Warum Databricks-Jobs unvorhersehbar werden - und wie Teams Instabilität frühzeitig erkennen
|
5
min. Lesezeit

Databricks-Umgebungen sind für Elastizität ausgelegt. Cluster skalieren, Workloads entwickeln sich weiter, und Datenmengen wachsen kontinuierlich. Diese Flexibilität ist kraftvoll; sie stellt jedoch auch eine Herausforderung dar, der sich viele Unternehmen letztendlich stellen müssen:
Jobs, die einst vorhersagbar waren, beginnen in Laufzeit, DBU-Verbrauch und Kosten zu schwanken.
Pipelines sind weiterhin erfolgreich. Dashboards werden weiterhin aktualisiert. Nichts scheint „kaputt“ zu sein. Dennoch erodiert die betriebliche Vorhersagbarkeit.
Zu verstehen, warum dies passiert und wie man es frühzeitig erkennt, ist entscheidend für Teams, die Databricks als Plattform für produktionsreife Daten und KI betreiben.
Instabilität bei Databricks bezieht sich auf Verhalten, nicht auf Fehler
In traditionellen Systemen bedeutete Instabilität oft Systemüberlastung oder Hardwaregrenzen. Instabilität bei Databricks ist anders.
Da Cluster automatisch skalieren und Workloads dynamisch verteilt werden, zeigt sich Instabilität als:
Steigender DBU-Verbrauch für die gleichen Jobs
Zunehmende Varianz in der Laufzeitdauer
Unvorhersehbare Aufgabeleistung
Häufigere Clusteranpassungsereignisse
Jobs können erfolgreich abgeschlossen werden, dennoch ändert sich ihr Verhalten im Laufe der Zeit. Diese Änderungen sind oft unsichtbar in Dashboards, die nur auf Erfolg/Misserfolg fokussiert sind.
Was verursacht die Unvorhersehbarkeit von Databricks-Jobs?
1. Datenwachstum verändert Ausführungspläne
Mit dem Wachstum der Datenmengen:
Steigt die Shuffle-Aktivität
Werden Joins schwerer
Verschlechtern sich Partitionierungsstrategien
Ändert sich die Caching-Effektivität
Auch ohne Codeänderungen verlagern sich Spark-Ausführungspläne. Dies führt zu höherem DBU-Verbrauch und längeren Laufzeiten.
Der Job „funktioniert“ immer noch, aber er verbraucht mehr Rechenleistung als zuvor.
2. Logik-Drift in Notebooks und Pipelines
Databricks-Workloads entwickeln sich schnell weiter.
Teams fügen hinzu:
Zusätzliche Joins
Weitere Aggregationen
Neue ML-Feature-Berechnungen
Breitere Filter
Jede Änderung erhöht den Aufwand. Einzelne sehen die Änderungen gering aus. Über Monate hinweg verändern sie das Workload-Verhalten grundlegend.
3. Auto-Scaling verdeckt Ressourcenprobleme
Auto-Scaling ist sowohl eine Stärke als auch ein blinder Fleck.
Wenn Workloads mehr Rechenleistung erfordern:
Erweitern sich Cluster automatisch
Schließen Jobs erfolgreich ab
Steigen die Kosten stillschweigend
Anstatt zu versagen, absorbiert das System Ineffizienzen – und verbirgt Leistungsverschlechterungen hinter elastischer Infrastruktur.
Das erste Signal erscheint oft als steigender DBU-Verbrauch, nicht als Fehler.
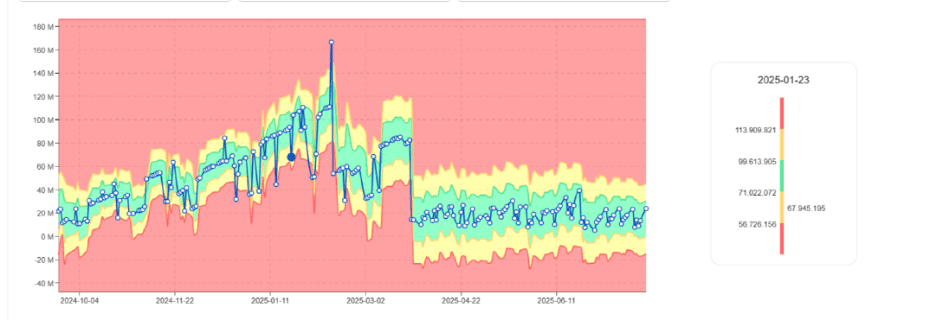
DBU-Verbrauchstrend steigt allmählich für den gleichen Job
4. Schieflage und Shuffle-Ungleichgewicht
Daten-Skew führt dazu, dass bestimmte Aufgaben unverhältnismäßig große Datenmengen verarbeiten müssen.
Bei Databricks zeigt sich dies als:
Langlaufende Aufgaben
Nachzügler
Erhöhte Variabilität der Stufendauer
Da Spark Aufgaben dynamisch verteilt, führt Skew zu instabilen Laufzeiten und unvorhersehbarem DBU-Verbrauch.
5. Wiederholungsverhalten und versteckte Fehler
Aufgabenwiederholungen sind in verteilten Systemen üblich.
Vorübergehende Probleme, Speicherengpässe oder der Verlust von Ausführern können Wiederholungen auslösen, die:
Laufzeit erhöhen
DBU-Verbrauch steigern
Volatilität hinzufügen
Jobs sind erfolgreich, aber die Instabilität nimmt zu.
6. Saisonalität in Workloads
Databricks-Jobs spiegeln oft Geschäftszyklen wider:
Monatsend-Verarbeitung
Wöchentliche Berichtsspitzen
Modellretrainingspläne
Ohne Modellierung dieser Muster ignorieren Teams entweder Anomalien oder werden von Fehlalarmen überwältigt.
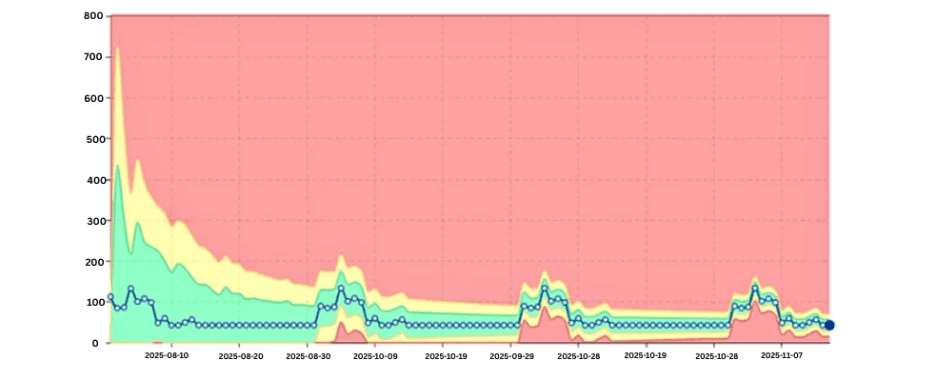
Saisonales DBU-Muster mit erwarteten Spitzen
Warum traditionelle Überwachung frühe Signale übersieht
Die meisten Teams verlassen sich auf:
Erfolgs-/Fehlermetriken für Jobs
Kostendashboards
Ansichten zur Clusternutzung
Diese Tools zeigen Ergebnisse, keine Verhaltensänderungen.
Sie offenbaren nicht:
Jobs, die im Laufe der Zeit teurer werden
Steigende Variabilität in der Laufzeit
Strukturelle Änderungen in der Workload-Ausführung
Instabilität beginnt lange bevor Schwellenwerte überschritten werden.
Der Wechsel zur Verhaltensüberwachung
Um Instabilität frühzeitig zu erkennen, muss man analysieren, wie sich Workloads über die Zeit verhalten, nicht nur, ob sie erfolgreich sind.
Wichtige Signale umfassen:
DBU-Verbrauchstrends
Entwicklung der Laufzeit
Varianz in der Aufgabendauer
Häufigkeit der Clusterskalierung
Indem sie diese Metriken in Zeitseriendaten umwandeln, können Teams Drift, Volatilität und strukturelle Änderungen identifizieren.
Frühzeitiges Erkennen von Instabilität
Erlernen des normalen Jobverhaltens
Anstatt fester DBU-Schwellenwerte zu verwenden, erlernen moderne Ansätze:
Typische DBU-Bereiche pro Job
Erwartete Laufzeitmuster
Normales Clusterverhalten
Wenn Workloads sich stabilisieren, verengen sich die akzeptablen Verhaltensbereiche.
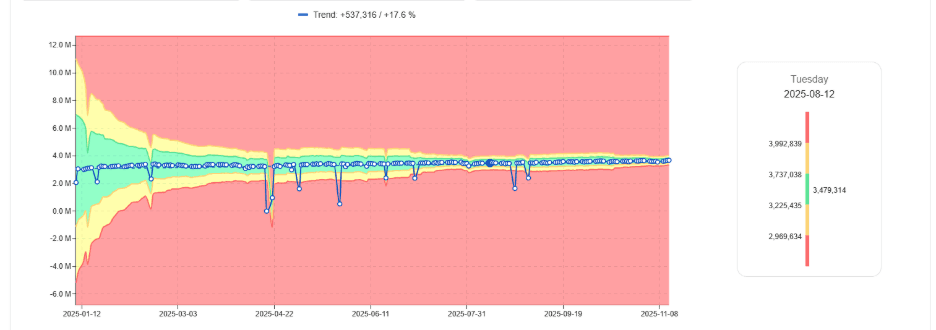
Gelerntes normales DBU-Band, das sich über die Zeit verengt
Erkennen des langsamen DBU-Drifts
Einer der größten Kostentreiber ist das langsame DBU-Wachstum.
Indem sie die aktuelle Nutzung mit historischen Basiswerten vergleichen, können Teams erkennen, welche Jobs zunehmend mehr Rechenleistung verbrauchen.
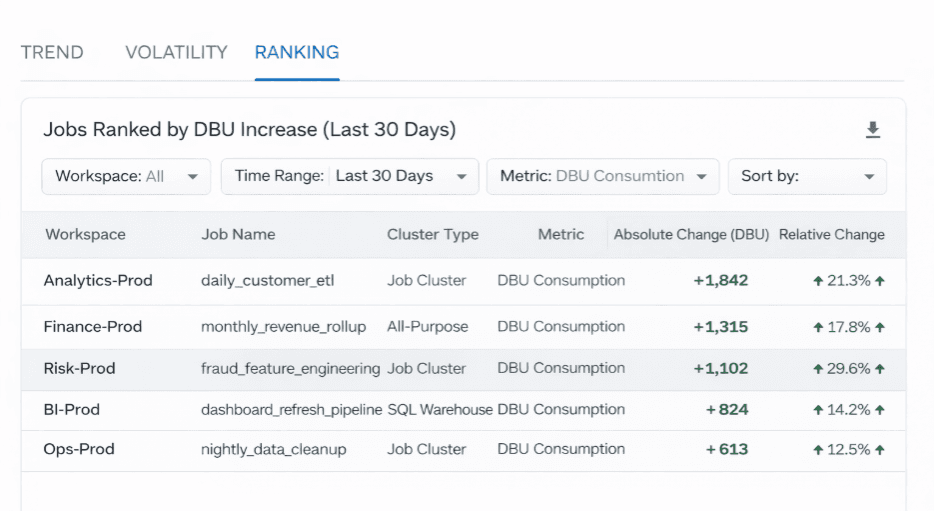
Jobs, die nach monatlichem DBU-Anstieg rangiert sind
Messen der Laufzeitvolatilität
Auch wenn die durchschnittliche Laufzeit konstant bleibt, signalisiert hohe Varianz Instabilität.
Volatile Jobs sind schwerer planbar und eher dazu geeignet, nachgelagerte Verzögerungen zu verursachen.
Berücksichtigung der Saisonalität
Verhaltenssysteme unterscheiden erwartete zyklische Spitzen von echten Anomalien, was die Anzahl der Fehlalarme reduziert.
Wo digna passt
digna analysiert Databricks-Workload-Metriken wie DBU-Verbrauch, Laufzeit und Volumenverhalten im Laufe der Zeit. Anstelle statischer Grenzen verwendet es KI, um normale Muster zu erlernen und frühzeitige unplausible Abweichungen zu erkennen – sei es durch plötzliche Ausschläge oder allmählichen Drift.
Dies ermöglicht es Teams, Probleme zu erkennen, bevor sie in Kostenberichten oder SLA-Verstößen auftreten.
Mehr über diesen auf Anomalien basierenden Ansatz finden Sie hier:
digna Data Anomalies | Demo ansehen
Warum frühe Erkennung wichtig ist
Wenn Instabilität frühzeitig erkannt wird, können Organisationen:
Abfragen optimieren, bevor die Kosten eskalieren
Pipelines stabilisieren, bevor SLAs betroffen sind
Feuerbekämpfung reduzieren
Die Vorhersehbarkeit für FinOps-Teams verbessern
Letzter Gedanke
Databricks-Jobs scheitern selten vollständig. Sie werden unvorhersehbar.
Diese Unvorhersehbarkeit wird sichtbar in sich änderndem DBU-Verhalten, Laufzeitvariabilität und sich entwickelnden Ausführungsmustern, Signalen, die statische Überwachung nicht erfassen kann.
Teams, die auf Verhaltensüberwachung umstellen, gewinnen frühzeitig Einblicke in Instabilität und behalten die Kontrolle, während ihre Databricks-Umgebungen skalieren.



