Nowoczesna analiza obciążenia w Teradata Vantage z digną: Optymalizacja oparta na AI dla wydajności CPU, IO i kosztów.
|
7
min. czyt.

Teradata Vantage pozostaje jedną z najważniejszych platform dla analityki przedsiębiorstw na dużą skalę, ponieważ jest potężna, skalowalna i sprawdzona. Ale wraz ze wzrostem złożoności obciążeń, zespoły stają przed ciągłym wyzwaniem:
Jak monitorować ciągle trendy CPU, IO, skośności i obciążeń bez ręcznych sprawdzeń, dziesiątek zapytań SQL czy walki z incydentami po fakcie?
Tu właśnie dostarcza się znacząca zmiana dzięki digna.
Poprzez odczytywanie Teradata’s tabel systemowych DBC, konwertowanie ich na inteligentne metryki szeregów czasowych oraz stosowanie wykrywania anomalii opartego na AI, digna daje zespołom inżynieryjnym automatyczny widok w czasie rzeczywistym na zachowanie obciążenia bez eksportu danych i bez ręcznego utrzymywania reguł.
Artykuł ten rozbija jak digna ulepsza zarządzanie obciążeniami Teradata wykorzystując AI, jak wykrywa anomalie CPU/IO, oraz jak organizacje mogą używać digna do zmniejszenia ryzyk, poprawienia stabilności i redukcji kosztów.
Dlaczego digna jest naturalnym dopasowaniem do monitorowania obciążeń Teradata
Teradata pozostaje jedną z najbardziej stabilnych i zaufanych platform analitycznych. digna uzupełnia niezawodność Teradata poprzez dostarczanie:
Uczenie trendów bazujące na AI
Bez progów. Bez reguł. digna automatycznie uczy się, jak wygląda „normalne” zużycie CPU, IO, perm i wzorce obciążeń.
Wykrywanie anomalii w czasie rzeczywistym
Gdy tylko zadanie odbiega od oczekiwanych wartości, digna to sygnalizuje—przed tym, jak stanie się to problemem w całym systemie.
Koniec widoczności obciążeń
Wszystkie informacje są generowane wewnątrz Teradata, używając:
Tabel DBC
AMPCPUTime
Histogramów IO
Perm usage
Metryk skośności
Danych QryLog
Tablic DBQL
Powiadomienia tam, gdzie pracują zespoły
Email, Slack, Jira i powiadomienia modułowe zapewniają, że problemy nigdy nie zostaną przeoczone.
Zero ruchu danych
Wszystkie obliczenia przeprowadzane są wewnątrz bazy danych—tylko metryki opuszczają system.
Jak digna się uczy zachowań obciążeń Teradata
digna zaczyna od zbierania metryk operacyjnych bezpośrednio z Teradata za pomocą zapytań SQL wykonywanych w twoim środowisku. Nic nie opuszcza twojego systemu poza samymi obliczonymi metrykami. Ale to dopiero początek — prawdziwa inteligencja następuje, gdy digna przekształca te surowe sygnały w ewoluujące profile behawioralne.
Zamiast uczyć się wewnątrz bazy danych, digna kieruje te metryki do silnika AI digna, gdzie modele ciągle adaptują się do tego, jak twój system Teradata zachowuje się w czasie. To pozwala digna zrozumieć nie tylko pojedyncze punkty danych, ale wzorce: jak CPU rośnie w ciągu dnia pracy, jak IO zachowuje się podczas nocnych przetwarzań partii, i jak obciążenia fluktuują w tygodniach lub miesiącach.
W przeciwieństwie do tradycyjnych narzędzi do obciążeń wymagających konfiguracji reguł, platforma automatycznie uczy się sezonowości dziennej, tygodniowej i miesięcznej. Na przykład:
Wyższe zużycie CPU w każdy poniedziałek
Dodatkowe obciążenie IO w 10-tym dniu każdego miesiąca
Skoki pod koniec miesiąca, które są normalne dla twojej organizacji
Rozpoznając twoje naturalne rytmy operacyjne, digna może precyzyjnie oddzielić oczekiwane cykle od prawdziwych anomalii. W ten sposób digna unika fałszywych alarmów, skupia uwagę na znaczących odchyleniach i daje ci ciągle dostosowujące się zrozumienie zdrowia obciążeń.
Uczenie trendów AMPCPUTime
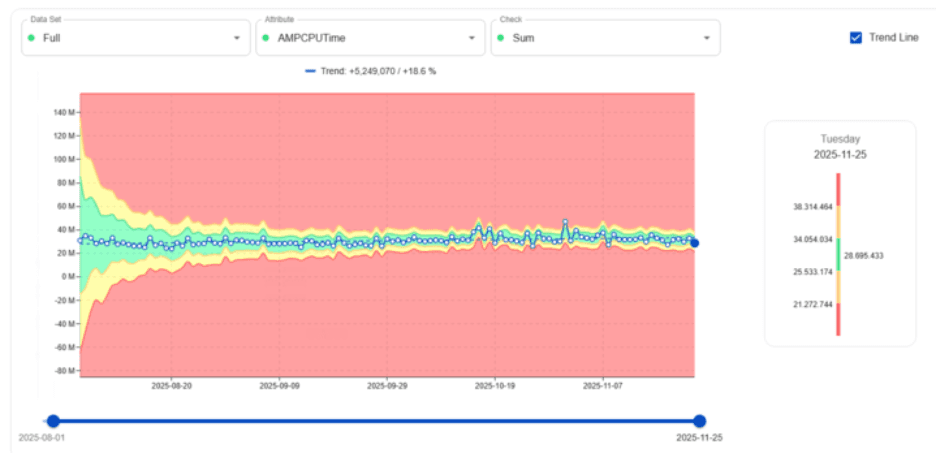
Jednym z najpotężniejszych przykładów jest to, jak digna uczy się AMPCPUTime dla całego systemu Teradata.
Na początku akceptowalny (zielony) zakres jest szeroki, ponieważ digna jeszcze obserwuje zmienność. Z czasem, im bardziej stabilna jest konsumpcja, tym węższy staje się zielony obszar. Ten ciaśniejszy pas oznacza, że digna dokładnie rozumie, jak wygląda „zdrowy” CPU—dzięki czemu może z dużą precyzją sygnalizować rzeczywiste anomalia.
Kluczowa wartość: digna redukuje eskalacje związane z CPU i pomaga zespołom przewidywać rosnące obciążenia zanim spowodują one incydenty.
Wczesne wykrywanie odmienności IO
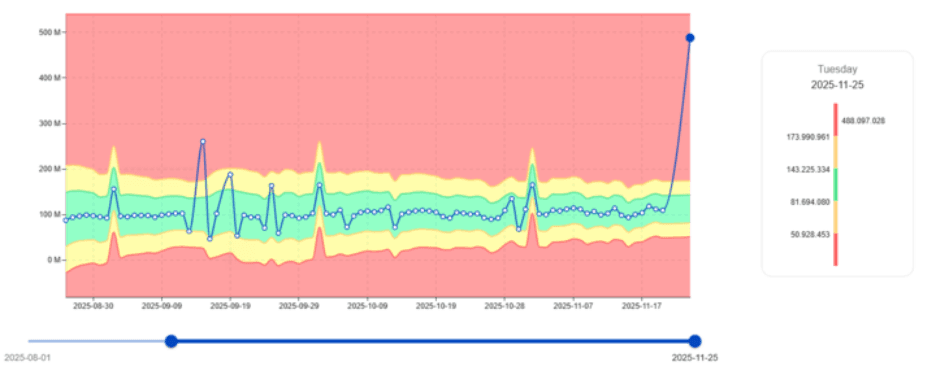
Skoki IO to jedne z najwcześniejszych wskaźników problematycznych obciążeń.
W przykładzie, który dodasz tutaj, digna identyfikuje zadanie, które nagle wykazuje IO daleko poza jego normalnym wzorcem—nawet jeśli CPU może wyglądać normalnie.
To wczesne wykrycie pozwala zespołom na zbadanie:
Zmiany w dystrybucji danych
Skanowania tabel
Skośne dołączanie
Niespodziewany wzrost danych
Niezoptymalizowaną logikę obciążeń
Kluczowa wartość: digna pomaga zespołom unikać wąskich gardeł IO, które spowalniają cały system.
Identyfikacja niestabilnych użytkowników CPU
Nie wszystkie zadania zachowują się konsekwentnie. Niektóre wykazują niespodziewaną zmienność w zużyciu CPU, co z czasem prowadzi do niestabilności klastrów.
Poniżej znajduje się obrazek pokazujący, jak digna wskazuje te anomalie.
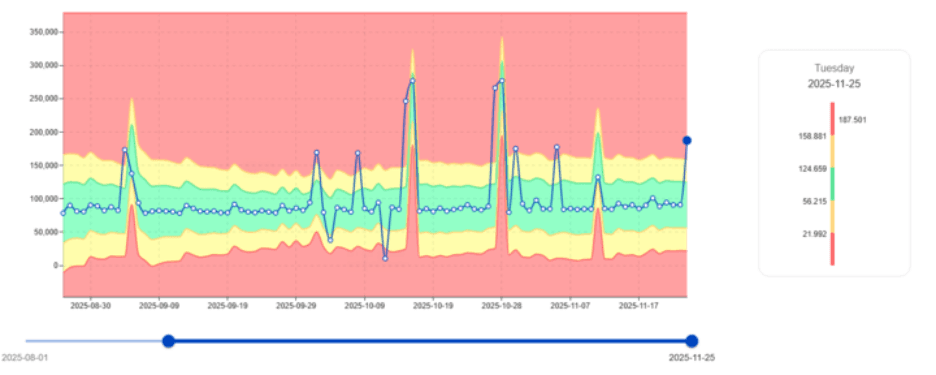
Niestabilne obciążenia CPU często wskazują na:
Złe plany zapytań
Zmiany w modelu danych
Optymalizacje wrażliwe na parametry
Drift w rozmiarach tabel
Skośność w dołączaniach lub agregacjach
Dzięki digna, te wzorce są wykrywane długo przed tym, jak staną się dużym incydentem.
Kluczowa wartość: digna odkrywa hałaśliwe obciążenia wcześnie, umożliwiając optymalizację CPU, która bezpośrednio redukuje koszty licencjonowania i infrastruktury.
Wykrywanie nagłej niestabilności CPU w krytycznych zadaniach
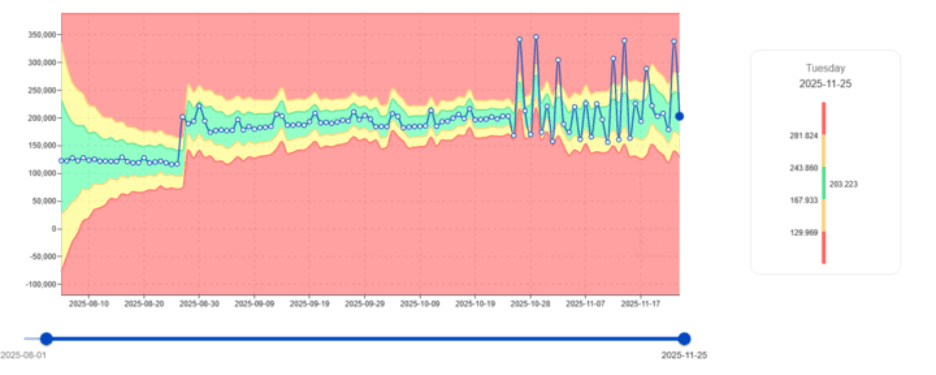
Czasami zużycie CPU jest stabilne przez miesiące—i nagle staje się chaotyczne.
To dokładnie ten rodzaj obciążenia, które digna ma uchwycić.
Te zmiany często wynikają z:
Migracji danych
Nowych demografii lub dystrybucji
Modyfikacji logiki ETL
Driftu w schemacie
Słabego utrzymywania indeksów
digna natychmiast oznacza takie wzorce, zaznaczając te obciążenia jako priorytetowe do analizy.
Wpływ na biznes: Wczesne wykrycie zapobiega wzrostom CPU, które mogą pogorszyć wydajność wśród setek użytkowników i obciążeń.
Rozpoznawanie i respektowanie wzorców sezonowych
Nie wszystkie skoki są anomaliami.
Niektóre obciążenia naturalnie się zmieniają:
Zamknięcia miesiąca
Tygodniowe cykle rozliczeń
Poniedziałkowe raporty
Ładunki danych na poczatku kwartału
Agrgacje pod koniec dnia
Na tym obrazku pokazano, jak digna automatycznie uczy się wzorców sezonowych.
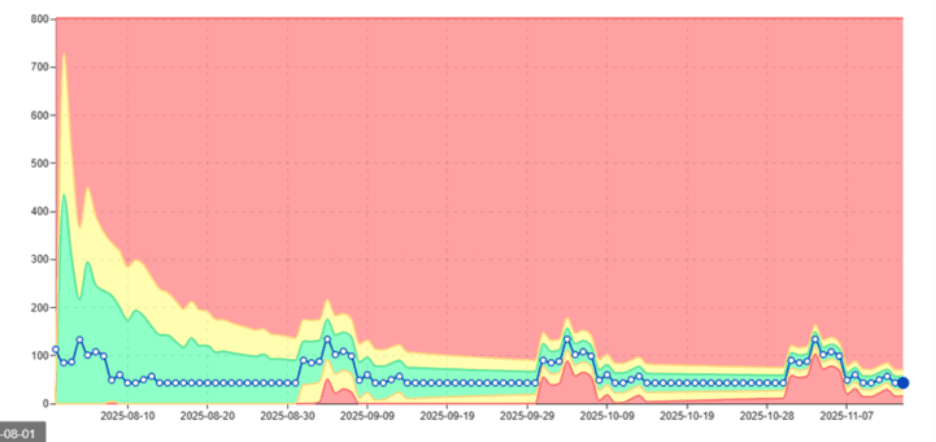
Zamiast błędnie alertować, digna rozumie:
Kiedy określone obciążenia powinny wzrosnąć
Jak stromo powinien wyglądać szczyt
Jakie wzorce się powtarzają w czasie
Kluczowa wartość: digna eliminuje fałszywe alarmy poprzez odróżnienie anomalii od naturalnej sezonowości.
Monitorowanie wzrostu bazy danych z trendami użycia perm
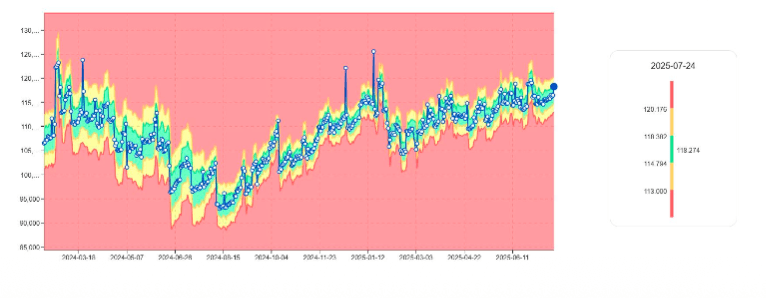
Perm usage jest podstawową metryką dla zarządzania pojemnością Teradata. digna:
Uczy się normalnej trajektorii rozmiaru
Oznacza nagłe wzrosty
Identyfikuje nienormalny wzrost tabel
Wykrywa skoki zużycia pamięci
To pomaga zapobiegać:
Błędom związanym z przestrzenią
Niespodziewanym pełnym skanom tabel
Ucieczkowym obciążeniom ELT
Kluczowa wartość: digna daje zespołom czas na reakcję zanim zużycie pamięci wpłynie na wydajność.
Wykrywanie skośności: Identyfikowanie nierównej dystrybucji danych

Skośność jest jednym z najczęstszych—i najkosztowniejszych—problemów wydajnościowych w Teradata.
Skośność występuje, gdy dane nie są równomiernie rozłożone w AMPs, powodując:
Wąskie gardła
Długie cykle CPU
Wolne dołączanie
Niespójności wydajności
digna automatycznie analizuje trendy skośności w czasie, aby pokazać:
Kiedy stół staje się skośny
Czy skośność się pogarsza
Które AMPy są dotknięte
Czy niedawne zmiany danych spowodowały nową skośność
Kluczowa wartość: digna wskazuje degradację związaną ze skośnością zanim wpłynie ona na wydajność na całej platformie.
digna konwertuje wszystkie metryki DBC na dane szeregów czasowych
To jest rdzeń dla wszystkiego, co opisano powyżej. Poprzez konwersję metryk tabel DBC na szereg danych czasowych, digna może:
Zdolności AI
Uczyć się wzorców CPU
Wykrywać anomalie IO
Modelować sezonowe fluktuacje
Śledzić zmienność poziomą zadań
Wykrywać powolny dryf danych
Monitorować długoterminową pojemność systemu
Zdolności Observability
Porównywać obciążenia w ciągu dni
Śledzić zmiany wydajności zapytań
Dostarczać historyczne trendy
Identyfikować regresje
Monitorować wzorce wzrostu
Powiadomienia i integracje
Email
Slack
Jira
Webhooks
Powiadomienia na poziomie modułu
Kluczowa wartość: silnik szeregów czasowych digna przekształca surowe metadane Teradata w działające wnioski.
Rzeczywisty wpływ: Większa stabilność, niższe koszty, mniej eskalacji
Na podstawie tego, jak zespoły używają digna dziś, platforma dostarcza:
Mniej spotkań eskalacyjnych: Ponieważ anomalie są wykrywane zanim problemy się eskalują.
Większa przewidywalność: Stabilne obciążenia = przewidywalne zużycie zasobów = łatwiejsza kontrola kosztów.
Zredukowane zużycie CPU i IO: Dzięki wczesnemu zidentyfikowaniu nieskutecznych obciążeń.
Silniejsza współpraca z zespołami biznesowymi: Problemy są naprawiane zanim użytkownicy biznesowi zauważą cokolwiek.
Mniej walki z ogniem dla zespołów inżynierskich: AI zajmuje się monitorowaniem, więc zespół może skupić się na zadaniach o wysokiej wartości.
Podsumowanie
Teradata Vantage dostarcza fundament dla danych i analityki przedsiębiorstw. digna podnosi ten fundament przez dodanie zautomatyzowanej warstwy monitoringu AI, która przekształca surowe metryki systemowe w rzeczywistą inteligencję operacyjną.
Poprzez ciągłe analizowanie CPU, IO, skośności, użycia perm i zachowania zadań, digna umożliwia zespołom inżynieryjnym na:
Poprawę wydajności
Zapobieganie przestojom
Redukcję kosztów chmury/w on-prem
Pracę proaktywnie, zamiast reaktywnie
To jest nowa generacja analizy obciążeń Teradata—napędzana przez AI, zautomatyzowana i stworzona dla skali przedsiębiorstw.
Obejrzyj nasze demo i poznaj optymalizację zarządzaną przez AI dla CPU, IO i efektywność kosztową w twoim środowisku Teradata lub skontaktuj się z nami.



