Dlaczego obciążenia Teradata stają się niestabilne — i jak zespoły wykrywają to wcześnie
|
6
min. czyt.

Systemy Teradata zostały zaprojektowane z myślą o stabilności. Od dziesięcioleci przedsiębiorstwa polegają na Teradata, aby dostarczać przewidywalną analitykę o wysokiej wydajności na dużą skalę. W branżach regulowanych, takich jak bankowość, ubezpieczenia, telekomunikacja i sektor publiczny, Teradata pozostaje kluczowym filarem podejmowania decyzji.
Jednak nawet w tych dojrzałych środowiskach zespoły danych napotykają znany problem: obciążenia, które kiedyś były stabilne, stopniowo stają się nieprzewidywalne.
Zużycie CPU się waha. Wykorzystanie IO stopniowo rośnie. Zadania długotrwałe z miesiąca na miesiąc zużywają więcej zasobów. Koszty rosną nie dlatego, że coś jest zepsute, lecz dlatego, że coś po cichu się zmieniło.
Zrozumienie, dlaczego obciążenia Teradata stają się niestabilne i jak wcześnie wykryć tę niestabilność, jest kluczowe dla utrzymania wydajności, efektywności kosztowej i pewności operacyjnej.
Niestabilność w Teradata Rzadko Pojawia się Z dnia na Dzień
W przeciwieństwie do nowoczesnych platform chmurowych, środowiska Teradata zwykle ewoluują powoli. Zmiany są celowe, kontrolowane i dobrze udokumentowane. W rezultacie niestabilność rzadko objawia się jako nagła awaria.
Zamiast tego pojawia się jako dryf behawioralny:
Zadania nadal kończą się pomyślnie
SLA są technicznie dotrzymywane
Panele nie pokazują oczywistych sygnałów ostrzegawczych
Jednak pod powierzchnią zachowanie obciążenia się zmienia. Wykorzystanie CPU nieznacznie rośnie. Wzorce IO stają się bardziej nieregularne. Okna przetwarzania się kurczą. Z czasem te niewielkie odchylenia kumulują się w ryzyko operacyjne.
Gdy niestabilność staje się widoczna, jej naprawa jest często kosztowna i zakłócająca pracę.
Najczęstsze Przyczyny Niestabilności Obciążeń Teradata
1. Wzrost Danych, Który Zmienia Plany Wykonania
Wzrost danych jest nieunikniony, ale jego wpływ rzadko jest liniowy.
W miarę wzrostu tabel:
Zmieniają się strategie łączenia
Rośnie wykorzystanie spool
Wzrastają koszty redystrybucji
Zmienia się równowaga obciążenia AMP2
Zapytania, które kiedyś były wydajne, zaczynają zużywać więcej CPU i IO, mimo że sam SQL się nie zmienił. Ponieważ wzrost jest stopniowy, tradycyjne alerty oparte na progach rzadko uruchamiają wczesne ostrzeżenia.
2. Powoli Ewoluująca Logika SQL
Obciążenia Teradata nie są statyczne.
Z biegiem czasu:
Wprowadzane są dodatkowe złączenia
Wybierane są nowe atrybuty
Filtry są łagodzone
Rosną wymagania raportowe
Każda korekta wydaje się niewielka, ale łącznie zmienia charakterystykę obciążenia. Zadania działają dłużej, zużywają więcej zasobów i stają się mniej przewidywalne.
Bez analizy historycznej zmiany te są często wykrywane dopiero wtedy, gdy użytkownicy zaczynają narzekać albo rosną koszty.
3. Skośność i Zmiany Dystrybucji
Skośność danych to dobrze znane wyzwanie w wielu systemach MPP takich jak Teradata.
Skośność może pojawić się z powodu:
Migracji danych
Zmian demograficznych
Wzrostu biznesu skoncentrowanego w określonych segmentach
Zmian w założeniach modelowania danych
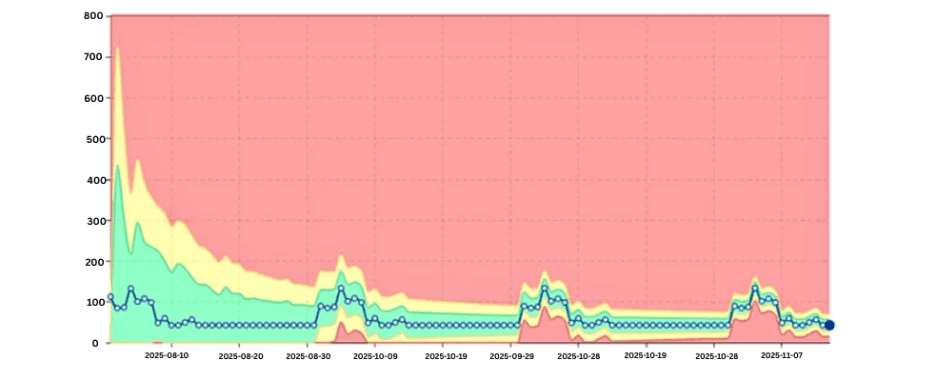
Wraz ze wzrostem skośności dystrybucja obciążenia między AMP staje się nierównomierna. Niektóre AMP zużywają nieproporcjonalnie dużo CPU i IO, pogarszając ogólną wydajność systemu.
Wizualizacja danych pokazująca wzrost skośności CPU na poziomie AMP w czasie.
4. Zmiany Infrastruktury i Konfiguracji
Nawet dobrze zarządzane systemy Teradata ewoluują.
Zmiany takie jak:
Modernizacje sprzętu
Przeconfigurowanie platformy
Dostrajanie systemu
Priorytetyzacja mieszanych obciążeń
mogą subtelnie wpływać na zachowanie obciążenia. Zadanie, które działało konsekwentnie przez lata, może nagle wykazywać większą zmienność — nie z powodu problemów z danymi, lecz dlatego, że zmieniło się środowisko wykonawcze.
5. Cykliczne i Sezonowe Przetwarzanie
Wiele obciążeń Teradata przebiega zgodnie z przewidywalnymi cyklami:
Zamknięcie miesiąca
Raportowanie regulacyjne
Okresowe uzgodnienia
Bez jawnego modelowania sezonowości zwykłe zachowanie cykliczne może zacierać prawdziwe anomalie lub generować niepotrzebne alerty.
Rozróżnienie oczekiwanych odchyleń od rzeczywistej niestabilności wymaga historycznego kontekstu.
Dlaczego Tradycyjne Monitorowanie Teradata Pomija Wczesne Sygnały
Środowiska Teradata są zazwyczaj monitorowane za pomocą:
Alertów CPU i IO opartych na progach
Limitów czasu działania zapytań
Paneli wykorzystania systemu
Narzędzia te są skuteczne w identyfikowaniu ostrych awarii, ale mają trudność z stopniowymi zmianami.
Odpowiadają na pytania takie jak:
Czy CPU przekroczył limit?
Czy zadanie zakończyło się niepowodzeniem?
Nie odpowiadają na pytania:
Czy to zadanie staje się z czasem coraz droższe?
Czy jego zachowanie staje się mniej stabilne?
Czy dzisiejsze obciążenie jest prawdopodobne w porównaniu z historycznymi wzorcami?
Niestabilność tkwi właśnie w tych bez odpowiedzi pytaniach.
Rola Analizy Szeregów Czasowych w Operacjach Teradata
Wczesne wykrywanie wymaga traktowania metryk obciążenia jako sygnałów szeregów czasowych, a nie wartości statycznych.
Kluczowe metryki Teradata obejmują:
Czas CPU
Liczbę IO
Wykorzystanie spool
Czas działania zapytania
Wzrost tabel
Analizowane w czasie metryki te ujawniają:
Długoterminowe trendy
Rosnącą zmienność
Zmiany strukturalne po wdrożeniach lub migracjach
Odchylenia od norm sezonowych
Ta perspektywa przesuwa monitorowanie obciążenia z reaktywnego rozwiązywania problemów do proaktywnej kontroli.
Wykrywanie Niestabilności, Zanim Stanie się Problemem
Nauka Normalnego Zachowania Obciążenia
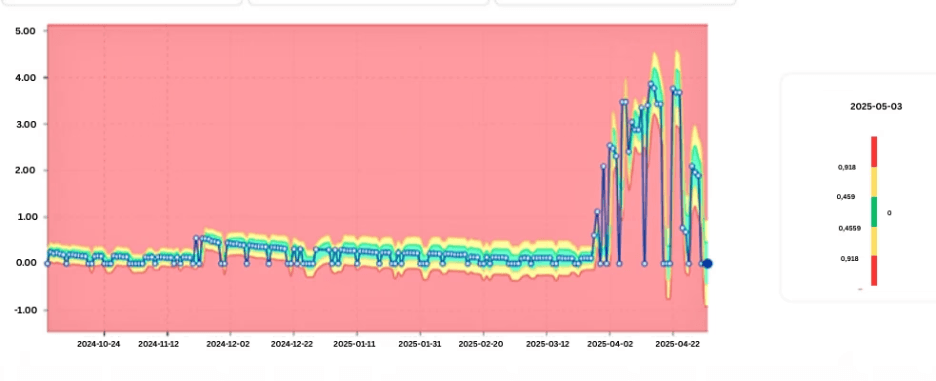
Zamiast definiować statyczne progi, nowoczesne podejścia obserwują historyczne zachowanie obciążenia i uczą się, jak wygląda „normalność” dla każdego zadania, klasy zapytań lub komponentu systemu.
W miarę stabilizacji wzorców stają się jaśniejsze dopuszczalne zakresy. Odchylenia od tych wyuczonych wzorców sygnalizują potencjalne problemy, nawet jeśli wartości bezwzględne pozostają w granicach nominalnych.
Wykres pokazujący wyuczone pasma normalnego zachowania z pojawiającym się odchyleniem.
Identyfikacja Stopniowego Dryfu
Stopniowy dryf to jedna z najbardziej kosztownych form niestabilności.
Dzięki rankingowi zadań według:
Bezwzględnego wzrostu CPU
Względnej zmiany w czasie
zespoły mogą szybko zidentyfikować, które obciążenia najbardziej przyczyniają się do wzrostu obciążenia systemu.
Umożliwia to ukierunkowaną optymalizację zamiast ogólnych działań strojenia.
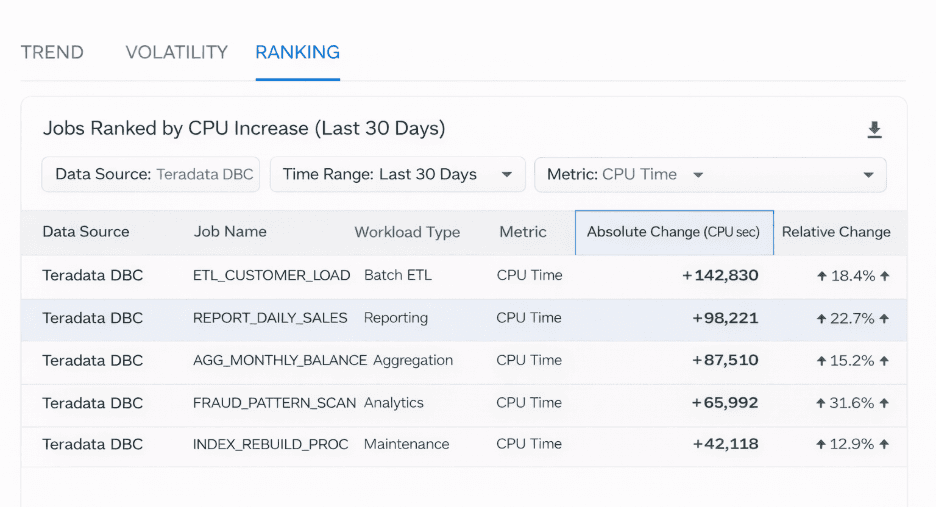
Lista zadań uszeregowanych według miesięcznego wzrostu CPU miesiąc do miesiąca.
Pomiar Zmienności
Stabilność to nie tylko średnie.
Zadania o bardzo zmiennym zużyciu CPU lub IO są trudniejsze do planowania i bardziej narażone na powodowanie problemów wtórnych. Pomiar zmienności uwidacznia obciążenia, które zachowują się nieprzewidywalnie, nawet jeśli ich średnie zużycie wydaje się akceptowalne.
Uwzględnianie Sezonowości
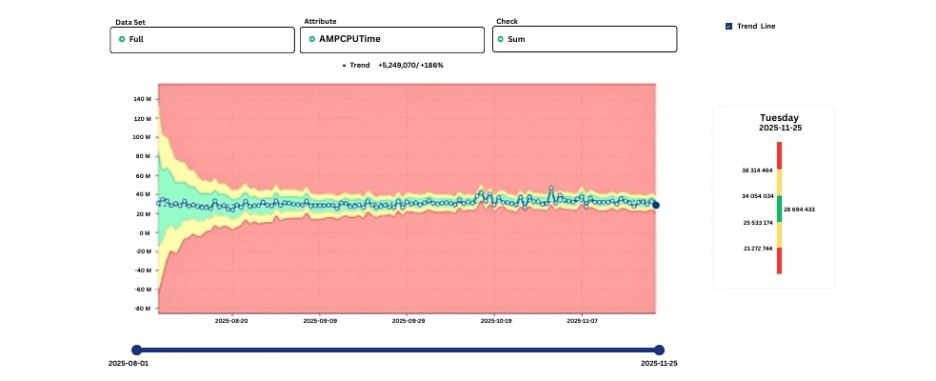
Skuteczne wykrywanie uwzględnia znane cykle.
Dzięki uczeniu się wzorców tygodniowych i miesięcznych systemy unikają fałszywych alarmów, a jednocześnie pozostają wrażliwe na odchylenia naruszające ustalone zachowanie.
Świadomy sezonowości trend CPU pokazujący oczekiwane szczyty na koniec miesiąca.
Gdzie digna Pasuje do Analizy Obciążeń Teradata
Niektóre podejścia monitorujące polegają na eksportowaniu metryk do zewnętrznych systemów w celu analizy. Inne działają bezpośrednio w środowisku bazy danych.
digna odczytuje tabele systemowe Teradata (DBC), jednocześnie pozwalając klientom określić, w jaki sposób uzyskuje dostęp do tych źródeł metadanych, po czym metryki obciążenia są przekształcane w dane szeregów czasowych. Korzystając z modeli opartych na AI, uczy się normalnego zachowania i wykrywa odchylenia statystycznie mało prawdopodobne, zarówno nagłe skoki, jak i powolny dryf.
Ponieważ digna koncentruje się na zachowaniu, a nie na statycznych progach, pomaga zespołom wcześnie wykrywać niestabilność, zanim przerodzi się ona w problemy z wydajnością lub kosztami.
Przegląd tego podejścia opartego na anomaliach jest dostępny tutaj lub możesz umówić demo z nimi.
Korzyści Operacyjne z Wczesnego Wykrywania
Organizacje, które wcześnie wykrywają niestabilność obciążeń Teradata, osiągają wymierne korzyści:
Niższe zużycie CPU i IO dzięki terminowej optymalizacji
Lepszą przewidywalność kosztów
Mniej spotkań eskalacyjnych
Lepiej współpracujące zespoły platformy i biznesu
Większą pewność co do wyników analitycznych
Co najważniejsze, stabilność staje się zarządzalna, a nie reaktywna.
Patrząc W Przyszłość: Stabilność jako Dyscyplina Operacyjna
W miarę jak Teradata nadal wspiera krytyczne dla działania firmy obciążenia analityczne i AI, stabilność staje się kwestią strategiczną.
Cichy dryf obciążeń podważa zaufanie, zwiększa koszty i podnosi ryzyko operacyjne. Wczesne wykrywanie niestabilności wymaga:
Analizy szeregów czasowych
Uczenia behawioralnego
Alertów uwzględniających kontekst
Minimalnego nakładu operacyjnego
W tym sensie stabilność obciążenia nie jest już tylko metryką wydajności, lecz podstawowym elementem niezawodności danych w przedsiębiorstwie.
Uwagi Końcowe
Obciążenia Teradata nie stają się niestabilne z dnia na dzień. Niestabilność pojawia się stopniowo, napędzana wzrostem danych, zmianami logiki i ewoluującymi warunkami systemowymi.
Zespoły, które polegają wyłącznie na statycznym monitoringu, wykrywają problemy zbyt późno. Te, które analizują zachowanie obciążenia w czasie, mogą interweniować wcześniej, zachowując zarówno wydajność, jak i przewidywalność.
W miarę jak środowiska Teradata nadal ewoluują, wczesne wykrywanie niestabilności obciążenia będzie definiować dojrzałość operacyjną.



