Data Lake vs Data Mart: Build Your Ideal Data Platform
|
0
min. czyt.

Your team probably knows this feeling already. Finance closes the month and one dashboard says revenue is up. Sales pulls a different report and gets a different number. Marketing has campaign data sitting in a BI tool, product has event logs in object storage, and engineering has raw JSON landing somewhere nobody outside the platform team wants to touch. Everyone agrees the company has “a lot of data.” Nobody agrees on which dataset to trust.
That's usually the moment the data lake vs data mart question stops being theoretical. It becomes an operating decision. Do you need a broad landing zone for raw, messy, multi-format data, or a focused analytics layer that gives business users fast answers with less ambiguity? This is often framed as a storage and modeling choice. In practice, it's also a question about failure modes, ownership, and how much operational friction your team is willing to absorb.
Table of Contents
The Crossroads of Data Strategy
A company usually doesn't arrive at this decision through elegant architecture planning. It gets there because daily work starts breaking down. Analysts spend more time reconciling reports than interpreting them. Engineers patch one pipeline while another slips behind schedule. Department heads build private extracts because the shared platform feels too slow or too opaque.
That's the real crossroads. A data lake gives you a place to ingest almost everything without forcing immediate structure. A data mart gives a business team a narrower, cleaner surface built for a known purpose. Both are useful. Both can fail badly when the operating model around them is weak.
One pattern shows up over and over. A business wants self-service reporting, so teams rush to expose more datasets to more users. But if those datasets don't share definitions, freshness expectations, and ownership, self-service turns into self-interpretation. If your organization is moving in that direction, it helps to explore self-service BI on WeekBlast alongside your platform decisions, because reporting freedom only works when the underlying data contract is stable.
The architecture question is really an operating question
A lake favors flexibility. It works well when product telemetry, application logs, documents, image files, and partner feeds all need to land somewhere before anyone knows the final analytical shape. A mart favors consistency. It works well when finance needs a controlled reporting layer, or sales needs one KPI model that nobody can reinterpret on the fly.
The mistake is treating these as interchangeable storage labels. They create different support burdens.
In a lake, teams usually fight ambiguity. Which table is current? Which schema version is valid? Did the source system add a field that broke downstream logic without warning?
In a mart, teams usually fight bottlenecks. Who owns the metric definition? How long does model change approval take? Why is one department's quick solution now a silo?
A lot of teams also discover that platform topology affects data quality ownership. Centralized control can improve consistency but slow down local delivery. Decentralized ownership can speed up domain work but create fragmentation unless quality standards travel with the data product. That tension is at the center of data mesh vs centralized data platforms and data quality.
The wrong platform choice rarely fails on day one. It fails six months later, when more users depend on it and nobody can explain why the same metric keeps changing.
Understanding the Core Concepts
The cleanest way to understand data lake vs data mart is to look at intent, not tooling.
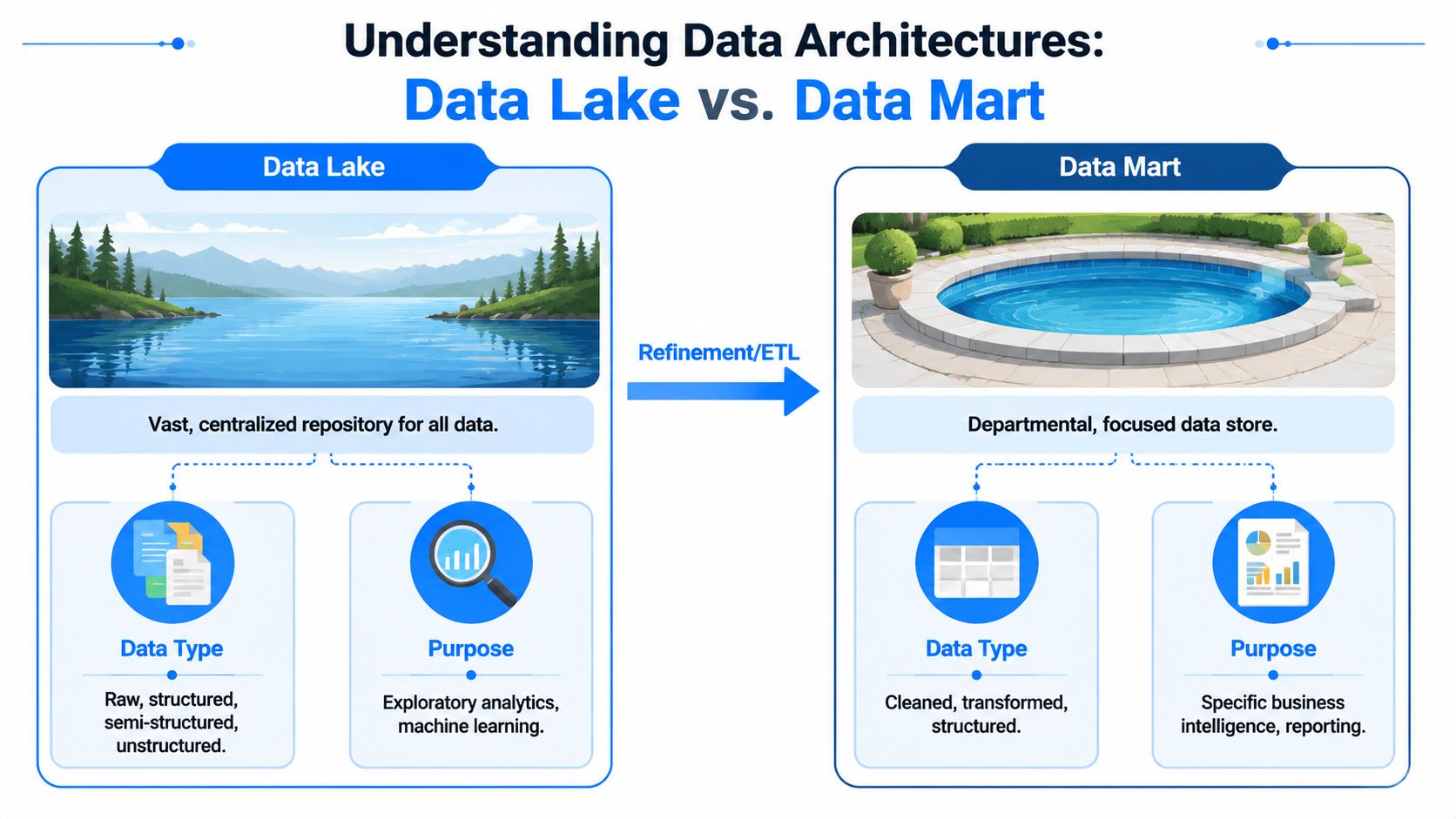
A data lake is a centralized, scalable repository that ingests and stores large volumes of raw data in native form, including structured, semi-structured, and unstructured formats, according to Dataversity's explanation of data lake and data mart differences. That means tables can sit next to JSON logs, text documents, images, audio, or video. The point isn't polish. The point is retention, exploration, and later reuse.
A data mart is a structured, purpose-built subset designed for a specific business unit or analytical use case. It contains data that's already been cleaned, transformed, and organized for reporting and business analysis, as described in Atlan's breakdown of data mart vs data lake. The point isn't optionality. The point is usability.
Why the philosophies differ
Think of the lake as a raw materials yard. You bring in logs, exports, events, media files, and partner payloads because you may need them later, and because forcing them into a rigid model too early usually strips out value. Data scientists and engineers like this setup because it preserves detail and makes exploratory work possible.
Think of the mart as a finished goods shelf. The data has already been shaped into dimensions, facts, approved definitions, and expected refresh cycles. Business analysts, finance leads, and operational managers like this setup because they can ask known questions and get stable answers quickly.
A useful shorthand is this:
Lake: store first, interpret later
Mart: model first, serve now
That philosophical difference drives everything downstream, from ingestion design to access controls to on-call alerts.
Where teams get confused
The confusion starts when a team expects one architecture to behave like the other. They put raw event data into a lake, then expect BI dashboards to behave like a curated semantic layer. Or they push every analytical need into a mart, then discover that machine learning, log forensics, and exploratory joins keep getting blocked by rigid upstream modeling.
A modern hybrid pattern tries to bridge some of this gap. If your team is evaluating that route, a practical next step is understanding what a lakehouse is and how to maintain data quality. The key reason that topic matters here is operational: hybrid designs reduce some duplication, but they don't remove the need for clear quality controls.
A lake answers “what do we have?” A mart answers “what should the business use?”
Architectural Deep Dive A Side by Side Comparison
The architectural differences look simple on a slide and messy in production. The shape of the data, when schema gets applied, who the primary users are, and how broadly the platform is meant to serve all change how the system behaves under pressure.
Data Lake vs Data Mart at a Glance
Attribute | Data Lake | Data Mart |
|---|---|---|
Primary purpose | Store broad, raw data for reuse and exploration | Serve a specific business function with curated analytics |
Data formats | Structured, semi-structured, and unstructured data in native form | Structured, transformed, business-ready data |
Schema model | Schema-on-read | Schema-on-write |
Typical users | Data engineers, data scientists, ML teams | Business analysts, BI developers, department leaders |
Source diversity | Internal and external, often highly heterogeneous | Usually selected business data relevant to one domain |
Scope | Enterprise-wide landing and reuse layer | Department or use-case-specific consumption layer |
Data preparation timing | Minimal transformation on ingestion | Cleaning and modeling happen before delivery |
Best fit | Exploration, experimentation, long-term retention | Reporting, recurring analysis, defined KPIs |
Common operational headache | Drift, discoverability, unclear ownership | Metric bottlenecks, duplication across departments |
What the table means in practice
The schema-on-read model in a lake gives engineers freedom. You can ingest first and decide structure later. That's valuable when source systems evolve quickly or when the business hasn't yet defined the downstream questions. It's also the reason lakes can become difficult to govern. If three teams interpret the same raw field differently, the platform hasn't failed technically. It has failed operationally.
The schema-on-write model in a mart does the opposite. It forces decisions early. Column types, joins, grain, metric definitions, and naming conventions all have to be resolved before users consume the data. That slows initial delivery, but it usually reduces downstream argument because the business sees a narrower and more deliberate interface.
Here's where teams often underestimate the difference:
Ingestion into a lake is easier to start. It's harder to standardize later.
Delivery into a mart is slower to start. It's easier to support once stabilized.
A lake invites many use cases. A mart rejects vague use cases by design.
A lake preserves raw evidence. A mart packages approved answers.
The user experience is shaped by the architecture
A data scientist opening a lake expects optionality. They'll inspect raw fields, test transformations, and tolerate some inconsistency if the platform preserves fidelity. A finance analyst opening a mart expects confidence. They want a small set of trusted tables and fast, repeatable queries.
That's why the data lake vs data mart decision should be tied to user contracts, not just storage patterns. If the audience needs flexibility, don't hide raw data behind over-curated abstractions. If the audience needs consistency, don't expose them to half-finished ingestion zones and ask them to “figure it out.”
Performance Cost and Governance Tradeoffs
Most architecture debates get framed as flexibility versus speed. That's true, but it's incomplete. The more expensive part is often the labor required to keep the platform trustworthy.
Data marts generally feel better for day-to-day BI because the data is already shaped for known access patterns. According to Yandex Cloud's comparison of data mart and data lake performance, data marts often deliver 3 to 5x latency reduction compared to data lakes because they use a structured schema-on-write design and curated datasets optimized for business functions.

Why marts feel faster to the business
A mart removes work before query time. It already knows the grain, dimensions, filters, and accepted business logic. That means BI tools and analysts spend less time scanning, casting, and joining ambiguous source data.
Operational rule: If the same dashboard question gets asked every week, it probably belongs on curated data, not raw data.
That speed has a cost. Someone has to design and maintain the transformations, approve definition changes, and keep separate marts from drifting apart. If marketing and finance each build “customer revenue” slightly differently in separate marts, the business gets speed but loses shared truth.
Where the hidden costs show up
A lake lowers the barrier to ingestion and scales better for broad data capture. But governance in a lake doesn't happen automatically. Teams need metadata, ownership, data contracts, lineage, access controls, and query discipline. Without those controls, low-cost storage turns into high-cost confusion.
Two common failure patterns show up:
The data swamp problem: raw assets accumulate faster than teams can document, classify, and validate them.
The replay tax: because downstream logic is loose, engineers spend time rerunning jobs, revalidating assumptions, and explaining inconsistent outputs.
Marts have their own version of operational debt.
The silo problem: each department wants a custom view, and local optimization gradually fragments enterprise definitions.
The change queue problem: a small modeling team becomes the bottleneck for every new metric or schema adjustment.
A cheap platform that takes constant human intervention to trust isn't actually cheap.
Governance also lands differently. In a mart, governance is visible because the model is explicit. In a lake, governance is often invisible until it breaks, because permissive ingestion can hide quality issues until consumption time.
Real World Use Cases for Lakes and Marts
Architectures make more sense when you attach them to actual jobs. The question isn't “which one is modern?” It's “which one reduces friction for this workload without creating avoidable cleanup later?”
Start with the lake side. A product team collecting web logs, clickstream events, support transcripts, and image uploads usually needs one place to retain those assets before anyone knows the final analytical model. That's a lake problem. The same is true for IoT telemetry, fraud investigation pipelines that need raw transaction patterns, or ML feature experimentation where preserving source granularity matters.

When a lake is the right working surface
A lake works well when the value comes from exploration before standardization.
Machine learning training: teams often need raw historical records, event sequences, and non-tabular inputs that don't fit cleanly into a departmental reporting model.
Incident and forensic analysis: engineers can trace original payloads, logs, and source events instead of relying on summarized outputs.
New product analytics: when the business doesn't yet know which metrics matter, forcing a mart too early usually creates churn.
The lake is especially useful when multiple future use cases may emerge from the same raw source. Product, risk, data science, and compliance can all derive different outputs from one retained dataset.
A short walkthrough helps. A retail platform stores web session logs, support messages, product images, and transaction exports in a lake. Data scientists use the raw history to test recommendation features. Risk analysts investigate unusual transaction paths. Later, analytics engineers transform a subset into curated commercial reporting assets. The lake isn't the final product. It's the working surface.
The video below gives a simple visual explanation of how these patterns differ in practice.
When a mart is the better product
A mart works well when the business already knows the questions and needs dependable answers.
Sales is the classic example. Regional leaders want pipeline coverage, bookings, win rates, and attainment reporting in one place. They don't want to inspect raw CRM snapshots or event payloads. They want a trusted model with stable refresh behavior.
The same applies in finance and marketing:
Finance reporting: quarter-end and monthly close processes need controlled dimensions, reconciled facts, and clear definitions.
Campaign analysis: marketing teams need a reporting surface tied to approved attribution logic, not a sandbox of semi-structured source feeds.
Operations dashboards: supply chain or support leaders need repeatability more than flexibility.
A mart is best treated as a product for a known audience. If everyone can redefine it, it stops being a mart and starts becoming another raw layer with nicer table names.
Making the Right Choice Data Lake Data Mart or Both
Teams often ask for a binary answer. In practice, the right answer depends on what the platform must do first, who depends on it, and how mature the operating model is.
Choose based on the job not the trend
Choose a lake first when your core need is broad ingestion, long-term retention, exploratory analysis, or AI and ML work with mixed data types. If your data sources include logs, documents, media, event streams, and partner feeds, a lake handles that variability better than a narrow reporting structure.
Choose a mart first when the business is asking for faster reporting on established KPIs and a limited set of domains. If sales, finance, or operations need consistent numbers next quarter, a mart often delivers business value faster because it narrows the problem.
A practical decision filter looks like this:
Your users need raw access and experimentation: lean lake.
Your users need governed dashboards and recurring reports: lean mart.
Your platform team is small and the metric scope is known: a mart may be more supportable.
Your data sources evolve constantly and formats vary widely: a lake gives you room to absorb change.
Why many teams end up with both
A common operating model lands raw or lightly processed data in a lake, then publishes curated domain-specific outputs into marts or mart-like consumption layers. That setup reflects reality. Different users need different contracts.
The main risk is duplication without discipline. If the lake becomes unmanaged and each department independently builds its own mart logic, your architecture diagram looks flexible while your operating model becomes brittle.
A more balanced pattern is to keep raw and reusable assets in a central layer, then expose business-facing models only where there's a clear owner and a stable consumer need. Teams planning that transition usually benefit from practical migration thinking, especially when existing warehouse or mart assets already power production reporting. In these circumstances, data warehouse to data lake migration best practices for seamless transition are pertinent, because the move only works if quality and delivery expectations survive the handoff.
One more point matters. If your organization needs both flexible exploration and dependable BI, the architecture question may point toward a lakehouse-style approach. That doesn't remove governance work. It just reduces some of the friction of running disconnected systems.
Implementing Data Quality and Observability
The architectural choice shapes how bad data breaks, how quickly teams notice, and how hard root-cause analysis becomes.
A lake usually fails in quiet ways. A source system adds a column. A data type changes. A nested field arrives with different structure. Ingestion still completes, but downstream parsing, joins, or feature generation starts producing subtle damage. According to the JMIR analysis on schema drift and pipeline failure rates, data lakes can see 30 to 40% higher pipeline failure rates because they lack schema enforcement and are more exposed to silent schema drift and data type mismatches that traditional monitoring misses.
How failures look different in each architecture
In lakes, quality incidents often begin upstream and surface late. The pipeline technically “ran,” but the shape of the data moved under your feet. Standard job monitoring won't catch that reliably because job success isn't the same as data correctness.
In marts, the failures are usually more visible but still damaging. A transformation job runs late. A dimension table doesn't refresh. A business rule changes and the curated model keeps applying yesterday's logic. Dashboards load, but they're stale or semantically wrong.
That means observability has to cover different risk types.
For lakes: schema change detection, freshness monitoring at ingestion boundaries, and anomaly detection on volumes, null behavior, and distribution shifts.
For marts: timeliness monitoring on scheduled deliveries, validation on key business rules, and anomaly detection on KPI outputs that may look valid syntactically but are wrong operationally.
The team doesn't lose trust when a pipeline fails loudly. Trust erodes when the data is wrong and nobody notices until a stakeholder does.
What modern monitoring actually needs to cover
Basic orchestration alerts aren't enough. They tell you whether a task ran, not whether the data remained fit for use. A serious observability setup needs to watch several layers at once:
Structure: added columns, removed columns, data type changes, and partition irregularities.
Freshness: expected arrival windows for source loads and curated tables.
Content behavior: volume shifts, null spikes, distinct count changes, and unexpected distribution movement.
Business validity: rule-based checks for fields that must obey business logic.
Traceability: enough lineage and ownership metadata to assign remediation quickly.
The practical implication in the data lake vs data mart debate is simple. Lakes need stronger structural and behavioral monitoring because flexibility creates ambiguity. Marts need stronger delivery and semantic monitoring because consumers assume the data is already trustworthy.
If your team is running either architecture without active observability, you're relying on downstream users to become your monitoring system. That's expensive, slow, and corrosive to trust.
If you need stronger control over silent drift, late loads, broken transformations, and hard-to-diagnose anomalies across lakes, marts, or hybrid platforms, digna gives data teams one place to monitor timeliness, schema changes, validations, and AI-based anomaly detection while keeping data inside customer-controlled environments.



