Warum Teradata-Workloads instabil werden – und wie Teams dies früh erkennen
|
6
min. Lesezeit

Teradata-Systeme sind auf Stabilität ausgelegt. Seit Jahrzehnten verlassen sich Unternehmen auf Teradata, um vorhersagbare Analytics mit hoher Performance in großem Maßstab bereitzustellen. In regulierten Branchen wie Banking, Versicherungen, Telekommunikation und dem öffentlichen Sektor bleibt Teradata ein entscheidendes Rückgrat für die Entscheidungsfindung.
Doch selbst in diesen ausgereiften Umgebungen stoßen Datenteams auf ein bekanntes Problem: Workloads, die einst stabil waren, werden allmählich unvorhersehbar.
Die CPU-Auslastung schwankt. Die IO-Nutzung driftet nach oben. Lang laufende Jobs verbrauchen Monat für Monat mehr Ressourcen. Die Kosten steigen nicht, weil etwas kaputt ist, sondern weil sich unbemerkt etwas verändert hat.
Zu verstehen, warum Teradata-Workloads instabil werden und wie man diese Instabilität früh erkennt, ist entscheidend, um Performance, Kosteneffizienz und betriebliches Vertrauen zu erhalten.
Instabilität in Teradata tritt selten über Nacht auf
Im Gegensatz zu modernen Cloud-Plattformen entwickeln sich Teradata-Umgebungen in der Regel nur langsam. Änderungen erfolgen bewusst, kontrolliert und gut dokumentiert. Daher zeigt sich Instabilität selten als plötzlicher Ausfall.
Stattdessen zeigt sie sich als Verhaltensdrift:
Jobs werden weiterhin erfolgreich abgeschlossen
SLAs werden technisch eingehalten
Dashboards zeigen keine offensichtlichen Warnsignale
Unter der Oberfläche verändert sich jedoch das Workload-Verhalten. Die CPU-Nutzung steigt leicht an. IO-Muster werden unruhiger. Verarbeitungsfenster werden enger. Mit der Zeit summieren sich diese kleinen Abweichungen zu einem betrieblichen Risiko.
Wenn die Instabilität sichtbar wird, ist die Behebung oft teuer und störend.
Häufige Ursachen für Teradata-Workload-Instabilität
1. Datenwachstum, das Ausführungspläne verändert
Datenwachstum ist unvermeidlich, sein Einfluss ist jedoch selten linear.
Wenn Tabellen wachsen:
ändern sich die Join-Strategien
steigt die Spool-Nutzung
steigen die Kosten für die Umverteilung
verschiebt sich2 die Workload-Verteilung auf den AMPs
Abfragen, die einst effizient waren, beginnen mehr CPU und IO zu verbrauchen, obwohl sich das SQL selbst nicht geändert hat. Da das Wachstum allmählich erfolgt, lösen herkömmliche Schwellenwert-basierte Alarme selten frühzeitig Warnungen aus.
2. Langsam weiterentwickelte SQL-Logik
Teradata-Workloads sind nicht statisch.
Mit der Zeit:
werden zusätzliche Joins eingeführt
werden neue Attribute ausgewählt
werden Filter gelockert
werden die Anforderungen an Berichte erweitert
Jede Anpassung wirkt geringfügig, doch in der Summe verändern sie die Eigenschaften der Workloads. Jobs laufen länger, verbrauchen mehr Ressourcen und werden weniger vorhersehbar.
Ohne historische Analyse werden diese Änderungen oft erst entdeckt, nachdem sich Nutzer beschweren oder die Kosten steigen.
3. Schieflage und Verteilungsänderungen
Daten-Skew ist eine bekannte Herausforderung in vielen MPP-Systemen wie Teradata.
Skew kann entstehen durch:
Datenmigrationen
demografische Verschiebungen
auf bestimmte Segmente konzentriertes Wachstum des Geschäfts
Änderungen an den Annahmen des Datenmodells
Mit zunehmendem Skew wird die Workload-Verteilung über die AMPs ungleichmäßig. Bestimmte AMPs verbrauchen überproportional viel CPU und IO, was die Gesamtleistung des Systems beeinträchtigt.
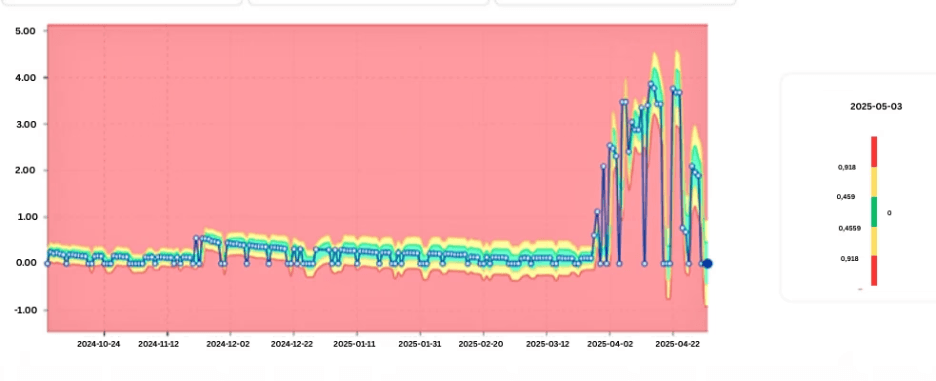
Eine Datenvisualisierung zeigt, wie der CPU-Skew auf AMP-Ebene im Laufe der Zeit zunimmt.
4. Infrastruktur- und Konfigurationsanpassungen
Auch gut verwaltete Teradata-Systeme entwickeln sich weiter.
Änderungen wie:
Hardware-Upgrades
Umkonfiguration der Plattform
System-Tuning
Priorisierung gemischter Workloads
können das Workload-Verhalten subtil beeinflussen. Ein Job, der jahrelang konsistent lief, kann plötzlich eine erhöhte Varianz zeigen — nicht wegen Datenproblemen, sondern weil sich die Ausführungsumgebung geändert hat.
5. Zyklische und saisonale Verarbeitung
Viele Teradata-Workloads folgen vorhersehbaren Zyklen:
Monatsabschluss
regulatorisches Reporting
periodische Abstimmungen
Ohne Saisonalität explizit zu modellieren, kann normales zyklisches Verhalten echte Anomalien verdecken oder unnötige Alarme erzeugen.
Die Unterscheidung zwischen erwarteter Variation und echter Instabilität erfordert historischen Kontext.
Warum herkömmliches Teradata-Monitoring frühe Signale verpasst
Teradata-Umgebungen werden typischerweise überwacht mit:
CPU- und IO-Alarmen auf Schwellenwertbasis
Grenzen für die Laufzeit von Abfragen
Dashboards zur Systemauslastung
Diese Tools sind effektiv bei der Identifizierung akuter Ausfälle, tun sich aber mit schrittweisen Veränderungen schwer.
Sie beantworten Fragen wie:
Wurde der CPU-Grenzwert überschritten?
Ist ein Job fehlgeschlagen?
Sie beantworten nicht:
Wird dieser Job im Laufe der Zeit teurer?
Wird sein Verhalten instabiler?
Ist die heutige Workload im Vergleich zu historischen Mustern plausibel?
Instabilität verbirgt sich in diesen unbeantworteten Fragen.
Die Rolle der Zeitreihenanalyse im Teradata-Betrieb
Früherkennung erfordert, Workload-Metriken als Zeitreihensignale und nicht als statische Werte zu behandeln.
Wichtige Teradata-Metriken sind:
CPU-Zeit
IO-Anzahl
Spool-Nutzung
Abfrage-Laufzeit
Tabellenwachstum
Über die Zeit analysiert, zeigen diese Metriken:
langfristige Trends
zunehmende Volatilität
strukturelle Veränderungen nach Deployments oder Migrationen
Abweichungen von saisonalen Normen
Diese Perspektive verschiebt das Workload-Monitoring von reaktiver Fehlerbehebung zu proaktiver Steuerung.
Instabilität erkennen, bevor sie zum Problem wird
Normales Workload-Verhalten lernen
Anstatt statische Schwellenwerte zu definieren, beobachten moderne Ansätze historisches Workload-Verhalten und lernen, wie „normal“ für jeden Job, jede Abfrageklasse oder Systemkomponente aussieht.
Wenn sich Muster stabilisieren, werden akzeptable Bereiche klarer. Abweichungen von diesen erlernten Mustern deuten auf potenzielle Probleme hin, selbst wenn die absoluten Werte innerhalb der nominalen Grenzen bleiben.
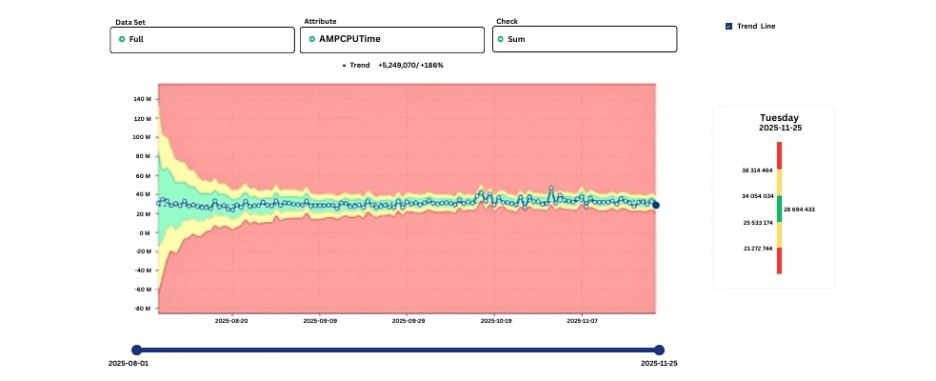
Grafik, die erlernte Bänder des Normalverhaltens mit einer entstehenden Abweichung zeigt.
Allmähliche Drift erkennen
Allmähliche Drift ist eine der teuersten Formen der Instabilität.
Durch die Einordnung von Jobs nach:
absoluter CPU-Zunahme
relativer Veränderung im Zeitverlauf
können Teams schnell erkennen, welche Workloads am stärksten zur steigenden Systemlast beitragen.
Das ermöglicht gezielte Optimierungen statt pauschaler Tuning-Maßnahmen.
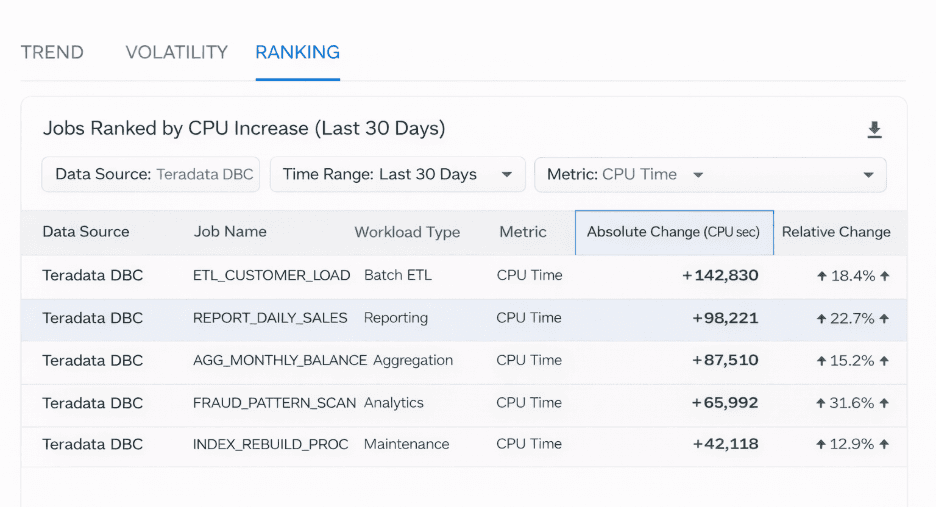
Liste von Jobs, sortiert nach monatlicher CPU-Zunahme.
Volatilität messen
Stabilität betrifft nicht nur Durchschnittswerte.
Jobs mit stark schwankendem CPU- oder IO-Verbrauch sind schwerer zu planen und verursachen eher Folgeprobleme. Die Messung der Volatilität hebt Workloads hervor, die sich unvorhersehbar verhalten, selbst wenn ihre durchschnittliche Nutzung akzeptabel erscheint.
Saisonalität berücksichtigen
Wirksame Erkennung berücksichtigt bekannte Zyklen.
Durch das Erlernen wöchentlicher und monatlicher Muster vermeiden Systeme Fehlalarme und bleiben dennoch empfindlich für Abweichungen, die das etablierte Verhalten durchbrechen.
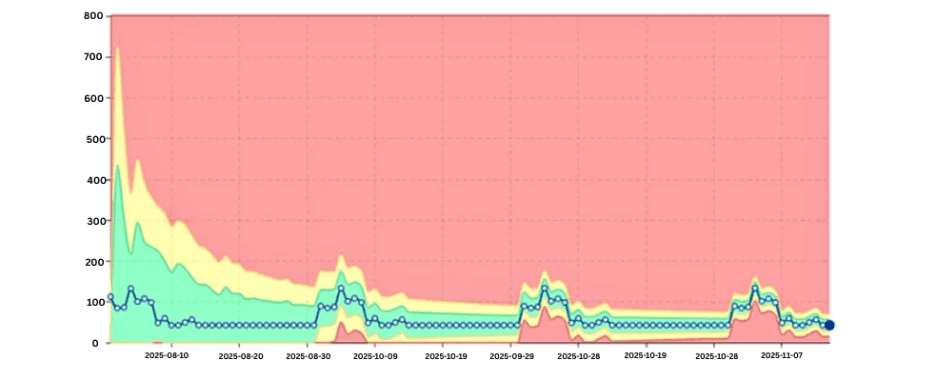
Saisonalitätsbewusster CPU-Trend, der erwartete Peaks zum Monatsende zeigt.
Wo digna in die Teradata-Workload-Analyse passt
Einige Monitoring-Ansätze setzen darauf, Metriken zur Analyse in externe Systeme zu exportieren. Andere arbeiten direkt innerhalb der Datenbankumgebung.
digna liest Teradata-Systemtabellen (DBC) aus und ermöglicht es Kunden gleichzeitig zu definieren, wie es auf diese Metadatenquellen zugreift, woraufhin Workload-Metriken in Zeitreihendaten umgewandelt werden. Mithilfe KI-basierter Modelle lernt es normales Verhalten und erkennt Abweichungen, die statistisch unwahrscheinlich sind — seien es plötzliche Spitzen oder langsame Drift.
Da digna sich auf Verhalten statt auf statische Schwellenwerte konzentriert, hilft es Teams, Instabilität früh zu erkennen, bevor sie sich zu Leistungs- oder Kostenproblemen ausweitet.
Ein Überblick über diesen anomaliegetriebenen Ansatz ist hier verfügbar, oder Sie können eine Demo buchen.
Betriebliche Vorteile der Früherkennung
Organisationen, die Teradata-Workload-Instabilität früh erkennen, erzielen messbare Vorteile:
geringerer CPU- und IO-Verbrauch durch rechtzeitige Optimierung
bessere Kostenvorhersagbarkeit
weniger Eskalationsmeetings
bessere Zusammenarbeit zwischen Plattform- und Fachbereichen
größeres Vertrauen in Analyseergebnisse
Vor allem wird Stabilität damit steuerbar statt reaktiv.
Blick nach vorn: Stabilität als operative Disziplin
Da Teradata weiterhin geschäftskritische Analytics- und KI-Workloads unterstützt, wird Stabilität zu einem strategischen Thema.
Stille Workload-Drifts untergraben Vertrauen, erhöhen Kosten und steigern das operative Risiko. Das frühe Erkennen von Instabilität erfordert:
Zeitreihenanalyse
Verhaltenslernen
kontextbezogenes Alerting
minimalen operativen Aufwand
In diesem Sinne ist Workload-Stabilität nicht mehr nur eine Leistungskennzahl, sondern ein zentrales Element der Zuverlässigkeit von Unternehmensdaten.
Abschließende Gedanken
Teradata-Workloads werden nicht über Nacht instabil. Instabilität entsteht schrittweise, getrieben durch Datenwachstum, Logikänderungen und sich wandelnde Systembedingungen.
Teams, die sich ausschließlich auf statisches Monitoring verlassen, erkennen Probleme zu spät. Wer das Workload-Verhalten über die Zeit analysiert, kann früh eingreifen und sowohl Performance als auch Vorhersagbarkeit bewahren.
Während sich Teradata-Umgebungen weiterentwickeln, wird die frühe Erkennung von Workload-Instabilität die operative Reife definieren.



