind Slowly Changing Dimensions vom Typ 2 (SCD2) der Standardmechanismus zur Bewahrung der Historie. Die Grundidee ist einfach: Schließen Sie die alte Dimensionszeile, fügen Sie eine neue ein und nutzen Sie Gültigkeitsdaten oder Gültigkeitsfenster, damit sich Fakten mit der korrekten historischen Version verbinden lassen.
Ein einfaches Muster sieht so aus:
Dieses Muster ist zwar unspektakulär, aber es schützt Trendanalysen, historische Point-in-Time-Berichte und die Revisionssicherheit. Teams, die Dimensionen einfach überschreiben, weil es unkomplizierter erscheint, müssen die historische Logik meist später unter Zeitdruck mühsam rekonstruieren.
Keeping Your Data Model Healthy with Observability
Ein Warehouse-Modell bleibt nicht allein deshalb vertrauenswürdig, weil das ursprüngliche Design gut war. Es verschlechtert sich durch alltägliche operative Änderungen. Ein Quell-Team fügt eine Spalte hinzu. Ein Ingestion-Job läuft verspätet ein. Ein Feld verändert schleichend seine Werte. Ein Join funktioniert technisch weiterhin, aber die geschäftliche Bedeutung verschiebt sich.

Ein Warehouse-Modell baut im Stillen ab
Deshalb gehört Observability in den Lebenszyklus der Warehouse-Datenmodellierung und sollte kein nachträglicher Gedanke sein. Das von Ihnen entworfene Modell ist nur nützlich, wenn es in der Produktion strukturell stabil, zeitgerecht und semantisch vertrauenswürdig bleibt.
Das operative Risiko ist oft größer, als viele Teams zugeben. Die dokumentierten Auswirkungen von Datenqualitätsproblemen auf KI-Systeme zeigen, dass Mängel in der Datenqualität im Schnitt für 15–30 % der Ausfälle von KI-Modellen verantwortlich sind, wobei schleichende Datenveränderungen (Data Drift) und Schema-Änderungen als Hauptursachen gelten. Dieselben Fehlermuster beeinträchtigen Warehouse-Modelle schon lange, bevor sie als KI-Vorfall sichtbar werden. Dashboards zeigen falsche Zahlen. Historische Vergleiche verzerren sich. Nachgelagerte Jobs laufen technisch erfolgreich durch, schlagen jedoch analytisch fehl.
Ein gesundes Warehouse ist nicht das mit dem schönsten Schema – sondern dasjenige, das Ihnen schnell mitteilt, wenn die Realität nicht mehr zum Modell passt.
Was nach dem Go-Live zu überwachen ist
Sobald ein Modell produktiv ist, sind vier Überwachungsbereiche besonders kritisch:
Schemastabilität: Achten Sie auf hinzugefügte oder entfernte Spalten, Typänderungen und umbenannte Felder, die Transformationen ungültig machen oder deren Bedeutung verfälschen können.
Aktualität (Timeliness): Erkennen Sie, wenn erwartete Ladevorgänge verspätet, unvollständig sind oder fehlen, damit veraltete Dashboards nicht mit der Wahrheit verwechselt werden.
Metrikverhalten: Überwachen Sie ungewöhnliche Verschiebungen bei Datenvolumina, Null-Raten, Verteilungen und Beziehungsstrukturen, die von klassischen Pipeline-Checks nicht erfasst werden.
Regelkonformität: Setzen Sie Geschäftsregeln auf Datensatzebene durch, wo Governance- oder Audit-Vorgaben Präzision verlangen.
Moderne Observability-Plattformen beweisen hier ihren Nutzen. Gemäß der verifizierten Plattformbeschreibung kombiniert digna KI-gestützte Anomalieerkennung, Aktualitätsüberwachung, Validierung auf Datensatzebene und Schema-Tracking, während die Analysen direkt in vom Kunden kontrollierten Umgebungen ausgeführt werden. Die Architektur ist für die In-Database-Ausführung, Private-Cloud- oder On-Premises-Infrastrukturen ausgelegt und erfordert keinerlei Datenzugriff durch den Anbieter.
Das ist operativ von großer Bedeutung, da Observability nah am Warehouse ansetzen sollte und nicht darauf basieren darf, sensible Datensätze in ein weiteres Drittanbieter-Tool zu übertragen. Es optimiert auch die Reaktion auf Vorfälle: Statt Probleme erst zu bemerken, wenn der CFO ein Dashboard infrage stellt, können Engineers strukturelle und verhaltensbezogene Abweichungen viel früher abfangen.
Der tiefere Kern ist architektonischer Natur: Ein Warehouse-Modell ist ein lebendes System. Wenn Sie nicht überwachen, ob die Annahmen hinter dem Modell noch zutreffen, haben Sie kein kontrolliertes Warehouse. Sie haben lediglich ein Diagramm und eine Portion Glück.
Modellierung für heute und morgen
Bei der Warehouse-Datenmodellierung geht es nie nur darum, ein Schema-Muster auszuwählen. Es geht darum, Geschäftsfragen, logische Struktur, physische Performance und operatives Vertrauen in ein System zu integrieren, das Veränderungen überstehen kann.
Das eigentliche Ergebnis ist Vertrauen
Erfolgreiche Teams jagen keiner theoretischen Lehrbuch-Reinheit hinterher. Sie gehen bewusste Kompromisse ein. Sie wählen das Star-Schema, wenn Analysten Geschwindigkeit und Klarheit benötigen. Sie nutzen flexiblere Kernmuster, wenn Quellvolatilität und Lineage im Vordergrund stehen. Sie definieren die Granularität frühzeitig, bewahren die Historie gezielt und optimieren die physische Ebene für die tatsächlich ausgeführten Abfragen.
Ebenso wichtig ist es, das Warehouse als pflegebedürftiges System zu betrachten. Modelle verändern sich schleichend. Definitionen weiten sich aus. Plattformen entwickeln sich weiter. Ein Design, das letztes Jahr funktionierte, kann heute zwar noch logisch korrekt, aber operativ instabil sein.
Deshalb betrachten die stärksten Warehouse-Initiativen den gesamten Lebenszyklus: Wählen Sie den passenden Entwurf. Entwickeln Sie für Lesbarkeit und Skalierung. Implementieren Sie für die Realität der Workloads. Überwachen Sie das Modell nach dem Go-Live. Wenn diese Zahnräder ineinandergreifen, wird das Warehouse zu einer dauerhaften Single Source of Truth statt zu einem wiederkehrenden Aufräumprojekt.
Wenn Sie nach einem praktischen Weg suchen, das von Ihnen aufgebaute Warehouse abzusichern, hilft digna Teams dabei, Schema-Änderungen, Datenanomalien, Aktualität und Validierungen direkt in vom Kunden kontrollierten Umgebungen zu überwachen, sodass Datenprobleme erkannt werden, bevor sie Dashboards, Analysen oder nachgelagerte Modelle beeinträchtigen.



