Architektura potoków danych: kompletny przewodnik na rok 2026
|
0
min. czyt.

Raport wyglądał dobrze o godzinie 8:00 rano. Do 9:15 dział finansowy zdążył go już wykorzystać na spotkaniu. Przed porze lunchu ktoś zauważył, że sumy się nie zgadzają, nie z powodu błędnego kodu SQL, ale dlatego, że jedna z tabel źródłowych przestała otrzymywać podzbiór rekordów w nocy. Nie uruchomił się żaden alert. Pipeline technicznie „działał”. Pulpit nawigacyjny serwował nieaktualne zaufanie.
Z takim właśnie trybem awarii boryka się obecnie wiele organizacji. Nie dramatyczne przerwy w działaniu. Cicha korupcja danych. Brakujący plik, zmiana schematu, transformacja która wciąż się wykonuje, ale teraz mapuje niewłaściwe pole, opóźniona porcja danych, która zamienia świeży wskaźnik KPI w wczorajszą informację. Gdy tak się dzieje, zaufanie spada szybciej, niż wskaże to jakikolwiek wskaźnik systemowy.
Solidna architektura pipeline'u danych naprawia więcej niż tylko przesył danych ze źródła do celu. Decyduje o tym, czy operatorzy ufają platformie danych w warunkach stresu, czy analitycy potrafią wyjaśnić liczby bez zgadywania i czy dane wejściowe modeli pozostają stabilne w miarę rozwoju systemów źródłowych. Najtrudniejszą częścią nie jest rysowanie diagramów. Jest nią takie zaprojektowanie pipeline'u, aby jakość, terminowość i widoczność istniały od pierwszego schematu, a nie dopiero po pierwszej eskalacji ze strony kadry zarządzającej.
Zespoły pracujące z mieszanymi danymi wejściowymi napotykają ten problem jeszcze wyraźniej, gdy do przepływu trafiają dokumenty półstrukturyzowane. Jeśli Twój pipeline obejmuje ekstrakcję dokumentów dla zastosowań AI, warto zapoznać się z tym praktycznym przewodnikiem po konwertowaniu plików PDF pod kątem modeli LLM, ponieważ błędy w strukturze dokumentów często zaczynają się na długo przed rozpoczęciem modelowania. Jako wizualny punkt odniesienia pokazujący, jak te systemy współdziałają, prosty diagram architektury danych pozwoli ujednolicić koncepcję zanim przejdziesz do narzędzi.
Spis treści
Twój przewodnik po nowoczesnej architekturze pipeline'ów danych
Integracja jakości danych i Observability na etapie projektowania
Praktyczna lista kontrolna dla Twojego następnego pipeline'u
Twój przewodnik po nowoczesnej architekturze pipeline'ów danych
Użyteczna definicja architektury pipeline'ów danych jest prosta: to operacyjny plan zbierania, modyfikowania, przechowywania i dostarczania danych bez utraty ich znaczenia po drodze. Brzmi to prosto, dopóki nie przejmiesz systemu, w którym pobieranie, transformacje, harmonogramy, przechowywanie i pulpity nawigacyjne były budowane w różnym czasie przez różne zespoły.
W praktyce architektura ujawnia się w schematach awarii. Kruchy projekt sprawia, że zespoły boją się cokolwiek zmienić. Słabe przekazywanie danych między pobieraniem a transformacją pozwala zniekształconym rekordom przejść do dalszych etapów. Warstwa raportowania bez określonych oczekiwań co do świeżości danych uczy biznes ręcznego wykrywania problemów. Żadnego z tych problemów nie rozwiąże dodanie kolejnego orchestratora czy jeszcze jednego pulpitu nawigacyjnego.
Architektura musi również odzwierciedlać rzeczywisty sposób pracy ludzi. Analitycy chcą stabilnych tabel. Zespoły platformowe chcą powtarzalnego wdrażania. Inżynierowie ML chcą danych wejściowych, które nie ulegają niezauważonym zmianom. Zespoły ds. bezpieczeństwa chcą, aby dane pozostały w kontrolowanych środowiskach. Nowoczesny plan musi zadowolić ich wszystkich, nie stając się labiryntem.
Niezawodne pipeline'y to nie te, które nigdy nie ulegają awarii. To te, które ulegają awariom w sposób, który operatorzy mogą szybko dostrzec, odizolować i naprawić.
Właśnie dlatego najlepsze projekty traktują pipeline mniej jak hydraulikę, a bardziej jak system produkcyjny. Każdy etap ma właściciela. Każda zależność jest widoczna. Każda ścieżka dostarczania ma określone oczekiwania dotyczące terminowości i poprawności. Jeśli budujesz z takimi założeniami, pozostałe decyzje stają się znacznie prostsze.
Four Pillars of a Data Pipeline
Najprostszym sposobem na wytłumaczenie projektowania pipeline'ów jest użycie analogii do kuchni. Składniki trafiają od dostawców, są bezpiecznie przechowywane, przygotowywane przez kucharzy i ostatecznie serwowane gościom. Jeśli jakikolwiek krok zawiedzie, klienta nie obchodzi, które stanowisko nawaliło. Wie tylko, że posiłek jest spóźniony lub niesmaczny.

Myśl jak o linii operacyjnej
Wersja techniczna opiera się na czterech praktycznych filarach:
Ingestion (Pobieranie) pobiera dane z systemów źródłowych. Mogą to być interfejsy API, transakcyjne bazy danych, narzędzia SaaS, strumienie zdarzeń lub zrzuty plików.
Storage (Przechowywanie) utrzymuje surowe lub przetworzone dane w trwałym miejscu, często na platformach takich jak Amazon S3, Snowflake lub Databricks.
Processing (Przetwarzanie) przekształca dane w użyteczną formę. Obejmuje czyszczenie, deduplikację, filtrowanie, formatowanie i łączenie (joins).
Serving (Udostępnianie) prezentuje wyniki na pulpitach nawigacyjnych, w narzędziach Reverse ETL, modelach, aplikacjach lub dla odbiorców końcowych.
Jedno z najbardziej przejrzystych nowoczesnych podsumowań pochodzi z wyjaśnienia firmy Striim dotyczącego komponentów nowoczesnych pipeline'ów danych, które opisuje rdzeń jako pobieranie, transformację i przechowywanie, oraz zauważa, że błędy w transformacji prowadzą bezpośrednio do nieaktualnych raportów i niedziałających pulpitów nawigacyjnych, gdy zniekształcone dane dotrą do warstwy konsumpcji. Wciąż wydzielam udostępnianie (serving) jako osobny aspekt architektoniczny, ponieważ wiele zespołów buduje pipeline, ale niedostatecznie projektuje punkt przekazania danych ludziom i systemom, które z nich korzystają.
Gdzie zespoły najczęściej popełniają błędy
Błędy rzadko zdarzają się na skrajnych etapach. Pojawiają się w punktach przejścia.
Oto kilka powtarzających się przykładów:
Surowe dane trafiają bez weryfikacji kontraktów. Pipeline przyjmuje rekordy, ale nikt nie sprawdza, czy kluczowe pola nie są puste lub czy mają właściwy typ danych.
Przechowywanie staje się śmietniskiem. Zespoły zachowują każdą wersję każdego pliku, ale nie rozróżniają stref przejściowych, uporządkowanych i gotowych dla odbiorców.
Transformacje stają się monolitem. Jedno gigantyczne zadanie obsługuje całą logikę, więc debugowanie jednego wskaźnika wymaga analizy całej infrastruktury.
Udostępnianie jest traktowane „tylko jako BI”. W rzeczywistości to tutaj powinny być zachowane spójność semantyczna, oczekiwania dotyczące świeżości oraz wzorce dostępu.
Praktyczna zasada: Jeśli odbiorca nie potrafi odpowiedzieć, skąd wzięła się dana liczba, Twoja warstwa udostępniania nie jest ukończona.
Dobra architektura utrzymuje każdy z filarów na tyle niezależnym, by mógł działać osobno, ale na tyle połączonym, by błędy nie ukrywały się między nimi. Ta separacja sprawia, że późniejsze decyzje dotyczące wzorców, odporności i Observability stają się uporządkowane, a nie chaotyczne.
Kluczowe wzorce architektoniczne pipeline'ów danych
Wzorce architektoniczne to obszar, w którym zespoły popełniają kosztowne błędy, ponieważ każda opcja sprawdza się świetnie w określonym scenariuszu. Błędny wybór zwykle nie wynika ze „złej technologii”. Jest to niedopasowanie między wymaganiami dotyczącymi opóźnień, złożonością operacyjną a rodzajem analiz, których potrzebuje biznes.
ETL i ELT rozwiązują różne problemy
ETL sprawdza się w środowiskach, w których transformacja musi nastąpić przed zapisaniem danych w miejscu docelowym. Jest to powszechne, gdy czyszczenie źródła jest rygorystyczne, zasoby obliczeniowe miejsca docelowego są ograniczone lub wymogi regulacyjne (Compliance) wymagają kontroli przed załadowaniem.
ELT działa lepiej, gdy platforma docelowa jest stworzona do ciężkiego przetwarzania, a zespoły chcą mieć elastyczność po załadowaniu danych. Hurtownie i jeziora danych (lakehouses) uczyniły ten wzorzec znacznie bardziej praktycznym, ponieważ można szybko zapisać dane, a następnie ustrukturyzować je za pomocą transformacji opartych na języku SQL.
Żaden z tych wzorców nie jest uniwersalnie lepszy. ETL zapewnia ściślejszą kontrolę przed pobraniem danych. ELT daje większą elastyczność zespołom analitycznym. Jeśli oceniasz narzędzia dla początkowego etapu pipeline'u, to omówienie oprogramowania do pobierania danych jest przydatnym miejscem do porównania, jak decyzje o przechwytywaniu ze źródeł wpływają na resztę stosu technologicznego.
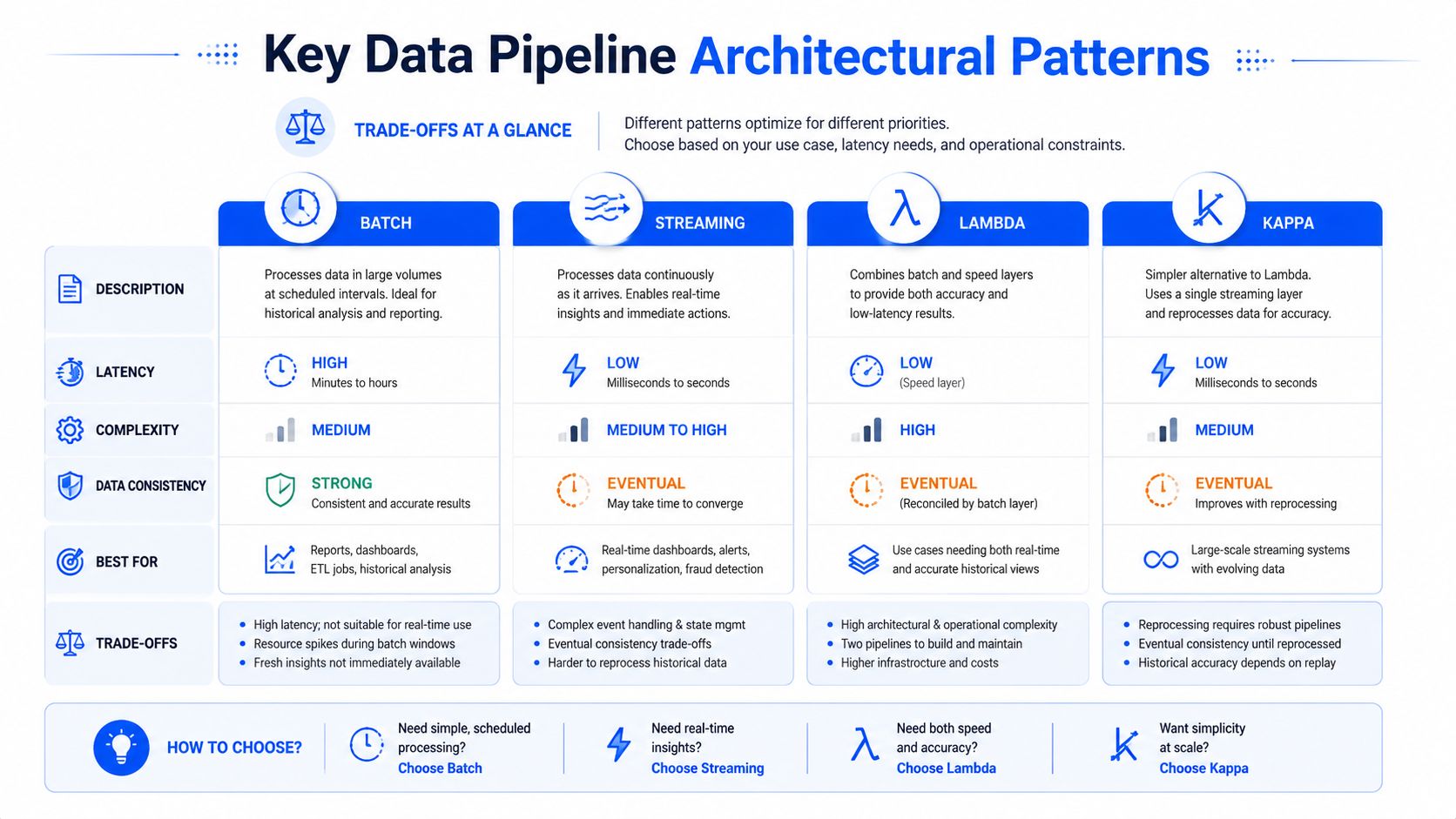
Przetwarzanie wsadowe, strumieniowe, lambda i kappa
Wybór między przetwarzaniem wsadowym a strumieniowym to bardziej brzemienna w skutki decyzja.
Przetwarzanie wsadowe (batch) to lepszy wybór, gdy biznes akceptuje zaplanowany harmonogram dostarczania, a pipeline musi spójnie przetwarzać duże historyczne zbiory danych. Klasycznym przykladem są raporty finansowe na koniec dnia. Przetwarzanie strumieniowe (streaming) jest przeznaczone do sytuacji, w których opóźnienie osłabia sens samego zastosowania, takich jak operacyjny monitoring, alerty lub przepływy pracy sterowane zdarzeniami.
Formy hybrydowe mają znaczenie, gdy potrzebujesz obu rozwiązań. Artykuł firmy Striim na temat wzorców architektury Lambda i Kappa dobrze oddaje te różnice. Architektura Lambda równoważy szybkość czasu rzeczywistego z niezawodnością przetwarzania wsadowego poprzez uruchamianie równoległych przepływów danych. Ścieżka szybka (hot path) obsługuje przesył strumieniowy w czasie rzeczywistym, ścieżka wolna (cold path) obsługuje przetwarzanie historyczne, a warstwa udostępniania łączy wyniki. Architektura Kappa eliminuje osobną warstwę wsadową i obsługuje zarówno przetwarzanie w czasie rzeczywistym, jak i historyczne za pomocą pojedynczego pipeline'u strumieniowego, co upraszcza operacje poprzez eliminację podwójnych systemów.
Uproszczenie to brzmi atrakcyjnie, ale Kappa wiąże się z realnym kompromisem. Ponowne przetwarzanie historii strumienia przez jeden pipeline jest eleganckie tylko wtedy, gdy Twoje narzędzia, strategia retencji i dyscyplina operacyjna są wystarczająco silne, aby bezpiecznie wspierać ponowne odtwarzanie danych.
Porównanie wzorców pipeline'ów danych
Wzorzec | Główne zastosowanie | Zalety | Wady |
|---|---|---|---|
Wsadowy (Batch) | Zaplanowana analityka i cykliczne raporty | Przewidywalny, dobry dla dużych zadań historycznych, łatwiejszy do zrozumienia | Wyższe opóźnienia, gorzej nadaje się do natychmiastowych reakcji operacyjnych |
Strumieniowy (Streaming) | Zastosowania sterowane zdarzeniami i widoczność niemal w czasie rzeczywistym | Niskie opóźnienia, doskonały do alertów i operacji na żywo | Trudniejsza obsługa błędów, odtwarzanie i zarządzanie stanem |
Lambda | Zespoły potrzebujące zarówno głębi historycznej, jak i natychmiastowych informacji | Łączy w sobie niezawodność przetwarzania wsadowego i szybkość czasu rzeczywistego | Dwie ścieżki do zbudowania, przetestowania i utrzymania |
Kappa | Środowiska zorientowane na streaming, które chcą jednego modelu przetwarzania | Prostszy model operacyjny niż systemy z dwiema ścieżkami | Krytyczna staje się strategia ponownego odtwarzania i dyscyplina strumieniowa |
Bank może stosować przetwarzanie wsadowe do raportowania regulacyjnego (Compliance), strumieniowe do wykrywania sygnałów oszustw, a wzorzec hybrydowy tam, gdzie aktywność klienta wymaga natychmiastowej reakcji, ale również uzgodnienia historycznego. I o to właśnie chodzi. Wybierz wzorzec dopasowany do okna decyzyjnego, a nie ten, który wygląda najnowocześniej na slajdzie prezentacji.
Budowanie niezawodnych pipeline'ów
Najwięcej problemów sprawiają zazwyczaj te pipeline'y, które „działały dobrze”, dopóki nie zmieniły się realia biznesowe. Pojawia się nowe źródło. Zostaje zmieniona nazwa pola. Jeden zespół dodaje logikę dla pulpitów nawigacyjnych, inny dodaje funkcje ML i nagle jedna awaria unieruchamia trzy niepowiązane ze sobą produkty wyjściowe, ponieważ wszystko żyje wewnątrz tego samego kruchego łańcucha.

Modularność jako cecha przetrwania
Projektowanie modułowe to nie kwestia stylu. To zabezpieczenie przed tym, by drobna zmiana nie przerodziła się w poważną awarię.
Artykuł Monte Carlo na temat modułowej i zautomatyzowanej architektury pipeline'ów bezpośrednio wskazuje na kluczową kwestię: niezawodne pipeline'y muszą być modułowe i zautomatyzowane, a niemodułowe projekty prowadzą do destabilizujących zmian, przez które zespoły zaczynają obawiać się wprowadzania jakichkolwiek modyfikacji. Ten opis jest bolesno trafny. Gdy ludzie obawiają się zmieniać pipeline, jakość zaczyna się pogarszać, ponieważ znane problemy pozostają nierozwiązane dłużej niż powinny.
Praktyczna konstrukcja modułowa obejmuje zazwyczaj:
Jednostki pobierania dopasowane do źródeł, które mogą ulec awarii lub zostać odtworzone niezależnie.
Warstwy transformacji z jasnymi kontraktami, dzięki czemu logika etapowania, ujednolicania i logika biznesowa nie zlewają się w jeden krok.
Testy jakości wielokrotnego użytku, które są powiązane bezpośrednio z modułem, zamiast istnieć w osobnym arkuszu kalkulacyjnym.
Automatyzację wdrożeń, dzięki czemu wydania są powtarzalne, a wycofanie zmian nie wymaga heroicznego wysiłku.
Testowanie pochodzenia danych (lineage) i wykonanie równoległe
Kolejnym punktem krytycznym jest brak świadomości zależności. Zespołom wydaje się, że wiedzą, które procesy korzystają z danej tabeli, dopóki nie wycofają kolumny i nie zepsują wskaźnika, o którego istnieniu nikt już nie pamiętał.
Automatyczne śledzenie pochodzenia danych (lineage) rozwiąże ten problem. Ręczne śledzenie nie wytrzymuje próby wzrostu złożoności, szczególnie gdy w grę wchodzi wiele narzędzi do orkiestracji, hurtowni danych i warstw udostępniania. Kiedy pipeline się opóźnia lub zmienia się schemat, lineage skraca czas analizy przyczyn źródłowych ze zgadywania do celowego poszukiwania.
Oto ścieżka operacyjna, którą polecam przed uznaniem pipeline'u za gotowy do produkcji:
Odizoluj komponenty, aby pojedyncza zmiana nie wymagała pełnego refaktoryzacji kodu.
Określ oczekiwania dotyczące interfejsów dla każdego punktu przekazania danych, w tym schematu i terminowości.
Testuj moduły i całe ścieżki, ponieważ czysty test jednostkowy nie wychwyci błędnych założeń między etapami.
Poniżej znajduje się przydatny przewodnik po odpornych praktykach tworzenia pipeline'ów.
I jeszcze jedna kwestia, o której często się zapomina: wykonanie równoległe nie jest optymalizacją, którą dodaje się później. W przypadku nowoczesnych obciążeń musi to być uwzględnione w samym projekcie. Gdy niezależne zadania mogą być wykonywane jednocześnie, redukujesz wąskie gardła i zabezpieczasz okna dostarczania danych przy rosnącym wolumenie. Jeśli nie zaplanujesz tego na początku, każdy wzrost aktywności źródła zmieni się w problem z harmonogramem.
Buduj pipeline tak, aby jeden zespół mógł zmienić dany komponent bez konieczności pytania o zgodę pięciu innych zespołów.
Zabezpieczanie pipeline'ów danych w Twoim środowisku
Architektura bezpieczeństwa zaczyna się od prostego pytania: gdzie znajdują się dane podczas działania pipeline'u? Wiele zespołów skupia się na szyfrowaniu i kontroli dostępu, ignorując fizyczny przepływ danych. To błąd, szczególnie w branżach takich jak finanse, ochrona zdrowia, telekomunikacja i sektor publiczny, gdzie kwestie rezydowania danych i ścieżki dostępu mają równie duże znaczenie jak sama logika transformacji.
Rezydencja danych zmienia projekt
Wdrożenia on-premise oraz w chmurze prywatnej wymuszają lepszą dyscyplinę architektoniczną, ponieważ uniemożliwiają ignorowanie tego, gdzie trafiają wrażliwe dane. Jeśli Twój pipeline kopiuje dane produkcyjne do niezarządzanych stref przejściowych, rozszerza uprawnienia dostępu podczas transformacji lub przesyła dane do zewnętrznych usług w celu weryfikacji jakości, to powiększasz obszar podatny na ataki zanim dane w ogóle trafią do analityki.
Utrzymanie wykonywania procesów wewnątrz środowiska kontrolowanego przez klienta zmienia tę sytuację. Ogranicza niepotrzebny transfer danych, zawęża grono osób mających dostęp do danych produkcyjnych i znacznie ułatwia audyty. Ma to kluczowe znaczenie, gdy regulowane prawnie dane muszą pozostać w konkretnym środowisku lub gdy wewnętrzna polityka zabrania dostawcy dostępu do zbiorów danych produkcyjnych.
Kontrole bezpieczeństwa, które powinny znaleźć się w schemacie
Bezpieczna architektura pipeline'ów danych zazwyczaj wyróżnia się kilkoma cechami:
Szyfrowaniem podczas przesyłania i w spoczynku, dzięki czemu ekstrakcja, transfer i przechowywanie nie tworzą punktów narażenia na odczyt w postaci jawnego tekstu.
Dostępem opartym na rolach (RBAC), który oddziela operatorów pipeline'u, deweloperów, analityków i użytkowników biznesowych.
Segmentacją środowisk, dzięki czemu środowiska deweloperskie, testowe i produkcyjne nie polączą się ze sobą.
Możliwymi do zweryfikowania ścieżkami walidacji w odniesieniu do reguł biznesowych niosących implikacje regulacyjne (Compliance).
Konstrukcją minimalizującą kopiowanie danych, dzięki czemu architektura unika tworzenia zduplikowanych, wrażliwych zbiorów danych tylko na potrzeby monitoringu.
Bezpieczeństwo łączy się również z oczekiwaniami odnośnie dostarczania danych. Jeśli Twoja architektura zawiera umowy SLA dotyczące terminowości i wykrywania opóźnień, operatorzy mogą badać nietypowe opóźnienia zarówno jako problem z niezawodnością, jak i potencjalny sygnał naruszenia bezpieczeństwa. Nieoczekiwane zatrzymanie przesyłu danych może być problemem u źródła, ale może być również kwestią poświadczeń, polityki bezpieczeństwa lub łączności, wymagającą natychmiastowej reakcji.
Najlepsze projekty traktują zgodność regulacyjną (Compliance) jako cechę architektury, a nie ćwiczenie z tworzenia dokumentacji. Jeśli potrzebujesz jakości danych, wykrywania anomalii i śledzenia schematów, zaprojektuj te zabezpieczenia tak, aby działały tam, gdzie dane już się znajdują. To zazwyczaj bezpieczniejsze, łatwiejsze w zarządzaniu i prostsze do obrony podczas audytu.
Integrating Data Quality and Observability by Design
Wiele organizacji uważa, że posiada Observability, podczas gdy w rzeczywistości ma jedynie monitoring punktu docelowego. Wiedzą, czy tabela w hurtowni istnieje. Wiedzą, czy proces BI się zakończył. Nie wiedzą natomiast, czy dane trafiły do pipeline'u w prawidłowym stanie, czy zmieniły swoją strukturę w niebezpieczny sposób, ani czy nie dotarły na tyle późno, by raport stał się mylący.

Observability zaczyna się przy pobieraniu danych
Ta luka jest kluczowym powodem, dla którego Observability musi być wpisane w samą architekturę. Publikacja Alation omawiająca wzorce architektury pipeline'ów danych i observability dokonuje ważnego rozróżnienia: walidacja jakości powinna odbywać się na etapie wejściowym, a nie dopiero po przetworzeniu. Jeśli czekasz z tym na kontrole końcowe, cichy dryf danych, zmiany schematów i brakujące wartości zdążą już rozprzestrzenić się w całym przepływie.
Presja rynku spotyka się tu z rzeczywistością operacyjną. Rynek narzędzi do zarządzania pipeline'ami danych wycenia się na 14,76 mld USD przy skumulowanym rocznym wskaźniku wzrostu (CAGR) na poziomie 26,8%, a to samo źródło zauważa, że nowoczesne procesy mogą przetwarzać ponad 800 milionów rekordów dziennie. Przy takiej skali warstwa Observability dostarczająca metryki, takie jak liczba przetworzonych rekordów na sekundę czy wskaźniki błędów na poszczególnych etapach, nie jest luksusem. To elementarna kontrola operacyjna.
Dlaczego wyuczona detekcja wygrywa ze sztywnymi regułami
Weryfikacja oparta na regułach wciąż ma znaczenie, szczególnie w przypadku rygorystycznych ograniczeń biznesowych. Zawodzi jednak, gdy problem ma charakter behawioralny, a nie zerojedynkowy.
Wykrywanie anomalii lepiej nadaje się do tego zadania, ponieważ pozwala uczyć się oczekiwanych wzorców i flagować nietypowe odchylenia bez konieczności ciągłego ręcznego ustawiania progów. FirstEigen wyjaśnia oparte na sztucznej inteligencji wykrywanie anomalii w strumieniach danych jako proces ustalania punktów odniesienia dla danych wysokiej jakości, a następnie wskazywanie podejrzanych odchyleń do analizy. Przegląd Oracle dotyczący statystycznych i neuronowych metod wykrywania anomalii wnosi tutaj przydatną głębię tematu. Algorytmy klasteryzacji, metody gęstościowe, takie jak LOF, oraz autoenkodery pomagają wykrywać lokalne i subtelne anomalie, które umykają prostszym testom.
Dla zespołów pracujących z pipeline'ami przetwarzającymi duże liczby dokumentów ta sama zasada dotyczy poziomu poszczególnych pól. Ten przewodnik po walidacji danych dla faktur i zamówień (PO) stanowi dobre przypomnienie, że walidacja nie dotyczy wyłącznie ogólnych struktur. Chodzi w niej również o egzekwowanie reguł na poziomie pojedynczego rekordu, zanim błędne wartości wpłyną na dalszą logikę.
Błędne dane wykryte podczas pobierania to uniknięcie incydentu. Błędne dane wykryte na pulpicie nawigacyjnym to utrata zaufania.
Co należy monitorować od pierwszego dnia
Natywny projekt Observability powinien śledzić co najmniej cztery wymiary:
Terminowość pozwala monitorować, kiedy dane powinny dotrzeć i czy wzorce ich nadchodzenia ulegają zmianie.
Wolumen wykrywa nagłe spadki, piki lub nietypowe zmiany w dystrybucji danych.
Schemat sygnalizuje dodanie lub usunięcie kolumn oraz zmiany typów danych zanim transformacje ulegną uszkodzeniu bez ostrzeżenia.
Walidacja egzekwuje reguły biznesowe na poziomie rekordów tam, gdzie poprawność musi być precyzyjnie określona.
Jeśli Twój pipeline przetwarza dane sekwencyjne lub sterowane zdarzeniami, wzorce czasowe wymagają szczególnej dbałości. Wyjaśnienie Nile Secure na temat wstępnego przetwarzania danych i wykrywania anomalii czasowych podkreśla rolę preprocessingu, inżynierii cech oraz modeli dostosowanych do analizy sekwencyjnej, takich jak LSTM. Ma to znaczenie, ponieważ wiele „awarii pipeline'u danych” w rzeczywistości wynika z braku terminowości: dane dochodzą, ale nie wtedy, gdy firma ich potrzebuje.
Pomocny model myślowy wygląda tak: monitoring mówi o tym, czy zadanie się wykonało. Observability mówi o tym, czy dane pozostały wiarygodne w trakcie jego wykonywania. W celu rzetelnego porównania tych obowiązków warto zapoznać się z tym zestawieniem data observability kontra jakość danych (data quality) podczas projektowania warstwy kontrolnej.
Praktyczna lista kontrolna dla Twojego następnego pipeline'u
Najszybszym sposobem na usprawnienie przeglądu pipeline'u danych jest zaprzestanie pytań o to, czy system działa, a zaczęcie pytań o to, w jakich warunkach przestaje być wiarygodny.

Skorzystaj z tej listy kontrolnej przed zatwierdzeniem nowego projektu lub audytem już istniejącego:
Zdefiniuj kontrakty źródłowe na wczesnym etapie. Czy znasz strukturę, własność, model aktualizacji oraz możliwe tryby awarii każdego ze źródeł?
Dobierz wzorzec do okna decyzyjnego. Czy dany przypadek użycia wymaga przetwarzania wsadowego (batch), strumieniowego (streaming) czy hybrydowego, biorąc pod uwagę to, jak szybko ktoś musi podjąć działanie na podstawie tych danych?
Oddziel warstwę surową, przetworzoną i udostępnianą. Czy możesz powtórzyć proces pobierania danych bez konieczności ponownego budowania logiki biznesowej od zera?
Projektuj moduły, a nie potwory. Czy jeden zespół może wprowadzić zmianę w komponencie bez narażania niepowiązanych odbiorców danych?
Automatycznie mapuj pochodzenie danych (lineage). Jeśli dzisiaj zmieni się schemat danych, czy potrafisz szybko zidentyfikować tabele, pulpity i modele, których to dotyczy?
Zaplanuj wykonanie równoległe. Czy przepustowość zostanie utrzymana, gdy wzrośnie liczba źródeł lub nałożą się okna odświeżania?
Określ oczekiwania dotyczące terminowości. Czy istnieje jasna umowa SLA lub założenie operacyjne określające, kiedy dane powinny dotrzeć, a kiedy opóźnienie staje się incydentem?
Wdróż walidację i Observability od pierwszego wdrożenia. Czy świeżość, wolumen, schemat i kontrole na poziomie pojedynczych rekordów są integralną częścią architektury, a nie tylko dodatkiem?
Utrzymuj wrażliwe dane na miejscu, gdy to możliwe. Czy Twój projekt minimalizuje kopiowanie i ogranicza dostęp do danych podczas monitorowania oraz transformacji?
Udokumentuj punkty przekazania. Czy nowy lider zespołu będzie w stanie zrozumieć, jakie dane wchodzą do systemu, co się z nimi dzieje, gdzie są zapisywane i kto z nich korzysta?
Dobry pipeline wcale nie musi być skomplikowany. To taki, który Twój zespół może bezpiecznie modyfikować, przejrzyście monitorować i któremu ufa nawet w stresujących sytuacjach.
Jeśli Twój zespół poszukuje ochrony i kontroli bez konieczności przesyłania danych produkcyjnych poza własne środowisko, warto bliżej przyjrzeć się rozwiązaniu digna. Łączy ono jakość danych oraz Observability w jedną platformę, działając wewnątrz kontrolowanej przez klienta chmury prywatnej lub środowisk on-premise, pomagając zespołom wykrywać anomalie, zmiany schematów, opóźnienia i błędy walidacji na poziomie rekordów, zanim przełożą się one na nieaktualne raporty lub błędy w systemach końcowych.




Poznaj zespół tworzący platformę
Zespół z Wiednia, składający się z ekspertów od AI, danych i oprogramowania, wspierany rygorem akademickim i doświadczeniem korporacyjnym.