Moderne Workload-Analyse auf Teradata Vantage mit digna: KI-gesteuerte Optimierung für CPU-, IO- und Kosteneffizienz
|
7
min. Lesezeit

Teradata Vantage bleibt eine der wichtigsten Plattformen für großangelegte Unternehmensanalysen, da es leistungsstark, skalierbar und bewährt ist. Doch mit zunehmender Komplexität der Workloads stehen Teams vor einer ständigen Herausforderung:
Wie überwachen Sie kontinuierlich CPU, IO, Schiefe und Workload-Trends, ohne manuelle Überprüfungen, dutzende SQL-Abfragen oder nachträgliches Krisenmanagement?
Hier sorgt digna für eine deutliche Verbesserung.
Durch das Auslesen von Teradatas DBC-Systemtabellen, deren Umwandlung in intelligente Zeitreihenmetriken und die Anwendung von KI-basierter Anomalie-Erkennung bietet digna Ingenieurteams eine Echtzeit- und automatisierte Sicht auf das Workload-Verhalten, ohne Daten zu exportieren und ohne manuelle Regeln zu pflegen.
Dieser Artikel erklärt, wie digna das Teradata Workload-Management mit KI verbessert, wie es CPU/IO-Anomalien erkennt und wie Organisationen digna nutzen können, um Risiken zu reduzieren, Stabilität zu verbessern und Kosten zu senken.
Warum digna eine natürliche Ergänzung für die Teradata-Workload-Überwachung ist
Teradata bleibt eine der stabilsten und vertrauenswürdigsten Analyseplattformen. digna ergänzt die Zuverlässigkeit von Teradata, indem es Folgendes bietet:
KI-basiertes Trendlernen
Keine Schwellenwerte. Keine Regeln. digna lernt automatisch, wie „normale“ CPU-, IO-, Perm-Nutzung und Workload-Muster aussehen.
Echtzeit-Anomalieerkennung
Sobald ein Job von den erwarteten Werten abweicht, markiert digna dies—noch bevor es zu einem systemweiten Problem wird.
End-to-End-Workload-Sichtbarkeit
Alle Einblicke werden innerhalb von Teradata generiert, unter Verwendung von:
DBC-Tabellen
AMPCPUTime
IO-Histogrammen
Perm-Nutzung
Schiefe-Metriken
QryLog-Daten
DBQL-Tabellen
Benachrichtigungen dort, wo Teams arbeiten
E-Mails, Slack, Jira und modulbasierte Benachrichtigungen sorgen dafür, dass Probleme nie übersehen werden.
Keine Datenbewegung
Alle Berechnungen laufen innerhalb der Datenbank—nur Metriken verlassen das System.
Wie digna das Teradata-Workload-Verhalten lernt
digna beginnt mit der Erfassung von Betriebsmetriken direkt von Teradata durch SQL-Abfragen, die in Ihrer Umgebung ausgeführt werden. Aus Ihrem System verlassen nur die berechneten Metriken. Aber dies ist erst der Anfang — die wirkliche Intelligenz entsteht, wenn digna diese Rohsignale in sich entwickelnde Verhaltensprofile umwandelt.
Anstatt innerhalb der Datenbank zu lernen, leitet digna diese Metriken an die digna-KI-Engine weiter, wo Modelle kontinuierlich anpassen, wie sich Ihr Teradata-System im Laufe der Zeit verhält. Dies ermöglicht digna, nicht nur einzelne Datenpunkte zu verstehen, sondern Muster: wie die CPU während des Geschäftstages wächst, wie sich das IO während nächtlicher Chargen verhält und wie Workloads sich über Wochen oder Monate hinweg ändern.
Im Gegensatz zu traditionellen Workload-Tools, die eine Regelkonfiguration erfordern, lernt die Plattform automatisch tägliche, wöchentliche und monatliche Saisonalitäten. Z. B.:
Höherer CPU-Verbrauch jeden Montag
Zusätzliche IO-Belastung am 10. Tag jedes Monats
Monatsendspitzen, die für Ihre Organisation normal sind
Durch das Erkennen Ihrer natürlichen Betriebsrhythmen kann digna erwartete Zyklen von wahren Anomalien genau trennen. So vermeidet digna Fehlalarme, richtet den Fokus auf bedeutende Abweichungen und gibt Ihnen ein ständig anpassbares Verständnis der Workload-Gesundheit.
AMPCPUTime-Trendlernen
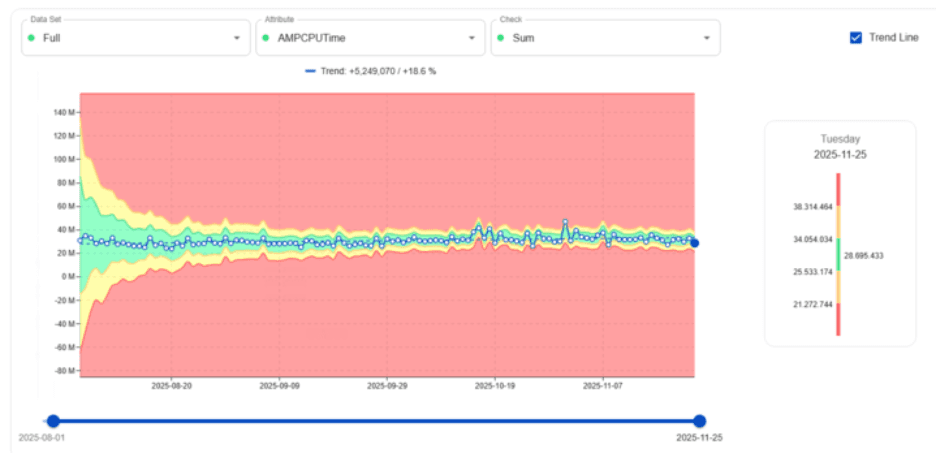
Eines der stärksten Beispiele ist, wie digna AMPCPUTime für das gesamte Teradata-System lernt.
Anfangs ist der akzeptierte (grüne) Bereich breit, da digna noch Variabilität beobachtet. Mit der Zeit wird die Nutzung stabiler, und der grüne Bereich wird enger. Dieses engere Band bedeutet, dass digna genau versteht, wie „gesunde“ CPU aussieht—so dass es echte Anomalien mit hoher Präzision markieren kann.
Wesentlicher Wert: digna reduziert CPU-bezogene Eskalationen und hilft Teams, wachsende Workloads vorherzusehen, bevor sie Vorfälle verursachen.
Früherkennung von IO-Ausreißern
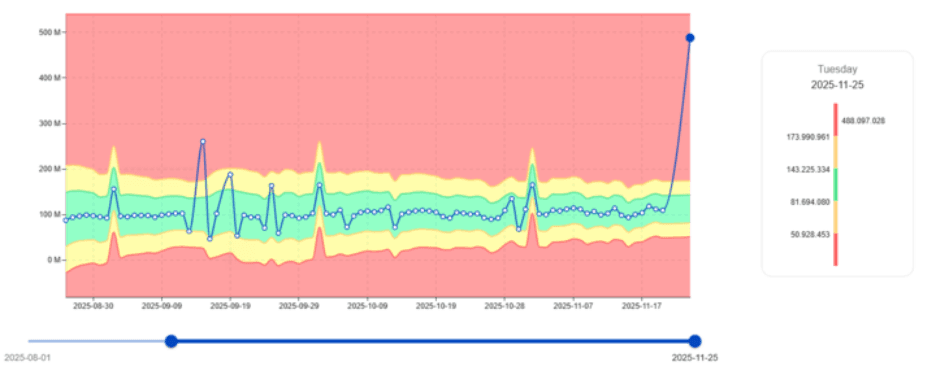
IO-Spitzen sind einige der frühesten Indikatoren für problematische Workloads.
Im hier eingefügten Beispiel identifiziert digna einen Job, der plötzlich IO weit außerhalb seines normalen Musters zeigt—obwohl die CPU möglicherweise normal erscheint.
Diese Frühwarnung ermöglicht es Teams, zu untersuchen:
Datenverteilungsänderungen
Tabellenscans
Ungleichmäßige Verbindungen
Unerwartetes Datenwachstum
Unoptimierte Workload-Logik
Wesentlicher Wert: digna hilft Teams, IO-Engpässe zu vermeiden, die das gesamte System verlangsamen.
Identifizierung instabiler CPU-Verbraucher
Nicht alle Jobs verhalten sich konsistent. Einige zeigen unerwartete Schwankungen im CPU-Verbrauch, die im Laufe der Zeit zur Instabilität des Clusters führen.
Das unten gezeigte Bild zeigt, wie digna diese Anomalien hervorhebt.
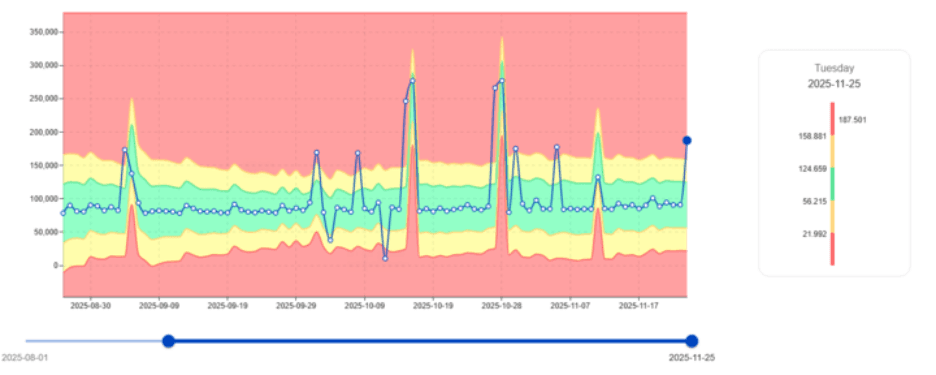
Schwankende CPU-Workloads weisen oft auf Folgendes hin:
Schlechte Abfragepläne
Datenmodelländerungen
Parameterempfindliche Optimierungen
Drift in Tabellengrößen
Schiefe in Verbindungen oder Aggregationen
Mit digna werden diese Muster lange erkannt, bevor sie zu einem großen Vorfall werden.
Wesentlicher Wert: digna macht störende Workloads frühzeitig sichtbar und ermöglicht eine CPU-Optimierung, die direkt Lizenz- und Infrastrukturkosten senkt.
Erkennung plötzlicher CPU-Instabilität in kritischen Jobs
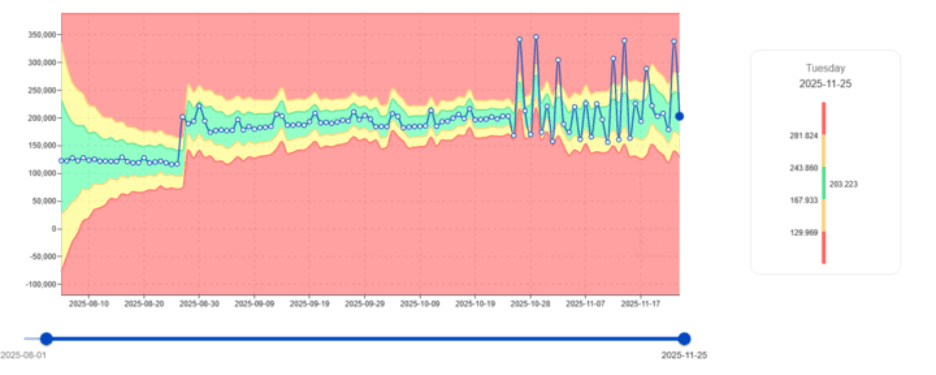
Manchmal ist der CPU-Verbrauch monatelang stabil—und wird plötzlich unregelmäßig.
Genau derartige Workloads ist digna gebaut, um sie zu erkennen.
Diese Änderungen resultieren oft aus:
Datenmigration
Neuen Demografien oder Verteilungen
Änderungen in der ETL-Logik
Schema-Drift
Schwacher Wartung von Indizes
digna markiert sofort solche Muster und kennzeichnet diese Workloads als hochprioritär für die Analyse.
Geschäftsauswirkungen: Frühzeitige Erkennung verhindert CPU-Spitzen, die die Leistung für Hunderte von Benutzern und Workloads beeinträchtigen könnten.
Erkennen und Respektieren saisonaler Muster
Nicht alle Spitzen sind Anomalien.
Einige Workloads ändern sich natürlich:
Monatsabschluss
Wöchentliche Abrechnungszyklen
Montagsberichte
Datenladungen zu Beginn des Quartals
Ende-of-Day Aggregationen
Das hier gezeigte Bild zeigt, wie digna saisonale Muster automatisch lernt.
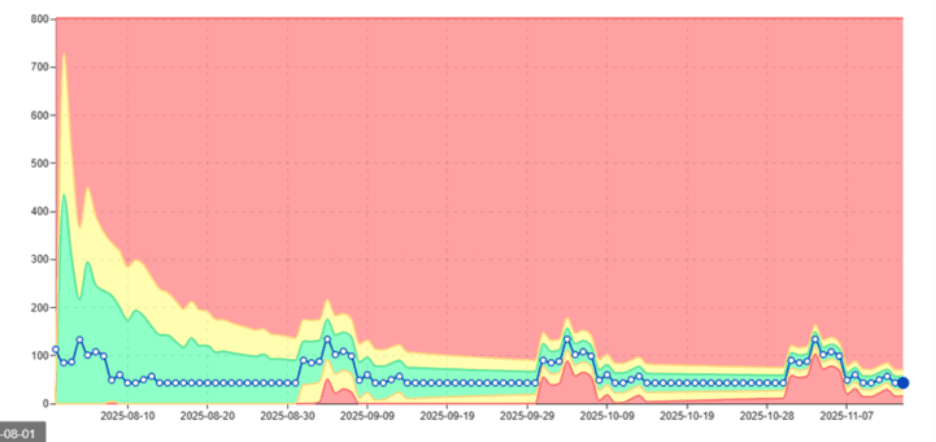
Statt falsch alarmiert zu werden, versteht digna:
Wann bestimmte Workloads ansteigen sollten
Wie steil der Anstieg sein sollte
Welche Muster sich über die Zeit wiederholen
Wesentlicher Wert: digna eliminiert Fehlalarme, indem es Anomalien von natürlicher Saisonalität unterscheidet.
Überwachung des Datenbankwachstums mit Perm-Nutzungstrends
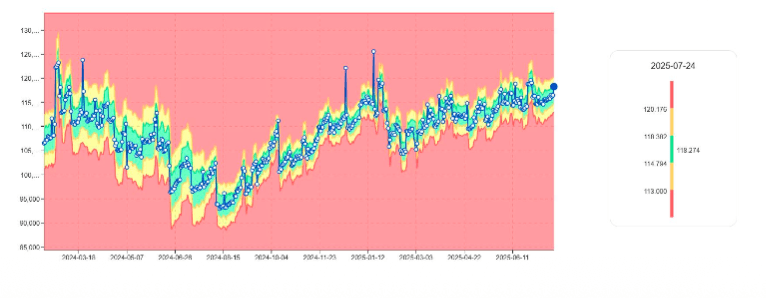
Perm-Nutzung ist eine grundlegende Metrik für das Kapazitätsmanagement von Teradata. digna:
Lernt die normale Größe
Markiert plötzliche Steigerungen
Identifiziert abnormales Tabellengrößenwachstum
Erkennt Spitzen beim Speicherverbrauch
Das hilft, Folgendes zu verhindern:
Speicherplatzfehler
Ungeplante Volltabellenscans
Durchlaufende ELT-Workloads
Wesentlicher Wert: digna gibt Teams Zeit, zu reagieren, bevor der Speicherverbrauch die Leistung beeinträchtigt.
Erkennung von Schiefe: Identifizierung ungleichmäßiger Datenverteilungen

Schiefe ist eines der häufigsten—und teuersten—Leistungsprobleme bei Teradata.
Schiefe tritt auf, wenn Daten nicht gleichmäßig über AMPs verteilt sind, was verursacht:
Engpässe
Lange CPU-Zyklen
Langsame Verbindungen
Leistungsschwankungen
digna analysiert automatisch Schiefetrends im Laufe der Zeit, um zu zeigen:
Wann eine Tabelle ungleichmäßig wird
Ob sich die Schiefe verschlechtert
Welche AMPs betroffen sind
Ob kürzliche Datenänderungen neue Schiefe verursacht haben
Wesentlicher Wert: digna identifiziert schiefebedingte Verschlechterungen, bevor sie die Leistung über die Plattform hinweg beeinträchtigen.
digna konvertiert alle DBC-Metriken in Zeitreihendaten
Dies ist der Kern des oben beschriebenen Funktionsumfangs. Durch die Konvertierung von DBC-Tabellenmetriken in Zeitreihen kann digna:
KI-Fähigkeiten
CPU-Muster lernen
IO-Anomalien erkennen
Saisonale Schwankungen modellieren
Job-Level-Volatilität verfolgen
Langsame Datenverschiebung erkennen
Langfristige Systemkapazität überwachen
Observability-Fähigkeiten
Vergleichen von Workloads über Tage hinweg
Verfolgen von Abfrageleistungsänderungen
Bieten von historischen Trends
Erkennen von Regressionen
Wachstumsmuster überwachen
Alarmierung & Integrationen
Email
Slack
Jira
Webhooks
Modul-basierte Benachrichtigungen
Wesentlicher Wert: dignas Zeitreihen-Engine verwandelt rohe Teradata-Metadaten in umsetzbare Erkenntnisse.
Echte Auswirkungen: Mehr Stabilität, niedrigere Kosten, weniger Eskalationen
Basierend darauf, wie Teams digna heute nutzen, liefert die Plattform:
Weniger Eskalationsmeetings: Da Anomalien erkannt werden, bevor Probleme eskalieren.
Größere Vorhersehbarkeit: Stabile Workloads = vorhersehbarer Ressourcenverbrauch = einfachere Kostenkontrolle.
Reduzierter CPU- und IO-Verbrauch: Durch frühzeitige Identifikation ineffizienter Workloads.
Stärkere Zusammenarbeit mit Geschäftsteams: Probleme werden behoben, bevor die Geschäftsnutzer etwas bemerken.
Weniger Brandbekämpfung für Ingenieurteams: KI übernimmt die Überwachung, sodass sich das Team auf wertschöpfende Aufgaben konzentrieren kann.
Zusammenfassung
Teradata Vantage bietet die Grundlage für Unternehmensdaten und -analysen. digna erweitert diese Grundlage durch eine automatisierte KI-Überwachungsschicht, die rohe Systemmetriken in Echtzeit-Betriebsintelligenz verwandelt.
Durch die kontinuierliche Analyse von CPU, IO, Schiefe, Perm-Nutzung und Job-Verhalten ermöglicht digna Ingenieurteams, die Leistung zu verbessern, Ausfallzeiten zu verhindern, Cloud-/On-Prem-Kosten zu senken und proaktiv statt reaktiv zu arbeiten.
Verbesserte Leistung
Vermeidung von Ausfällen
Reduzierung der Cloud-/On-Prem-Kosten
Proaktives Arbeiten statt reaktivem
Dies ist die nächste Generation der Teradata Workload-Analyse—KI-gesteuert, automatisiert und für den Unternehmensmaßstab entwickelt.
Sehen Sie sich unsere Demo an und entdecken Sie AI-Driven Optimization für CPU, IO und Kosteneffizienz in Ihrer Teradata-Umgebung oder kontaktieren Sie uns.



