digna demokratisiert Zeitreihenanalyse und Anomalieerkennung für Geschäftsanwender
|
6
min. Lesezeit

Das Problem mit der Zeitreihenanalyse heute
Zeitreihen-Analyse war traditionell die Domäne von Data Scientists.
Zu verstehen, wie sich Daten im Laufe der Zeit entwickeln, Trends, Saisonalität, Volatilität und Anomalien zu identifizieren, erfordert in der Regel:
Python oder R
Fachwissen in statistischer Modellierung
externe Tools oder Notebooks
komplexe Daten-Pipelines
Für die meisten Business-Anwender stellt das eine Hürde dar.
Sie können Dashboards und Berichte aufrufen, aber sie können tiefere Fragen nicht beantworten, wie zum Beispiel:
Ist diese Veränderung erwartet oder ungewöhnlich?
Gibt es wiederkehrende Muster in unseren Daten?
Ist dieser Trend nachhaltig oder vorübergehend?
Daher verlassen sich Organisationen oft auf spezialisierte Teams für Erkenntnisse, die im gesamten Unternehmen zugänglich sein sollten.
Warum Zeitreihenanalyse für jedes Team wichtig ist
Moderne Datenumgebungen sind dynamisch.
Daten versagen nicht plötzlich, sie entwickeln sich weiter.
Kosten steigen allmählich
Das Nutzerverhalten verändert sich im Laufe der Zeit
Operative Metriken driften
Die Performance wird instabil
Ohne Zeitreihenanalyse bleiben diese Änderungen unsichtbar, bis sie zu Problemen werden.
Deshalb ist das Verständnis des Datenverhaltens im Zeitverlauf nicht mehr optional. Es ist unerlässlich.
digna bringt Zeitreihenanalyse zu Business-Anwendern
Mit der neuesten Version führt digna integrierte Zeitreihenanalyse und Anomalieerkennung direkt in die Plattform ein, ohne Fachwissen in Data Science zu erfordern.
Anstatt Daten in externe Tools zu exportieren, können Nutzer nun Trends, Muster und Anomalien dort analysieren, wo die Daten bereits liegen.
Dies markiert einen Wandel von:
❌ Daten überwachen
→ hin zu
✅ Das Datenverhalten verstehen
Interaktive Zeitreihenanalyse — Keine Programmierung erforderlich
Das neue Analytics Chart ermöglicht es Nutzern, das Datenverhalten interaktiv zu erkunden.
Es bietet integrierte statistische Methoden, die automatisch auf Ihre Datensätze angewendet werden.
📊 Trends mit Regressionsmodellen identifizieren
Nutzer können lineare, quadratische und kubische Regression anwenden, um zu verstehen, wie sich Daten im Laufe der Zeit entwickeln.
Das hilft, wichtige Fragen zu beantworten wie:
Steigt die Nutzung stetig?
Beschleunigt sich das Wachstum oder verlangsamt es sich?
Beobachten wir strukturelle Veränderungen?
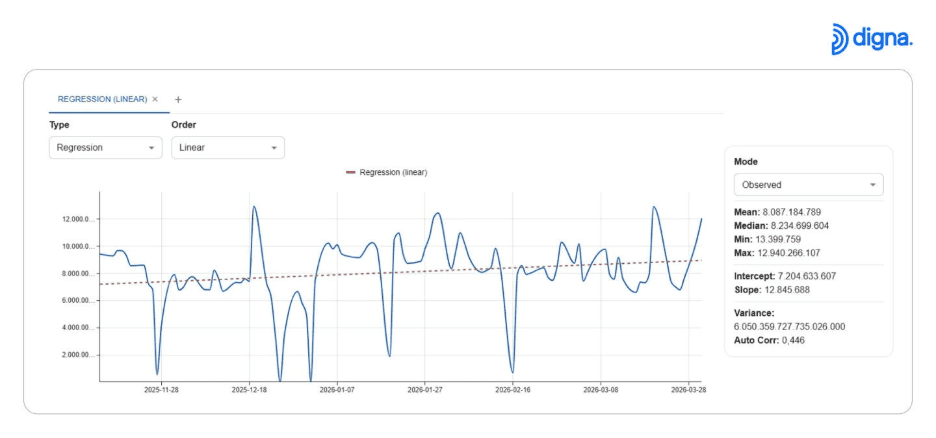
Trends mithilfe von Regressionsmodellen visualisieren, um das langfristige Datenverhalten zu verstehen.
🔍 Bruchpunkte und strukturelle Veränderungen erkennen
Stückweise Regression ermöglicht es Nutzern, Punkte zu identifizieren, an denen sich das Datenverhalten ändert.
Dies ist entscheidend, um zu erkennen:
plötzliche Veränderungen in der Performance
Änderungen im Nutzerverhalten
neue Muster, die durch Systemaktualisierungen eingeführt werden
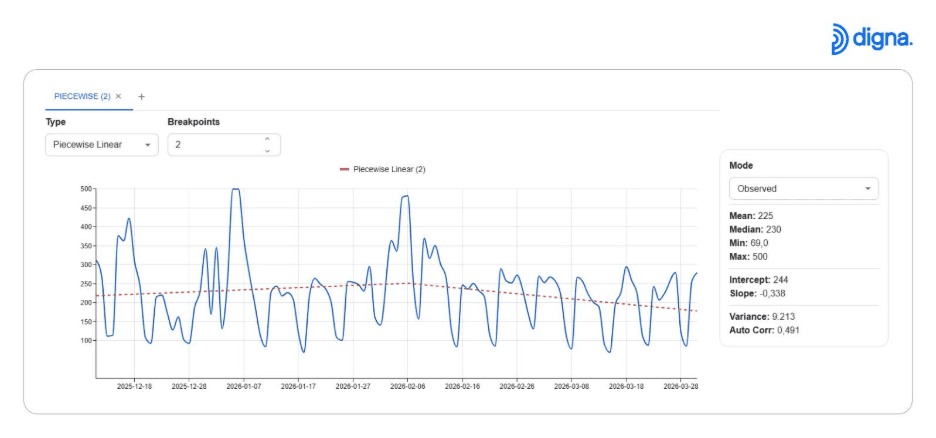
Strukturelle Brüche in Zeitreihendaten identifizieren, um Verhaltensänderungen zu erkennen.
🔄 Saisonalität und wiederkehrende Muster entdecken
digna erkennt automatisch saisonale Muster und zyklisches Verhalten.
Dies hilft Teams, zu unterscheiden zwischen:
erwarteten wiederkehrenden Mustern
echten Anomalien
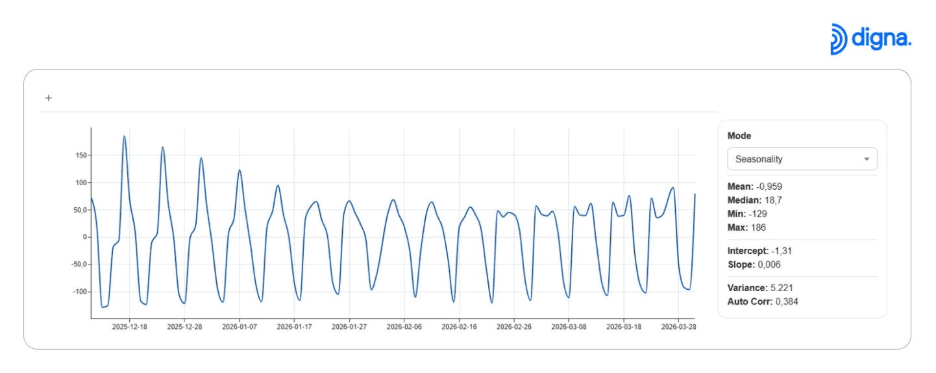
Wiederkehrende Muster und saisonale Trends in Daten erkennen.
📉 Variabilität und Verteilung analysieren
Quantilanalyse und Glättungstechniken ermöglichen es Nutzern, Variabilität und Datenverteilung im Zeitverlauf zu verstehen.
Dies ermöglicht:
bessere Prognosen
verbesserte Anomalieerkennung
ein klareres Verständnis der Volatilität
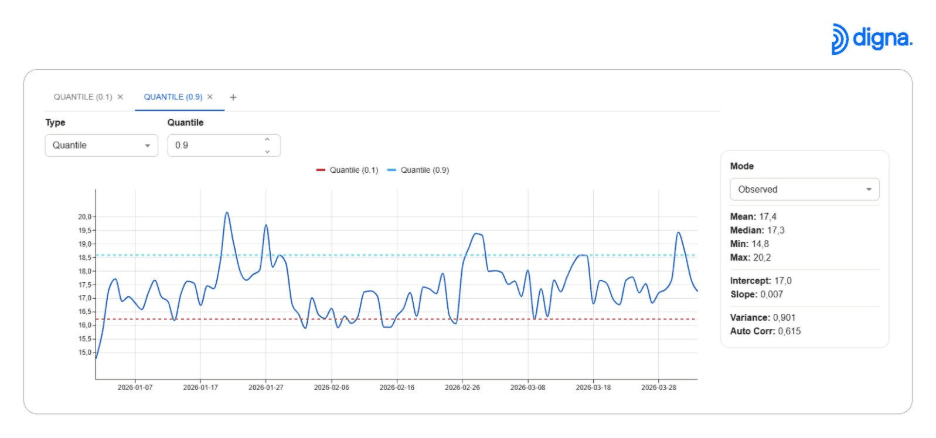
Variabilität und Verteilung mithilfe der Quantilanalyse verstehen.
Integrierte Anomalieerkennung — Ohne Regeln
Traditionelle Anomalieerkennung beruht auf vordefinierten Regeln:
Schwellenwerte
statische Bedingungen
manuell definierte Prüfungen
Diese Ansätze skalieren in modernen Umgebungen nicht gut.
digna geht anders vor.
Mithilfe statistischer Lernverfahren:
lernt, wie sich Daten im Laufe der Zeit verhalten
identifiziert Abweichungen von erwarteten Mustern
erkennt sowohl plötzliche Ausschläge als auch schleichende Drifts
Dies ermöglicht es Teams, Probleme früher zu identifizieren, ohne Tausende von Regeln zu pflegen.
Von der Abhängigkeit von Data Science zu Self-Service Analytics
Einer der größten Effekte dieses Releases ist die Demokratisierung.
Business-Anwender müssen sich nicht mehr auf Data Scientists verlassen, um:
Trends zu analysieren
Anomalien zu erkennen
Verhalten zu verstehen
Stattdessen können sie:
Daten direkt erkunden
Muster selbst interpretieren
schnellere Entscheidungen treffen
Dies reduziert Engpässe und beschleunigt die Generierung von Erkenntnissen im gesamten Unternehmen.
Warum dies für moderne Unternehmen wichtig ist
Mit wachsender Skalierung von Datensystemen steigt die Komplexität.
Unternehmen benötigen:
schnellere Generierung von Erkenntnissen
bessere Transparenz über das Datenverhalten
skalierbares Monitoring ohne manuellen Aufwand
Durch die Kombination von Zeitreihenanalyse und Anomalieerkennung innerhalb der Plattform ermöglicht digna Teams zu:
Probleme früher zu erkennen
Ursachen schneller zu verstehen
die Abhängigkeit von externen Tools zu reduzieren
Datenqualität in großem Maßstab aufrechtzuerhalten
Analyse in der Datenbank — Keine Datenbewegung
Alle Analysen und Validierungen in digna werden direkt in der Quell-Datenbank ausgeführt.
Das gewährleistet:
hohe Performance
hohe Sicherheit
Einhaltung von Richtlinien für Data Governance
Im Gegensatz zu anderen Tools müssen Daten für die Analyse nicht exportiert werden.
Abschließende Gedanken
Zeitreihenanalyse und Anomalieerkennung sollten nicht auf Data Scientists beschränkt sein.
Da Daten für jede Geschäftsfunktion zentral werden, muss das Verständnis ihres Verhaltens im Zeitverlauf für alle zugänglich sein.
Mit diesem Release bringt digna fortschrittliche Analysen direkt zu Business-Anwendern und ermöglicht es ihnen, über das Monitoring hinaus zu echtem Datenverständnis zu gelangen.
Mehr erfahren
Erfahren Sie mehr über den Ansatz von digna in Bezug auf Datenqualität und observability:
Oder entdecken Sie die vollständigen Release-Details:



