Opanowanie modelowania danych magazynowych: pojęcia i produkcja
|
0
min. czyt.

Twoje pulpity nawigacyjne (dashboards) ładują się, ale nikt im nie ufa. Dział finansowy twierdzi, że przychody się nie zgadzają. Dział operacyjny widzi brakujące rekordy. Analitycy spędzają więcej czasu na wyjaśnianiu, dlaczego dany wskaźnik się zmienił, niż na doradzaniu, co z tym zrobić. Zazwyczaj jest to moment, w którym zespoły zdają sobie sprawę, że hurtownia danych nie zawodzi z powodu składni SQL czy narzędzi BI. Zawodzi, ponieważ model leżący u podstaw hurtowni nigdy nie stał się trwałym systemem.
Dobre modelowanie danych w hurtowni przekształca rozproszone dane operacyjne w coś, co ludzie mogą badać, rozumieć i czemu mogą ufać. Decyduje również o tym, jak bolesne będą późniejsze zmiany. Model, który wygląda czysto na diagramie, może nadal lec w gruzach pod wpływem późno docierających danych, niejasnych definicji, powolnych złączeń (joins) i dryfu schematu (schema drift). Model działający na produkcji musi przetrwać wszystkie te obciążenia jednocześnie.
Spis treści
Dlaczego modelowanie danych w hurtowni to fundament Twojej analityki
Kiedy zespół mówi „nasze dane są nieuporządkowane”, problem leży zazwyczaj w strukturze. Tabele odzwierciedlają zachowanie aplikacji, a nie znaczenie biznesowe. Wskaźniki są obliczane na trzy różne sposoby. Historyczne zmiany są nadpisywane, więc nikt nie potrafi odpowiedzieć na pytanie, jak wyglądał klient, produkt lub umowa w danym momencie w przeszłości.
W tym miejscu kluczowe znaczenie ma modelowanie danych w hurtowni. Daje ono analitykom stabilny język biznesowy. Zamiast łączyć surowe zamówienia, rekordy klientów, faktury i dzienniki statusów za każdym razem, gdy ktoś potrzebuje raportu, hurtownia zapewnia trwałe encje, spójne złączenia (joins) i uzgodnione definicje.

Zaufanie psuje się wcześniej niż potoki danych (pipelines)
Potok danych może zakończyć się sukcesem, a mimo to dostarczyć błędne analizy. Dane mogą dotrzeć na czas, ale model wciąż może ukrywać duplikaty, nieprawidłowo spłaszczać relacje lub usuwać historię potrzebną użytkownikom końcowym do analizy trendów i audytów.
Praktyczna konsekwencja jest prosta. Słabe modele generują kłótnie. Dobre modele generują decyzje.
Zasada praktyczna: Jeśli użytkownik biznesowy potrzebuje inżyniera danych, aby ten wyjaśnił mu każde złączenie w pulpicie nawigacyjnym, model jest wciąż zbyt blisko systemów źródłowych.
Solidny model hurtowni danych realizuje jednocześnie trzy zadania:
Tworzy spójność: Definicje klientów, produktów i przychodów przestają się zmieniać między poszczególnymi pulpitami.
Obsługuje analizę historyczną: Zespoły mogą odpowiedzieć nie tylko na pytanie, co jest prawdą teraz, ale także, co było prawdą w określonym czasie.
Poprawia łatwość utrzymania: Inżynierowie mogą dodawać nowe źródła i wskaźniki bez konieczności ponownego przepisywania całej warstwy analitycznej.
Modelowanie to stara dyscyplina o nowoczesnych konsekwencjach
Hurtownie danych nie pojawiły się wraz z platformami chmurowymi. Stojąca za nimi architektura ma już dziesięciolecia. Definiując historię architektury hurtowni danych, genezę tej dyscypliny datuje się na lata 80. XX wieku, kiedy to opracowano podstawowe podejście do przekształcania danych operacyjnych w systemy wspomagania decyzji. Ta zmiana dała organizacjom możliwość konsolidacji danych z różnych obszarów operacyjnych i uczynienia ich użytecznymi do analizy.
Przejście od systemów mainframe do chmurowych i hybrydowych hurtowni danych zmieniło szczegóły wdrożeniowe, ale nie wyeliminowało potrzeby modelowania. Wręcz podniosło stawkę. Nowoczesne hurtownie muszą przetwarzać więcej danych, obsługiwać częstsze zmiany i wspierać większą liczbę użytkowników, jednocześnie zachowując kontekst historyczny.
Dlatego zespoły, które spieszą się bezpośrednio do etapu pozyskiwania danych (ingestion) i tworzenia pulpitów, często stają w miejscu. Ładowanie danych to nie to samo co ich organizowanie. Hurtownia staje się użyteczna tylko wtedy, gdy jej model odpowiada sposobowi, w jaki biznes zadaje pytania.
Wybór schematu: Gwiazda, Płat Śniegu lub Data Vault
Najprostszym sposobem na wyjaśnienie stylów modelowania jest porównanie ich do projektowania biblioteki. Jedna biblioteka jest zorganizowana pod kątem szybkiego przeglądania. Inna pod kątem precyzyjnej kategoryzacji. Trzecia budowana jest jak archiwum, gdzie zachowanie pochodzenia (lineage) danych ma takie samo znaczenie jak ich wyszukiwanie.
Modele hurtowni danych dokonują takich samych kompromisów.
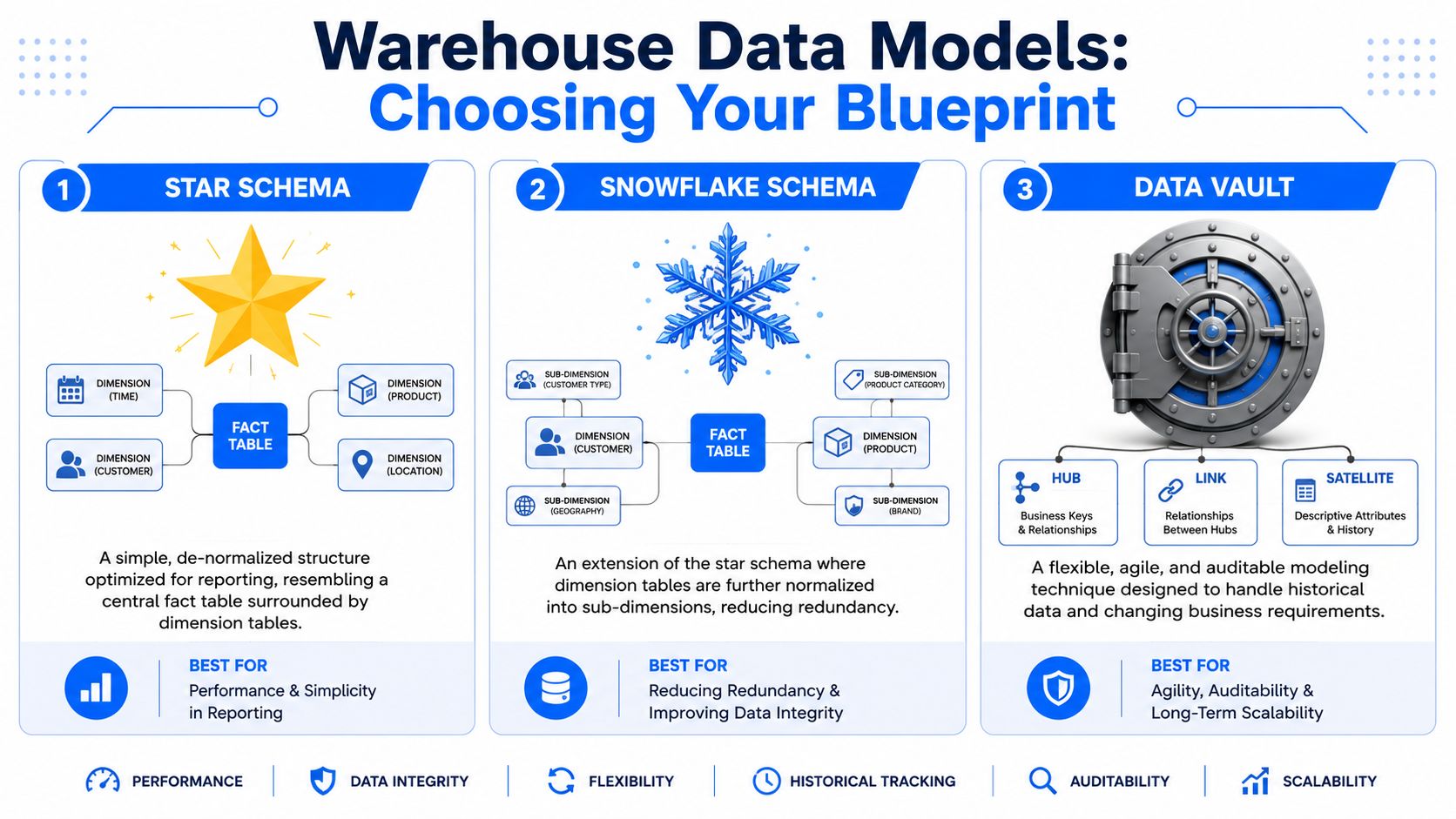
Pomyśl o modelu jak o bibliotece
Schemat Gwiazdy (Star Schema) to biblioteka przyjazna dla przeglądających. Jedna centralna tabela faktów przechowuje mierzalne zdarzenia, takie jak zamówienia, roszczenia, odsłony stron lub faktury. Tabele wymiarów dostarczają kontekstu, takiego jak klient, produkt, region i data. Jest on łatwy do nauki, łatwy do zapytania i zazwyczaj stanowi właściwy wybór, gdy głównym obciążeniem pracy jest BI.
Schemat Płatka Śniegu (Snowflake Schema) wychodzi z tego samego założenia wymiarowego, ale normalizuje niektóre wymiary do podwymiarów. Produkt może dzielić się na tabele marek, kategorii i dostawców. Geografia może dzielić się na miasto, region i kraj. Zmniejsza to nadmiarowość danych, ale zwiększa złożoność połączeń (joins).
Data Vault jest bliższy systemowi archiwalnemu. Rozdziela stabilne klucze biznesowe, relacje i historię opisową na odrębne struktury. Zgodnie z omówieniem wzorców modelowania hurtowni od ER/Studio, Schemat Gwiazdy dominuje przy wymaganiach dotyczących prostoty i szybkości, podczas gdy Data Vault jest niezrównany dla przedsiębiorstw działających w szybko zmieniających się środowiskach i mających rygorystyczne wymagania regulacyjne. To samo źródło opisuje Data Vault jako strukturę składającą się z hubs (piast) dla kluczowych podmiotów gospodarczych, links (łączy) dla relacji oraz satellites (satelitów) dla atrybutów opisowych i historii zmian.
Dla zespołów szkicujących opcje wizualnie pomocny może być referencyjny diagram architektury danych, który wyjaśnia różnice między tymi wzorcami po przejściu z tablicy do fazy wdrożenia.
Pod jakim kątem optymalizowany jest dany wzorzec
Oto co zazwyczaj sprawdza się w praktyce.
Schemat Gwiazdy sprawdza się najlepiej, gdy analitycy potrzebują szybkiego, przewidywalnego raportowania, a biznes może zorganizować się wokół jasnych faktów i wymiarów.
Schemat Płatka Śniegu sprawdza się najlepiej, gdy powtórne użycie wymiarów i ściślejsza normalizacja mają większe znaczenie niż prostota dla analityka.
Data Vault sprawdza się najlepiej, gdy systemy źródłowe często się zmieniają, pochodzenie danych ma znaczenie, a zachowanie surowej historii jest kluczowe.
Modele 3NF pasują najlepiej, gdy potrzebujesz wierności operacyjnej w podstawowej warstwie integracyjnej, ale zazwyczaj wymagają kolejnej warstwy prezentacji, aby większość analityków mogła z nich wygodnie korzystać.
Pułapką jest dokonywanie wyboru na podstawie ideologii. Wiele zespołów wybiera Data Vault, ponieważ brzmi to profesjonalnie z perspektywy korporacyjnej, a potem okazuje się, że do raportowania i tak potrzebują wymiarowych martów danych (dimensional marts). Inne zespoły zbyt wcześnie spłaszczają wszystko do gwiazd i żałują tego, gdy systemy źródłowe zmieniają się co kwartał.
Gwiazda dla użyteczności. Płat Śniegu dla ściślejszej normalizacji. Data Vault dla elastyczności i audytowalności.
Praktyczna architektura często miesza te wzorce. Warstwy surowe (raw) i bazowe (core) mogą zachowywać wierność źródeł i historię zmian. Martsy przeznaczone dla analityków mogą nadal prezentować schemat gwiazdy, ponieważ z tego wzorca najchętniej korzystają narzędzia BI i analitycy.
W dalszej części warto przyjrzeć się tym kompromisom w praktyce:
Porównanie podejść do modelowania danych
Kryterium | Schemat Gwiazdy | Schemat Płatka Śniegu | Data Vault |
|---|---|---|---|
Wydajność zapytań | Zazwyczaj wysoka dla zapytań BI, ponieważ złączenia są proste | Może być wolniejszy w nawigacji, ponieważ wymiary są bardziej znormalizowane | Wysoka pod kątem pochodzenia danych i wzorców ładowania, ale zazwyczaj nie jest to finalny kształt raportowania |
Użyteczność dla analityków | Wysoka. Użytkownicy biznesowi mogą go szybko zrozumieć | Umiarkowana. Więcej złączeń i przeskakiwania między tabelami | Niska dla użytkowników końcowych (self-service), chyba że zbudujesz na nim martsy danych |
Wydajność pamięci masowej | Niższa niż w bardziej znormalizowanych projektach | Lepsza niż w gwieździe w niektórych wymiarach dzięki redukcji nadmiarowości | Różna, często z większą liczbą tabel i zapisów historycznych |
Elastyczność na zmiany | Umiarkowana | Umiarkowana | Wysoka |
Śledzenie historii | Dobre przy celowym modelowaniu | Dobre przy celowym modelowaniu | Doskonałe z założenia |
Zarządzanie (governance) i audytowalność | Dobre, zależy od dyscypliny zespołu | Dobre | Silne |
Złożoność wdrożenia | Niższa | Średnia | Wysoka |
Decyzja powinna wynikać z charakteru Twoich obciążeń pracy, a nie z panującej mody. Jeśli kadra zarządzająca potrzebuje zaufanych pulpitów KPI każdego ranka, zacznij od struktury, która ułatwia te zapytania. Jeśli projekt jest napędzany przez regulatorów, audytorów lub programy o silnej integracji, zoptymalizuj pod kątem pochodzenia danych i kontrolowanej zmiany.
Zasady projektowania wydajnych hurtowni danych
Model hurtowni może wykorzystywać różne wzorce, a i tak zawieść z tych samych powodów. Typowe punkty krytyczne mają prawie zawsze charakter strategiczny: niewłaściwa ziarnistość (grain), projekt skupiony na źródłach, niejasne nazewnictwo, brak planu na rozwój, brak własności nad definicjami.

Zacznij od procesów biznesowych, nie od systemów źródłowych
Hurtownia powinna modelować to, co robi organizacja. Zamówienia. Wysyłki. Roszczenia. Płatności. Sesje w aplikacji. Zgłoszenia serwisowe. Jeśli projekt zaczyna się od tabel, które akurat dotarły z Salesforce, SAP czy bazy produktowej, dziedziczysz dziwactwa aplikacji zamiast logiki biznesowej.
Uważam jedną zasadę za szczególnie niezawodną: najpierw zdefiniuj zdarzenie biznesowe, a dopiero potem zdecyduj, jak hurtownia je zaprezentuje. Dzięki temu tabele faktów są zakorzenione w czymś mierzalnym i powtarzalnym.
Hurtownia danych przetrwa dłużej, jeśli jej podstawowe encje przetrwają migrację systemu.
Projektuj z myślą o odbiorcach, rozwoju i kontroli
Analitycy i deweloperzy BI są odbiorcami modelu. Inżynierowie danych są jego opiekunami. Zespoły ds. governance są właścicielami ryzyka związanego z modelem. Dobry projekt szanuje potrzeby wszystkich trzech grup.
Użyj tego jako niezbędnej listy kontrolnej:
Jasność ponad spryt: Wybieraj nazwy tabel i kolumn, które nowy analityk zrozumie bez otwierania pięciu plików transformacji.
Stabilna ziarnistość (grain): Każda tabela faktów potrzebuje wyraźnej definicji na poziomie rekordów. Jeśli nie potrafisz opisać ziarnistości w jednym zdaniu, tabela nie jest gotowa.
Skalowalność od pierwszego dnia: Załóż, że wolumen, współbieżność i nowe obszary tematyczne będą rosły. Dostosowywanie skali po fakcie jest kosztowne.
Świadomość wydajności: Logiczna elegancja to za mało. Jeśli powszechne zapytania wymagają nadmiernego skanowania i złączeń, użytkownicy wyeksportują dane do arkuszy kalkulacyjnych i będą omijać hurtownię.
Wbudowane zarządzanie (governance): Reguły dostępu, pochodzenie danych, kontrole jakości i własność nie mogą być odkładane na „później”.
Skład zespołu również ma tutaj znaczenie. Zespoły często mają świetnych inżynierów od potoków danych, ale brakuje im kogoś, kto potrafi połączyć modelowanie, ograniczenia platformy i semantykę biznesową. Jeśli budujesz lub przebudowujesz program hurtowni danych, wyspecjalizowany partner w zakresie rekrutacji Cloud Data Architect może okazać się bardzo pomocny, ponieważ błędy architektoniczne zazwyczaj dają o sobie znać na długo po podjęciu decyzji o zatrudnieniu.
Model powinien również zostawiać przestrzeń na projektowanie warstwowe. Warstwy Raw, Staging, Core, Analytics i Aggregate rozwiązują różne problemy. Błędem jest spłaszczanie ich w jedną tylko dlatego, że wydaje się to szybsze. Na początku jest to szybsze. Z każdym kolejnym miesiącem jest jednak coraz wolniejsze.
Od pytań biznesowych do schematów hurtowni danych
Najlepsze modele logiczne zaczynają się od trudnych rozmów. Interesariusze często proszą o „pulpit sprzedaży” lub „customer 360”, kiedy w rzeczywistości potrzebują wsparcia dla kilku bardzo konkretnych decyzji. Twoim zadaniem jest wymuszenie precyzji, zanim zaprojektowana zostanie choćby jedna tabela faktów.

Przekształć pytania w ziarnistość (grain)
Weźmy pytanie biznesowe takie jak: „Jakie były nasze miesięczne przychody z produktów według regionów?”
To pytanie już wskazuje na strukturę:
Proces biznesowy to sprzedaż lub fakturowanie.
Miara to przychód.
Perspektywa czasowa jest miesięczna.
Wymiary filtrujące to produkt i region.
Jednak model nie powinien od razu przechodzić do tabeli miesięcznej. Pierwszym zadaniem jest zdefiniowanie najniższej użytecznej ziarnistości (grain). Czy jeden wiersz odpowiada pozycji zamówienia, pozycji faktury, wysyłce czy dziennemu podsumowaniu? W większości hurtowni wybór najbardziej atomowego, wiarygodnego zdarzenia biznesowego pozostawia otwartą drogę dla przyszłych analiz.
Praktyczna sekwencja wygląda następująco:
Rozmawiaj o decyzjach, nie o pulpitach nawigacyjnych: Zapytaj, jakie działanie nastąpi po analizie danego wskaźnika. Jeśli nikt na jego podstawie nie podejmuje działań, nie modeluj go w pierwszej kolejności.
Wypisz kluczowe procesy: Sprzedaż, zwroty, subskrypcje, roszczenia, zgłoszenia czy zdarzenia z czujników zazwyczaj stają się osobnymi obszarami faktów.
Zadeklaruj ziarnistość na wczesnym etapie: Definicja „jeden wiersz na pozycję faktury” jest jasna. „Jeden wiersz na podsumowanie transakcji klienta” zazwyczaj taka nie jest.
Nazwij wymiary językiem biznesu: Klient, produkt, region, kanał, przedstawiciel handlowy i data są łatwiejsze do kontrolowania niż etykiety specyficzne dla danego systemu źródłowego.
Rozstrzygnij semantykę wskaźników przed budową: Przychód, aktywny klient i odpływ (churn) słyną z tego, że wyglądają na proste, a kryją w sobie wiele niuansów decyzyjnych.
Notatka z terenu: Większość poprawek wynika z tego, że zespoły pominęły definicję ziarnistości i później odkryły, że jedna tabela mieszała zdarzenia, migawki (snapshots) oraz wyliczone podsumowania.
Przejrzysty przewodnik planowania integracji hurtowni danych jest niezwykle pomocny na tym etapie, ponieważ wdrażanie nowych źródeł wpływa na kluczowe wybory projektowe, takie jak klucze biznesowe, późno docierające rekordy i spójność w systemach.
Przejdź od encji do wykonalnych schematów
Gdy pytania są już jasne, najpierw odwzoruj te koncepcje na **modelu pojęciowym** (conceptual model). Zachowaj podejście biznesowe. Klient kupuje produkt. Zamówienie należy do regionu. Faktura odnosi się do umowy. Myślenie w kategoriach encji i relacji wspomaga ten proces, nawet jeśli docelowa hurtownia nie będzie czystym projektem ER.
Kolejny krok to **model logiczny** (logical model). To w nim definiujesz klucze, atrybuty i relacje z precyzją, która pozwoli inżynierom na wdrożenie. Fakty otrzymują klucze obce do wymiarów. Wymiary zyskują stabilne identyfikatory i atrybuty opisowe. Współdzielone wymiary stają się ujednolicone (conformed), aby ten sam klient lub produkt oznaczał to samo we wszystkich marts.
Dobra sesja przeglądowa na tym etapie obejmuje pytania takie jak:
Pytanie kontrolne | Dlaczego to ma znaczenie |
|---|---|
Co reprezentuje wiersz w tej tabeli? | Zapobiega zamieszaniu z mieszaną ziarnistością |
Jaki proces biznesowy reprezentuje? | Utrzymuje modele zakotwiczone w rzeczywistości |
Które wymiary są używane w innych miejscach? | Wspiera zgodność i spójność |
Jaka historia musi zostać zachowana? | Zapobiega destrukcyjnemu nadpisywaniu |
Które wskaźniki powinny być wyliczane wcześniej, a które w BI? | Redukuje duplikowanie logiki |
Model fizyczny powstanie później. Ale jeśli model logiczny jest niejasny, żadna optymalizacja fizyczna go nie uratuje.
Implementacja fizyczna i dostrajanie wydajności
Projekt logiczny może być całkowicie sensowny, a mimo to działać słabo, gdy napotka realne wzorce zapytań. W tym momencie modelowanie danych w hurtowni przestaje być tylko teorią, a staje się inżynierią.
Modele logiczne nie gwarantują szybkich zapytań
Warstwa fizyczna ma znaczenie, ponieważ silniki bazodanowe nie wykonują diagramów. Wykonują układy przechowywania danych, wzorce klasteryzacji, reguły przycinaniapartycji (partition pruning) oraz strategie materializacji. Wskazówki dotyczące modelowania fizycznego pod kątem konkretnych silników bazy obrazują to bardzo konkretnie: partycjonowanie tabeli faktów według daty może zmniejszyć narzut skanowania o 60–80% w przypadku zapytań filtrujących ostatnie rekordy, a klasteryzacja na kluczach wymiarów o wysokiej kardynalności może poprawić wydajność złączeń nawet o 45% w implementacjach schematu gwiazdy.
To zmienia podejście do wdrożenia. Tabela faktów z filtrem na order_date, używanym w prawie każdym pulpicie nawigacyjnym, powinna być fizycznie zorganizowana tak, aby wykorzystać ten wzorzec dostępu. Schemat gwiazdy, który stale łączy się po customer_id lub innym selektywnym kluczu wymiaru, powinien odzwierciedlać to w strukturze klasteryzacji lub innych mechanizmach specyficznych dla używanego silnika.
Praktyczne priorytety dostrajania to zazwyczaj:
Partycjonowanie po wspólnych filtrach czasowych: Jeśli użytkownicy stale pytają o ostatnie okresy, partycjonowanie oparte na dacie jest zazwyczaj pierwszym krokiem do sukcesu.
Klasteryzacja wokół selektywnych złączeń: Klucze o wysokiej kardynalności mogą poprawić lokalność danych dla powtarzających się złączeń.
Świadoma materializacja: Nie każda transformacja powinna pozostać perspektywą (view). Częste użycie i kosztowne złączenia często uzasadniają materializację do tabeli.
Oddzielenie warstwy serwującej od surowego ładowania: Tabele surowe zachowują wierność. Tabele raportowe powinny odpowiadać specyfice obciążenia.
Dla zespołów pracujących nad dostrajaniem specyficznym dla danej platformy, ten przewodnik po optymalizacji hurtowni danych pod kątem maksymalnej wydajności z nowoczesnymi narzędziami jakości danych stanowi użyteczne uzupełnienie prac nad projektem logicznym.
Świadome zarządzenie historią danych
Śledzenie historii to jeden z pierwszych elementów, w których pójście na skróty szybko generuje koszty. Jeśli klient zmieni region, segment lub próg cenowy, musisz wiedzieć, czy raporty powinny odzwierciedlać wartość bieżącą, czy wartość z momentu zaistnienia zdarzenia.
W modelach wymiarowych standardowym mechanizmem zachowania historii są **Powoli Zmieniające Się Wymiary Typu 2 (Type 2 Slowly Changing Dimensions)**. Podstawowa idea jest prosta: zamknij stary wiersz wymiaru, wstaw nowy i używaj dat obowiązywania lub okien ważności, aby fakty łączyły się z poprawną wersją historyczną.
Prosty schemat wygląda następująco:
Ten wzorzec może nie jest spektakularny, ale chroni analizę trendów, raportowanie historyczne i audytowalność. Zespoły, które nadpisują wymiary dla prostoty, zazwyczaj kończą na odbudowywaniu logiki historycznej od nowa pod presją czasu.
Utrzymanie kondycji modelu danych dzięki Observability
Model hurtowni nie zachowa wiarygodności tylko dlatego, że początkowy projekt był solidny. Degraduje się on poprzez codzienne zmiany operacyjne. Zespół zajmujący się źródłem doda kolumnę. Zadanie ładowania danych opóźni się. Pole zacznie dryfować w subtelny sposób. Połączenie (join) wciąż działa, ale znaczenie biznesowe ulega przesunięciu.

Model hurtowni danych degraduje się po cichu
To jest powód, dla którego Observability powinno być integralną częścią cyklu życia modelowania hurtowni danych, a nie rzeczą dodawaną na samym końcu. Zaprojektowany model jest użyteczny tylko pod warunkiem, że pozostaje stabilny strukturalnie, aktualny i wiarygodny semantycznie na produkcji.
Ryzyko operacyjne jest większe, niż przyznaje wiele zespołów. Raporty omawiające wpływ problemów z jakością danych na systemy AI wskazują, że problemy te odpowiadają średnio za 15–30% błędów modeli AI, do czego najbardziej przyczyniają się cichy dryf danych i zmiany schematów. Te same błędy wpływają na modele hurtowni na długo przed tym, jak przełożą się na incydent w systemie AI. Pulpity się psują. Porównania historyczne dają błędne wyniki. Zadania na kolejnych etapach kończą się sukcesem od strony technicznej, ale zawodzą analitycznie.
Zdrowa hurtownia to nie ta z najładniejszym schematem. To ta, która szybko poinformuje Cię, gdy rzeczywistość przestanie pasować do modelu.
Co monitorować po wdrożeniu produkcyjnym
Gdy model działa już na produkcji, cztery kategorie monitorowania stają się ważniejsze niż cała reszta.
Stabilność schematu: Śledź dodawanie bądź usuwanie kolumn, zmiany typów danych i zmiany nazw pól, które mogą unieważnić transformacje lub zmienić ich znaczenie.
Aktualność (Timeliness): Wiedz, kiedy oczekiwane ładowania są opóźnione, pominięte lub niekompletne, aby nie pomylić przestarzałych informacji na pulpitach z rzeczywistością.
Zachowanie wskaźników: Monitoruj nietypowe zmiany wolumenów, współczynnika wartości pustych (null rates), rozkładów i wzorców relacji, których nie wyłapią standardowe testy potoków danych.
Zgodność z regułami (Compliance): Wymuszaj ograniczenia biznesowe na poziomie rekordów wszędzie tam, gdzie ład korporacyjny (governance) lub wymogi audytowe wymagają precyzji.
Nowoczesne platformy klasy Observability udowadniają swoją wartość. Zgodnie ze zweryfikowanym opisem platformy, digna łączy oparte na sztucznej inteligencji wykrywanie anomalii, monitorowanie aktualności, walidację na poziomie rekordów i śledzenie schematów, wykonując analizy wewnątrz środowisk kontrolowanych przez klienta. Jej architektura została zaprojektowana z myślą o uruchamianiu bezpośrednio w bazie danych, wdrożeniach w chmurze prywatnej lub lokalnej (on-premises) i braku dostępu dostawcy do danych klienta.
Ma to znaczenie operacyjne, ponieważ Observability powinno znajdować się blisko hurtowni danych, a nie zależeć od przesyłania wrażliwych zbiorów danych do kolejnego narzędzia zewnętrznego. Zmienia to również reakcję na incydenty. Zamiast odkrywać problemy po tym, jak dyrektor finansowy zakwestionuje dane na pulpicie, inżynierowie mogą wychwycić błędy strukturalne i behawioralne znacznie wcześniej.
Głębszy sens ma charakter architektoniczny. Model hurtowni to żywy zasób. Jeśli nie monitorujesz, czy założenia stojące za modelem są nadal aktualne, nie masz tak naprawdę zarządzanej (governed) hurtowni danych. Masz tylko diagram i trochę szczęścia.
Modelowanie na dziś i jutro
Modelowanie danych w hurtowni to nigdy nie jest tylko kwestia wyboru wzorca schematu. Chodzi o spójne połączenie pytań biznesowych, struktury logicznej, wydajności fizycznej i operacyjnego zaufania w jeden system, który poradzi sobie ze zmianami.
Prawdziwym produktem końcowym jest zaufanie
Zespoły, które robią to dobrze, nie popadają w podręcznikowy dogmatyzm. Dokonują świadomych kompromisów. Wybierają schemat Gwiazdy, gdy analitycy potrzebują szybkości i jasności. Korzystają z bardziej elastycznych wzorców bazowych (core), gdy zmienność źródła i pochodzenie danych mają kluczowe znaczenie. Definiują ziarnistość na wczesnym etapie, celowo dbają o historię i dostrajają warstwę fizyczną pod kątem zapytań uruchamianych przez użytkowników.
Co równie ważne, traktują hurtownię danych jako coś, co wymaga ciągłej opieki. Modele dryfują. Definicje się rozszerzają. Platformy ewoluują. Projekt, który działał w zeszłym roku, może być poprawny logicznie, ale kruchy operacyjnie.
Dlatego najlepsze programy hurtowni danych uwzględniają pełen cykl życia. Wybierz właściwy plan. Buduj z myślą o czytelności i skali. Wdrażaj pod kątem realiów obciążeń pracy. Monitoruj model po uruchomieniu produkcyjnym. Kiedy te elementy współpracują, hurtownia danych staje się trwałym źródłem prawdy, a nie powracającym projektem ratunkowym.
Jeśli szukasz praktycznego sposobu na ochronę hurtowni, którą już zbudowałeś, digna pomaga zespołom monitorować zmiany schematów, anomalie danych, aktualność i walidację bezpośrednio w środowiskach kontrolowanych przez klienta, dzięki czemu problemy wychodzą na jaw, zanim uszkodzą pulpity nawigacyjne, analitykę czy modele na kolejnych etapach.




Poznaj zespół tworzący platformę
Zespół z Wiednia, składający się z ekspertów od AI, danych i oprogramowania, wspierany rygorem akademickim i doświadczeniem korporacyjnym.