Verantwortlichkeiten von Dateneigentümern: Leitfaden zu den wichtigsten Aufgaben 2026
|
0
min. Lesezeit

Sie haben diesen Moment wahrscheinlich selbst schon erlebt. Ein Executive Dashboard zeigt eine bestimmte Umsatzzahl in der Vorstandsunterlage, eine andere in der Finanzabteilung und eine dritte im BI-Tool, dem Ihr Team am meisten vertraut. Slack füllt sich. Dateningenieure beginnen, Pipelines zu überprüfen. Analysten vergleichen Filter. Jemand fragt, ob die CRM-Synchronisierung fehlgeschlagen ist. Jemand anderes macht die Definitionen verantwortlich.
Meistens liegt das Problem nicht am Dashboard. Es liegt daran, dass niemand mit ausreichender Befugnis den zugrunde liegenden Datensatz von Anfang bis Ende besitzt.
Deshalb sind die Verantwortlichkeiten von Data Ownern so wichtig. Ein Data Owner ist nicht die Person, die jeden fehlerhaften Ladevorgang behebt oder jede Zeile validiert. Der Owner ist die Führungskraft, die entscheidet, was die Daten bedeuten, welche Qualität akzeptabel ist, wer Zugriff erhält, wie lange sie aufbewahrt werden und was passiert, wenn etwas schiefgeht. In modernen Umgebungen funktioniert diese Verantwortung nur, wenn strategische Rechenschaftspflicht mit praktischer Sichtbarkeit in Schemata, Aktualität, Regeln auf Datensatzebene und Anomalien einhergeht.
Inhaltsverzeichnis
Die hohen Kosten nicht zugeordneter Daten
Ein vertrauter Fehler beginnt mit einer einfachen Frage des CEOs. Warum ist die Kundenabwanderung in einem Dashboard gestiegen und in einem anderen gesunken?
Innerhalb einer Stunde befindet sich das Unternehmen im Alarmzustand. BI überprüft die semantische Logik. Das Engineering prüft verspätete Ladevorgänge. Die Finanzabteilung fragt, ob historische Daten neu klassifiziert wurden. Niemand kann die grundlegende Frage schnell beantworten: Wer hat die Befugnis zu sagen, welcher Datensatz der vertrauenswürdige ist, und wer ist dafür verantwortlich, dass dies so bleibt?

So sehen nicht zugeordnete Daten in der Praxis aus. Nicht jedes Mal ein dramatischer Systemausfall, sondern wiederkehrende Unsicherheit. Teams verschwenden Zeit damit, Zahlen abzugleichen, die eigentlich bereits geregelt sein sollten. Entscheidungen verlangsamen sich, weil an jeder wichtigen Kennzahl ein Haftungsausschluss hängen muss. Das Vertrauen erodiert Bericht für Bericht.
Wo der eigentliche Fehler liegt
Wenn die Eigenverantwortung unklar ist, erben technische Teams Entscheidungen, die sie nicht alleine treffen sollten. Ingenieure können Ihnen sagen, dass sich eine Spalte geändert hat. Analysten können Ihnen sagen, dass sich ein KPI unerwartet verändert hat. Sicherheitsteams können Ihnen sagen, dass der Zugriff riskant aussieht. Aber diese Gruppen sollten die geschäftliche Bedeutung, die akzeptable Qualität, die Aufbewahrungsabsicht und die Risikotoleranz nicht ohne einen leitenden Entscheidungsträger definieren.
Praktische Regel: Wenn ein Datensatz eine Entscheidung auf Vorstandsebene, ein Budget oder eine Compliance-Haltung beeinflussen kann, benötigt er einen namentlich genannten Owner mit Befugnissen oberhalb des Bereitstellungsteams.
Die Lücke ist in modernen Daten-Stacks noch größer, da sich viele Fehler nicht ankündigen. Schleichende Veränderungen (Silent Drift), Schemaänderungen und ungewöhnliche Verteilungen können Pipelines passieren, ohne sie zu unterbrechen. Jüngste Branchenanalysen, die von Censinet zitiert werden, weisen darauf hin, dass 60 % der Datenqualitätsprobleme auf Silent Drift und Schemaänderungen zurückzuführen sind, die sich der manuellen Erkennung entziehen, wie in der Diskussion über Lücken bei Data Ownern und Observability-Realitäten in dieser Censinet-Analyse von Ownership-Rollen dargelegt wird.
Das ist das operative Problem, das viele Governance-Modelle immer noch unterschätzen. Sie definieren die Rechenschaftspflicht auf hoher Ebene, sagen den Ownern jedoch nicht, wie sie sich schnell ändernde Datenbedingungen im Alltag überwachen sollen. Wenn Sie die geschäftlichen Auswirkungen dieser Ausfälle abschätzen möchten, ist ein Kalkulator für Datenausfallzeiten (Data Downtime) eine nützliche Methode, um die Diskussion für Führungskräfte verständlich zu machen.
Was Ownership ändert
Ein starker Data Owner reduziert Unklarheiten, bevor Vorfälle passieren. Der Owner trifft die Entscheidung, wofür der Datensatz bestimmt ist, welche Kontrollen am wichtigsten sind und welche Teams die Arbeit ausführen. Das verwandelt Governance von einem vagen Ideal in ein geschäftliches Betriebsmodell.
Nicht zugeordnete Daten erzeugen Meetings. Zugeordnete Daten erzeugen Entscheidungen.
Wer ein Data Owner ist und wer nicht
Ein Data Owner ist eine erfahrene Führungskraft aus dem Geschäftsbereich, die die letztendliche Verantwortung für eine definierte Datendomäne oder einen Datensatz trägt. Von dieser Person wird nicht erwartet, dass sie SQL schreibt, Pipelines optimiert oder Speicher verwaltet. Vom Owner wird erwartet, dass er verbindliche Entscheidungen über Bedeutung, Qualitätserwartungen, Zugriff, Aufbewahrung und Risiken trifft.
Im Data-Ownership-Modell der britischen Regierung ist die Rolle explizit als hochrangige Person mit dedizierten Verantwortlichkeiten definiert. Dasselbe Modell verknüpft Ownership mit rechtlichen und operativen Pflichten und weist darauf hin, dass Verstöße unter der DSGVO zu Geldbußen von bis zu 20 Millionen Euro oder 4 % des weltweiten Jahresumsatzes in den relevanten Fällen führen können, wie im Data-Ownership-Modell der britischen Regierung dargelegt.

Der einfachste Weg, die Rollen zu trennen
Die sauberste Analogie ist Eigentum.
Der Data Owner ist der Hauseigentümer. Er entscheidet, wie die Immobilie genutzt wird, wer Zutritt hat, welches Maß an Instandhaltung akzeptabel ist und wann größere Reparaturen finanziert werden.
Der Data Steward ist der Hausverwalter. Er kümmert sich um die tägliche Qualitätsarbeit, koordiniert Folgemaßnahmen und hält die Betriebsprozesse am Laufen.
Der Data Custodian ist das Instandhaltungsteam. Er betreibt die Infrastruktur, den Speicher, die Backups, die Rechteimplementierung und den Plattformbetrieb.
Der Datennutzer ist der Bewohner oder Besucher. Er nutzt den Raum, verwaltet ihn jedoch nicht.
Diese Unterscheidung ist wichtig, da Unternehmen „Ownership“ oft der Person zuweisen, die dem System am nächsten steht. Das ist meistens falsch. Der Ingenieur betreibt vielleicht die Pipeline. Der Analyst kennt vielleicht den Bericht. Keiner von beiden trägt automatisch die geschäftlichen Konsequenzen von schlechten Definitionen, fehlerhaften Zugriffsentscheidungen oder fehlenden Aufbewahrungsregeln.
Wer kein Data Owner is
Eine Person ist nicht deshalb ein Data Owner, weil sie häufig mit den Daten arbeitet.
Hier sind typische Fehlschlüsse:
Der am stärksten ausgelastete Analyst: Er kennt den KPI, hat aber möglicherweise nicht die Befugnis, Richtlinien festzulegen oder Risiken zu akzeptieren.
Der leitende Ingenieur: Er betreibt die Plattform, sollte aber nicht die geschäftliche Nutzung oder die regulatorische Absicht definieren.
Der Anwendungsadministrator: Er kann Berechtigungen in einem Tool erteilen, aber das bedeutet nicht, dass er entscheiden sollte, wer tatsächlich Zugriff haben sollte.
Eine Führungskraft ohne Bezug zur Domäne: Dienstalter allein reicht nicht aus. Owner benötigen geschäftliche Verantwortung für die Nutzung der Daten.
Der Test ist einfach. Kann diese Person Qualitätsgrenzwerte genehmigen, Streitigkeiten über die Bedeutung beilegen, Abhilfemaßnahmen finanzieren und die Konsequenzen tragen, wenn etwas schiefgeht?
Wenn die Antwort „Nein“ lautet, ist sie nicht der Owner.
Wie gutes Ownership aussieht
Gute Owner sind nah genug am Geschäft, um zu verstehen, warum die Daten existieren, und stehen hierarchisch hoch genug, um bei Kompromissen zu handeln. Sie verstecken sich nicht hinter der Phrase „Das ist ein Problem des Datenteams“. Sie unterstützen Kontrollen, genehmigen Standards und machen Eskalationspfade praktikabel.
Deshalb liegen die stärksten Data-Owner-Verantwortlichkeiten bei Führungskräften in den Bereichen Finanzen, Betrieb, klinische Funktionen, Risiko, Umsatz oder Produkt. Die Rolle ist strategisch, muss aber dennoch mit operativen Nachweisen verknüpft sein.
Die sechs Kernverantwortlichkeiten eines Data Owners
Die Rolle wird überschaubar, wenn man sie in eine Handvoll klarer Pflichten unterteilt. Dies sind die wichtigsten Verantwortlichkeiten eines Data Owners, auf die es in der Praxis ankommt.
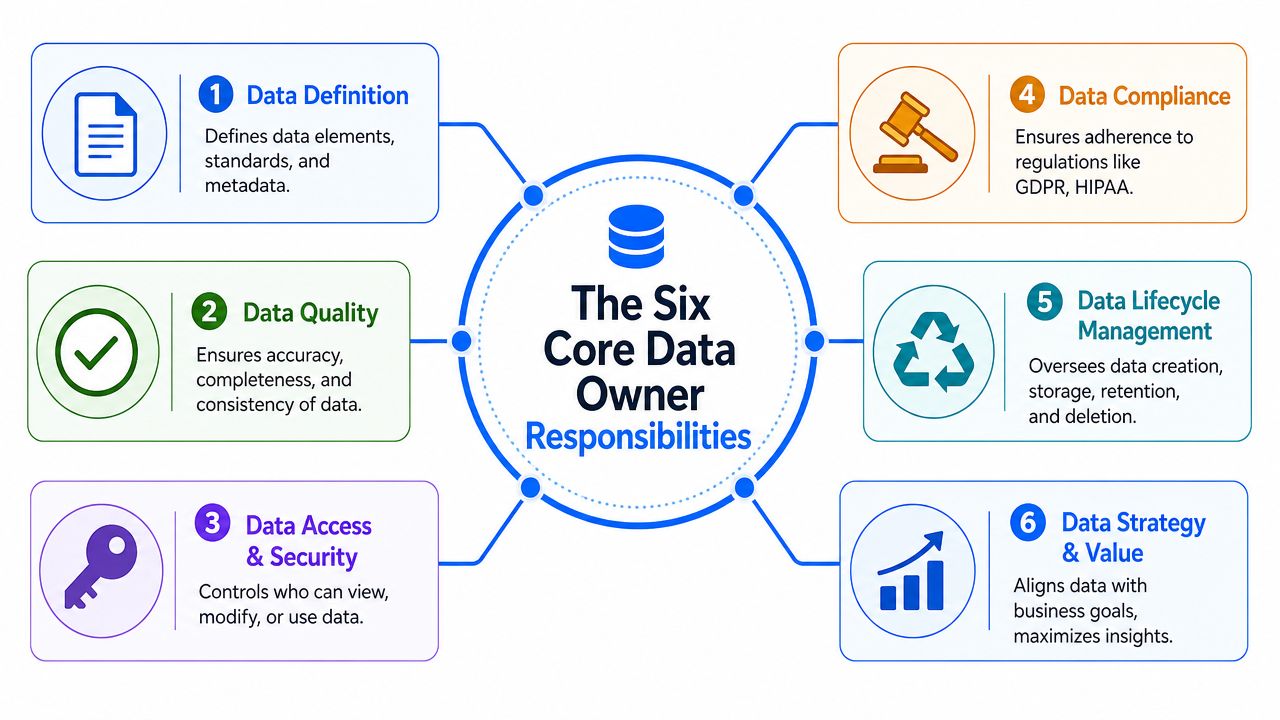
Data Ownership ist auch in einen breiteren Sicherheits- und Compliance-Kontext eingebettet. Wenn Sie einen fundierten Überblick über die flankierenden Kontrollen wünschen, ist dieser DFW-Leitfaden für Datensicherheit und Compliance ein praktischer Begleiter für Führungskräfte, die Governance mit dem Risikomanagement des Unternehmens in Einklang bringen müssen.
Datenqualität
Owner bereinigen Datensätze nicht selbst. Sie definieren, was „gut genug“ bedeutet, und stellen sicher, dass die Teams dies durchsetzen können.
Dazu gehört das Festlegen von Erwartungen an Genauigkeit, Vollständigkeit, Konsistenz und Aktualität. DataSunrise beschreibt in seiner Übersicht über die Rolle des Data Owners in der Governance, dass Owner für die Klassifizierung von Datensätzen, die Festlegung von Datenqualitätsstandards und die Definition von Zugriffsrichtlinien verantwortlich sind, wobei leitende Führungskräfte im Gesundheitswesen unter Rahmenbedingungen wie HIPAA und DSGVO die letztendliche Verantwortung dafür tragen, wie Datensätze geschützt und verwendet werden.
In der Praxis bedeutet gutes Ownership, dass das Business nicht einfach sagt „Macht die Daten besser“. Es sagt stattdessen Dinge wie:
Der Kundenstatus muss mit den genehmigten Geschäftszuständen übereinstimmen
Wichtige Finanzdatensätze dürfen nicht mit fehlenden Pflichtfeldern verbucht werden
Referenzbeziehungen müssen über Quell- und Berichtstabellen hinweg gültig bleiben
Die Erwartungen an die Bereitstellung kritischer Feeds müssen explizit sein
Zugriffsverwaltung
Der Data Owner entscheidet, wer in welchem Umfang und zu welchem Zweck Zugriff erhalten soll.
Das bedeutet nicht, dass Berechtigungseinstellungen in jeder Plattform manuell angeklickt werden müssen. Es bedeutet, rollenbasierte Zugriffsregeln zu genehmigen, zu entscheiden, wann ein breiterer Zugriff gerechtfertigt ist, und sicherzustellen, dass sensible Daten auf autorisierte Benutzer beschränkt bleiben. Ein häufiger Fehler besteht darin, diese Entscheidungen dem technischen Team zu überlassen, das sie am schnellsten umsetzen kann.
Ein praktisches Zugriffsmodell stellt drei Fragen:
Entscheidungsbereich | Was der Owner entscheidet | Was die Teams ausführen |
|---|---|---|
Geschäftlicher Bedarf | Wer Zugriff benötigt und warum | Steward validiert den Kontext der Anfrage |
Berechtigungsumfang | Lesen, Schreiben, Löschen, Exportieren, Admin | Custodian oder Admin wendet Kontrollen an |
Überprüfungszyklus | Wann der Zugriff überprüft werden muss | Governance und Sicherheit verfolgen die Umsetzung |
Compliance und Sicherheit
Die Verantwortung für Compliance kann nicht einfach abgeschoben werden, nur weil technische Kontrollen vorhanden sind. Der Owner muss sicherstellen, dass der Datensatz in Übereinstimmung mit den geltenden Gesetzen, vertraglichen Verpflichtungen und internen Richtlinien behandelt wird.
Das bedeutet zu wissen, ob die Daten regulierte Informationen enthalten, sicherzustellen, dass angemessene Sicherheitsvorkehrungen getroffen wurden, und Nachweise darüber einzufordern, dass die Kontrollen funktionieren. In regulierten Branchen ist dies einer der sichtbarsten Teile der Rolle, da Fehler teuer und öffentlichkeitswirksam sind.
Ein schwaches Kontroll-Framework beginnt meist mit einer schwachen Ownership-Entscheidung, nicht mit einem fehlenden Dashboard.
Datenlebenszyklus-Management
Jeder wichtige Datensatz benötigt einen Lebenszyklus. Wie wird er erstellt, gespeichert, archiviert, aufbewahrt und entsorgt? Wer genehmigt Ausnahmen? Wann sollten historische Daten für die routinemäßige Nutzung nicht mehr verfügbar sein?
Owner sollten Richtlinien für die Aufbewahrung und Entsorgung auf der Grundlage gesetzlicher und geschäftlicher Anforderungen festlegen. Ohne diese behalten Teams entweder alles für immer oder löschen zu radikal. Beides birgt Risiken.
Typische Entscheidungen im Lebenszyklus umfassen:
Aufbewahrungsfristen: Wie lange Daten aus geschäftlichen oder rechtlichen Gründen verfügbar bleiben müssen.
Archivierungsregeln: Wann ältere Daten in kostengünstigere Umgebungen oder solche mit eingeschränktem Zugriff verschoben werden.
Entsorgungsstandards: Wie Daten gelöscht oder stillgelegt werden, wenn sie nicht mehr benötigt werden.
Umgang mit Ausnahmen: Welche Fälle eine Verlängerung der Aufbewahrung oder eine Einschränkung des Löschens rechtfertigen.
Eine kurze Erklärung kann helfen, die operative Seite dieser Entscheidungen zu verankern:
Datenherkunft (Lineage) und Dokumentation
Viele Ownership-Fehler passieren, weil der Owner zwar die Verantwortung trägt, aber keine Sichtbarkeit hat. Wenn Sie nicht zurückverfolgen können, woher die Daten stammen, wie sie sich verändert haben und wo sie verwendet werden, können Sie sie nicht gut verwalten.
Owner sollten eine aktuelle Dokumentation einfordern für:
Geschäftsdefinitionen
Kritische Felder und ihre Bedeutung
Vorgelagerte Quellen (Upstream)
Nachgelagerte Berichte, Modelle und Anwendungen (Downstream)
Bekannte Einschränkungen und Kontrollpunkte
Dies ist keine Dokumentation zum Selbstzweck. Sie ermöglicht es dem Owner, die Auswirkungen zu beurteilen, wenn sich etwas ändert.
Umgang mit Vorfällen (Incident Response)
Der Owner spielt eine entscheidende Rolle, wenn Datenvorfälle auftreten. Er muss die Fehlerursache nicht persönlich diagnostizieren, aber er muss Teil der Entscheidungskette sein, wenn ein Datensatz unzuverlässig, offengelegt, verzögert oder strukturell verändert ist.
Ein guter Umgang mit Vorfällen umfasst:
Bestätigung der geschäftlichen Auswirkungen, damit das Unternehmen weiß, welche Entscheidungen oder Berichte betroffen sind.
Genehmigung von Prioritäten bei der Fehlerbehebung, wenn Teams mehrere Lösungswege haben.
Steuerung der Kommunikation an Stakeholder, die von dem Datensatz abhängen.
Forderung nach präventiven Kontrollen, damit sich derselbe Fehler nicht wiederholt.
Der Owner schließt die Lücke zwischen technischer Wiederherstellung und geschäftlicher Verantwortung. Ohne dies werden Vorfälle nur oberflächlich behoben und treten in leicht veränderter Form wieder auf.
Eine praktische RACI-Matrix für Data Governance
Wenn Ownership in der Theorie klar, in der Praxis jedoch verschwommen ist, hilft eine RACI-Matrix. Sie zwingt ein Team dazu, für jede wiederkehrende Governance-Aufgabe festzulegen, wer Responsible (Zuständig), Accountable (Verantwortlich), Consulted (Konsultiert) und Informed (Informiert) ist.
Diese Unterscheidung ist wichtig. „Responsible“ bedeutet, die Arbeit zu tun. „Accountable“ bedeutet, für das Ergebnis geradezustehen. In gesunden Governance-Modellen ist der Data Owner sehr oft das A, selbst wenn jemand anderes die tägliche Ausführung übernimmt.
Wie man die Matrix liest
Eine nützliche RACI verhindert zwei typische Fehler. Erstens führt sie dazu, dass dieselbe Aufgabe nicht bei drei Teams landet, von denen jedes annimmt, dass ein anderes zuständig ist. Zweitens wird der Owner nicht in das Routinegeschäft hineingezogen, das bei den Stewards oder technischen Teams verbleiben sollte.
Tacto weist darauf hin, dass Data Owner quantifizierbare Grenzwerte für Genauigkeit, Vollständigkeit und Aktualität festlegen müssen. Wenn Owner explizit Validierungsregeln auf Datensatzebene genehmigen, die auf der Geschäftslogik basieren, verzeichnen Unternehmen im Kontext dieses Ownership-Modells eine Verringerung der Reaktionszeit bei Datenvorfällen um 30–40 %, wie in diesem Data-Owner-Glossareintrag von Tacto beschrieben. Wenn Sie einen breiteren betrieblichen Kontext für diese Art von Rollenklarheit wünschen, ist diese Übersicht darüber, was Data Governance ist, eine hilfreiche Referenz.
Praxistipp: Wenn der Data Owner für zu viele technische Aufgaben als „Responsible“ eingetragen ist, stimmt die Matrix nicht. Wenn der Owner bei risikoreichen Aufgaben nicht als „Accountable“ aufgeführt ist, stimmt sie ebenfalls nicht.
Beispiel-RACI für gängige Governance-Aufgaben
Governance-Aufgabe | Data Owner | Data Steward | Data Custodian | Data Engineer |
|---|---|---|---|---|
Geschäftsbedeutung kritischer Felder definieren | A | R | I | C |
Grenzwerte für Datenqualität festlegen | A | R | I | C |
Validierungsregeln auf Datensatzebene genehmigen | A | C | I | R |
Genehmigung von Zugriffsrichtlinien erteilen | A | C | R | I |
Technische Zugriffskontrollen implementieren | I | C | A/R | I |
Pipeline-Ausfälle überwachen | I | C | C | A/R |
Geschäftliche Auswirkungen schlechter Daten bewerten | A | R | I | C |
Richtlinie für Aufbewahrung und Entsorgung genehmigen | A | C | R | I |
Daten gemäß Richtlinie archivieren oder löschen | I | C | A/R | C |
Kommunikation bei Vorfällen koordinieren | A | R | I | C |
Einige Muster sollten beibehalten werden.
Der Owner trägt die Verantwortung für die Geschäftsregeln. Er sollte bei Entscheidungen über Qualität, Zugriff, Aufbewahrung oder Vorfallsauswirkungen nicht optional sein.
Der Steward sorgt für die operative Kontinuität. Diese Rolle hält die Standards im Alltag aufrecht.
Der Custodian ist für die technische Durchsetzung in der Umgebung verantwortlich. Speicher, Systemberechtigungen und Plattformkontrollen liegen hier.
Der Engineer kümmert sich um die Bereitstellungsmechanik. Pipelines, Tests und Laufzeit-Fixes liegen beim Engineering.
Wenn Ihre aktuelle Matrix die Verantwortung dem Team zuweist, das zuerst benachrichtigt wird, haben Sie keine Governance. Sie haben Eskalation durch Erschöpfung.
Wie moderne Observability Data Owner unterstützt
Ein neu ernannter Data Owner stößt meist innerhalb weniger Wochen an dieselbe Grenze. Die Richtlinie ist unterzeichnet, die Domäne zugewiesen, und das erste schwerwiegende Problem kommt dennoch überraschend. Eine Kennzahl im Vorstand ist falsch, ein regulatorischer Auszug verspätet sich oder ein Produktteam verwendet ein Feld, dessen Bedeutung sich vor drei Releases geändert hat. Die Rechenschaftspflicht verbleibt beim Owner, selbst wenn die Warnzeichen tief in den Pipeline-Protokollen und verstreuten Team-Dashboards vergraben waren.
Das ist die operative Lücke, die moderne Observability schließt. Sie bietet Data Ownern eine praktische Möglichkeit zu sehen, ob die von ihnen genehmigten Kontrollen in der Produktion noch greifen – und das über Systeme hinweg, die sie niemals manuell inspizieren würden.
Warum Dashboards allein die Rechenschaftspflicht des Owners nicht lösen
Dashboards melden Ergebnisse. Data Ownership erfordert frühere Signale.
Ein Dashboard kann anzeigen, dass die gestrige Kennzahl erfolgreich geladen wurde, und dennoch übersehen, dass wichtige Datensätze sechs Stunden zu spät eintrafen, ein Join nach einer Schemaänderung Zeilen verlor oder eine Verteilungsverschiebung die Zahl technisch zwar vollständig, operativ jedoch irreführend machte. Bis das Problem in einem Vorstandsbericht auftaucht, befindet sich der Owner bereits im Krisenmodus.
Owner benötigen eine Überwachung, die geschäftliche Verpflichtungen widerspiegelt und nicht nur den Systemzustand. Sie benötigen Nachweise, die an die von ihnen genehmigten Richtlinien gekoppelt sind, z. B. Aktualitätsstandards, Qualitätstoleranzen, Zugriffserwartungen und risikoreiche Strukturänderungen. In Private-Cloud- und On-Premises-Umgebungen wird diese Anforderung noch schwieriger, da Governance-Teams oft nicht von einem breiten anbieterseitigen Zugriff auf Produktionsdaten ausgehen können. Egnyte erörtert diese Grenzen der Kontrolle in seinem Leitfaden für Data Ownership. Die praktische Konsequenz ist eindeutig. Observability muss in der Umgebung funktionieren, die das Unternehmen betreibt, nicht in derjenigen, die sich ein Tool-Anbieter wünscht.
Was leistungsfähige Observability ändert
Gute Observability liefert dem Owner brauchbare Nachweise an den Punkten, an denen Governance normalerweise scheitert.
Anomalieerkennung: Owner benötigen eine automatisierte Erkennung von ungewöhnlichem Datenvolumen, Null-Werten, Werteverteilungen und anderen Änderungen, die für die geschäftliche Nutzung relevant sind. Eine manuelle Grenzwertanpassung lässt sich bei einem großen Portfolio an Datensätzen nicht skalieren, insbesondere wenn sich normales Verhalten im Laufe der Zeit verschiebt. Diese Art der Überwachung spiegelt sich in dignas Anomalieerkennungsfunktion (Data Anomalies) wider.
Aktualitätsüberwachung: Daten können fehlerfrei sein und dennoch ein geschäftliches Risiko darstellen, wenn sie zu spät für Finanz-, Betriebs- oder Compliance-Zwecke eintreffen. Aktualitätsprüfungen sollten das tatsächliche Übertragungsverhalten mit den erwarteten Zeitplänen und gelernten Mustern vergleichen, wie in der Übersicht zur Aktualitätsüberwachung von digna beschrieben.
Schema-Tracking: Eine Spalte, die hinzugefügt, entfernt, umbenannt oder im Typ geändert wird, kann die nachgelagerte Logik zerstören, lange bevor ein geschäftlicher Nutzer erklären kann, was schiefgelaufen ist. Kontinuierliches Struktur-Tracking hilft Ownern dabei, Änderungen zu erkennen, die eine Richtlinienentscheidung, eine Ausnahme oder einen Kommunikationsplan erfordern. Diese Funktion wird in der Erweiterung für Schema-Tracking und -Validierung von digna beschrieben.
Validierung auf Datensatzebene: Viele Governance-Fehler liegen unterhalb der Dashboard-Ebene. Eindeutigkeit über mehrere Spalten hinweg, referenzielle Integrität, bedingte Regeln und Prüfungen auf Zeilenebene entscheiden oft darüber, ob ein Datensatz vertrauenswürdig ist oder zu Audit-Feststellungen und operativem Nacharbeitsaufwand führt. Diese Kontrollen wurden im Plattform-Release von digna mit Validierungsfunktionen hervorgehoben.
Der praktische Nutzen liegt nicht in mehr Warnmeldungen, sondern in einer besseren Triage.
Eine starke Observability-Infrastruktur hilft dem Owner, vier Fragen schnell zu beantworten. Was hat sich geändert? Welcher Geschäftsprozess ist gefährdet? Wurde ein Richtliniengrenzwert überschritten? Wer muss als Nächstes handeln? Ohne diese Antworten führt Rechenschaftspflicht zu routinemäßiger Eskalation und verzögerten Entscheidungen.
Sie hilft auch dabei, zwei Konzepte zu trennen, die oft vermischt werden. Qualität definiert die Standards. Observability zeigt, ob diese Standards unter realen Betriebsbedingungen eingehalten werden – auch bei Fehlern, für die im Vorfeld keine Regel geschrieben wurde. Dieser Vergleich von Data Observability vs. Datenqualität ist eine nützliche Kurzreferenz für diese Unterscheidung.
Für Data Owner ist dieser Unterschied entscheidend. Die Strategie formuliert die Erwartung. Observability zeigt, ob die Erwartung dem Kontakt mit produktiven Systemen standhält.
Eine Enterprise-Checkliste zur Implementierung von Data Ownership
Ein neuer Data Owner wird meist nach einem Berichtsfehler, einem Audit-Problem oder einem kundenwirksamen Datenvorfall ernannt. Das ist üblich. Der schwierigere Teil beginnt am nächsten Tag, wenn der Titel zwar existiert, Entscheidungsrechte, Kontrollen und Überwachung jedoch noch fehlen.
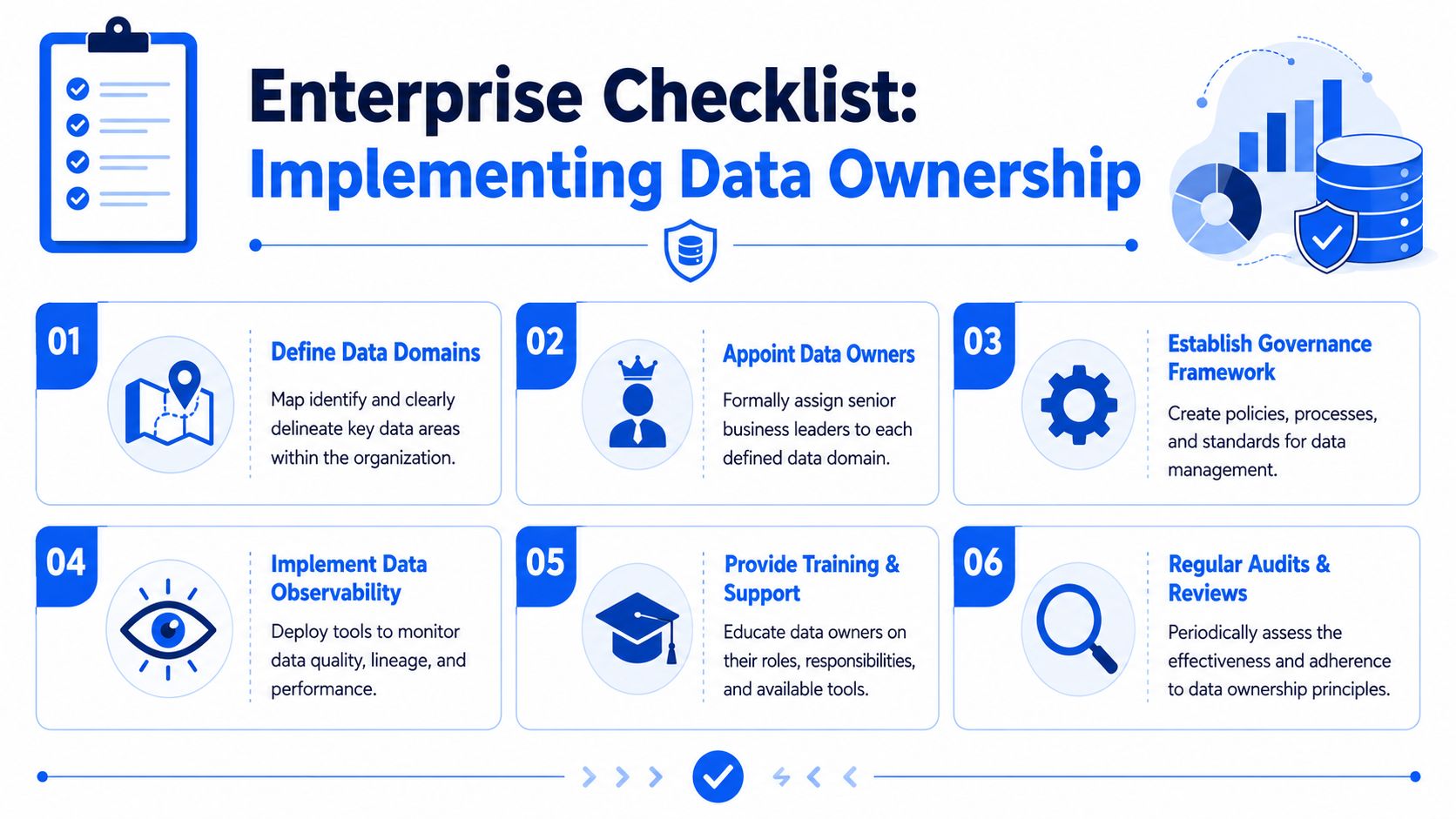
Ownership wird erst dann real, wenn das Unternehmen dem Owner einen definierten Bereich, klare Befugnisse und verwertbare Erkenntnisse an die Hand gibt. Ohne dies verkommt die Rolle zu einem Namen auf einer Präsentationsfolie, während die operativen Teams weiterhin fragmentierte Entscheidungen treffen.
Was zuerst eingerichtet werden sollte
Nutzen Sie diese Checkliste, um ein Ownership-Modell aufzubauen, das dem täglichen Betriebsdruck standhält.
Datendomänen klar definieren. Beginnen Sie mit den Datensätzen, die mit Berichten für die Geschäftsführung, regulierten Prozessen, dem Kundenbetrieb oder der Umsatzrechnung verknüpft sind. Halten Sie die Grenzen so präzise, dass ein einziger Owner Entscheidungen ohne Überschneidungen oder ständige Abstimmungen treffen kann.
Führungskräfte formal als Data Owner einsetzen. Weisen Sie die Rolle der Führungskraft zu, die Kompromisse genehmigen, Abhilfemaßnahmen finanzieren und die Konsequenzen schlechter Datenentscheidungen tragen kann. Technische Leiter, Stewards und Plattformteams unterstützen die Rolle, sollten aber standardmäßig keine geschäftliche Verantwortung tragen.
Richtlinien dokumentieren, die der Owner genehmigen soll. Konzentrieren Sie sich auf Qualitätsgrenzwerte, Zugriffsregeln, Aufbewahrungserwartungen und die Eskalation von Vorfällen. Es geht nicht um Bürokratie. Es geht darum, dem Owner einen klaren Standard an die Hand zu geben, an dem er sich orientieren kann, wenn ein Team eine Ausnahme beantragt oder ein Audit-Trail benötigt wird.
Eine funktionierende RACI erstellen. Halten Sie sie praxisnah. Wer genehmigt den Zugriff? Wer legt Qualitätsgrenzwerte fest? Wer untersuchet Fehler? Wer kommuniziert geschäftliche Auswirkungen? Wenn diese Antworten immer noch davon abhängen, wer am Meeting teilnimmt, ist Ownership noch nicht etabliert.
Observability zuerst auf die risikoreichsten Domänen anwenden. Data Owner sind für die Ergebnisse verantwortlich, benötigen aber dennoch operative Nachweise. Beginnen Sie dort, wo verspätete Pipelines, Schema-Drift, fehlgeschlagene Validierungen oder unbemerkte Anomalien die Compliance, die Finanzberichterstattung oder das Kundenerlebnis beeinträchtigen würden. Das ist die Verbindung zwischen strategischer Verantwortung und operativer Kontrolle.
Einen Überprüfungszyklus für Ownership-Zuweisungen festlegen. Reorganisationen, Systemmigrationen, Akquisitionen und neue Vorschriften können ein Ownership-Modell, das einst sinnvoll war, hinfällig machen. Überprüfen Sie den Domänenumfang, die ernannten Owner und die Eskalationspfade in einem festen Rhythmus, anstatt auf einen Ausfall zu warten.
Der Kompromiss liegt auf der Hand. Ein schlankes Modell lässt sich schneller einführen, lässt die Owner jedoch meist im Dunkeln, wenn Vorfälle Systeme oder Teams überschreiten. Ein strengeres Modell erfordert mehr Aufwand bei der Einrichtung, bietet dem Unternehmen jedoch eine klare Verantwortlichkeitskette und eine praktische Möglichkeit zu überwachen, ob die Kontrollen greifen.
Ein reifes Programm erwartet von Data Ownern nicht, dass sie Pipelines persönlich inspizieren oder Validierungsregeln selbst schreiben. Es gibt ihnen Richtlinienkompetenz, zuverlässige Berichte über den Zustand ihrer Domänen und einen klaren Weg, um Maßnahmen einzuleiten, wenn Risiken einen Grenzwert überschreiten.
Wenn Sie ein pragmatisches Ownership-Modell aufbauen und eine Observability-Lösung benötigen, die in Private-Cloud- oder On-Premises-Umgebungen ohne anbieterseitigen Zugriff auf Produktionsdaten funktioniert, lohnt sich ein Blick auf digna. Sie unterstützt Anomalieerkennung, Validierung auf Datensatzebene, Schema-Tracking und Aktualitätsüberwachung in vom Kunden kontrollierten Umgebungen. Dies erleichtert es Data Ownern, ihrer Verantwortung gerecht zu werden, ohne die tägliche technische Überwachung selbst übernehmen zu müssen.



