Architecture des pipelines de données : Le guide complet pour 2026
|
0
minute de lecture

Le rapport semblait correct à 8h00. À 9h15, le service financier l'avait déjà utilisé lors d'une réunion. À l'heure du déjeuner, quelqu'un a remarqué que les totaux étaient erronés, non pas parce que le SQL était incorrect, mais parce qu'une table en amont avait cessé de recevoir un sous-ensemble d'enregistrements pendant la nuit. Aucune alerte ne s'est déclenchée. Techniquement, le pipeline a « fonctionné ». Le tableau de bord affichait une confiance obsolète.
C'est le mode de défaillance auquel de nombreuses organisations sont confrontées en ce moment. Pas des pannes spectaculaires. Une corruption silencieuse. Un fichier manquant, un changement de schéma, une transformation qui s'exécute toujours mais associe désormais le mauvais champ, un flux arrivant en retard qui transforme un KPI frais en réponse de la veille. Une fois que cela se produit, la confiance chute plus rapidement que n'importe quelle métrique système ne vous l'indiquera.
Une architecture de pipeline de données solide résout bien plus que le simple déplacement de la source vers la destination. Elle détermine si votre plateforme de données est un outil auquel les opérateurs font confiance sous pression, si les analystes peuvent expliquer les chiffres sans deviner, et si les entrées du modèle restent stables à mesure que les systèmes sources évoluent. Le plus difficile n'est pas de dessiner des boîtes. C'est de concevoir le pipeline de manière à ce que la qualité, la ponctualité et la visibilité existent dès le premier schéma, et non après la première escalade de la direction.
Les équipes qui travaillent avec des entrées mixtes y font face de manière encore plus aiguë lorsque des documents semi-structurés entrent dans le flux. Si votre pipeline inclut l'extraction de documents pour des cas d'usage d'IA, ce guide pratique pour convertir les PDF pour les LLM mérite d'être examiné, car les erreurs de structure des documents commencent souvent bien avant la modélisation. Pour obtenir une base visuelle de la manière dont ces systèmes s'articulent, un simple diagramme d'architecture de données permet d'aligner la discussion avant de toucher aux outils.
Table des matières
Votre guide de l'architecture moderne des pipelines de données
Intégrer la qualité des données et l'Observability dès la conception
Votre guide de l'architecture moderne des pipelines de données
Une définition utile de l'architecture de pipeline de données est simple : c'est le plan d'exploitation pour la collecte, la modification, le stockage et la distribution des données sans en perdre le sens en cours de route. Cela semble simple jusqu'à ce que vous héritiez d'un système où l'ingestion, les transformations, les planifications, le stockage et les tableaux de bord ont tous été construits à des moments différents par des équipes différentes.
En pratique, l'architecture se manifeste dans les schémas de défaillance. Une conception rigide rend les équipes craintives à l'idée de modifier quoi que ce soit. Un transfert fragile entre l'ingestion et la transformation permet à des enregistrements malformés de descendre le flux. Une couche de reporting sans attente de fraîcheur habitue l'entreprise à découvrir les problèmes manuellement. Rien de tout cela ne se résout en ajoutant un orchestrateur ou un tableau de bord de plus.
L'architecture doit également refléter la façon dont les gens travaillent réellement. Les analystes veulent des tables stables. Les équipes de plateforme veulent un déploiement reproductible. Les ingénieurs ML veulent des entrées qui ne dérivent pas de manière invisible. Les équipes de sécurité veulent que les données restent au sein d'environnements contrôlés. Un plan moderne doit satisfaire tout le monde sans devenir un labyrinthe.
Les pipelines fiables ne sont pas ceux qui ne échouent jamais. Ce sont ceux qui échouent d'une manière que les opérateurs peuvent voir, isoler et corriger rapidement.
C'est pourquoi les meilleures conceptions traitent le pipeline moins comme de la plomberie et plus comme un système de production. Chaque étape a un propriétaire. Chaque dépendance est visible. Chaque chemin de livraison a une attente de ponctualité et d'exactitude. Si vous construisez avec ces hypothèses, le reste des décisions devient beaucoup plus clair.
Les quatre piliers d'un pipeline de données
La façon la plus simple d'enseigner la conception de pipelines est d'emprunter une analogie avec la cuisine. Les ingrédients arrivent des fournisseurs, sont stockés en toute sécurité, préparés par des cuisiniers, et enfin servis aux clients. Si une étape échoue, le client ne se soucie pas de savoir quel poste a failli. Il sait simplement que le repas est en retard ou incorrect.

Penser comme une ligne d'opérations
La version technique repose sur quatre piliers pratiques :
L'Ingestion extrait les données des systèmes sources. Cela peut désigner des API, des bases de données transactionnelles, des outils SaaS, des flux d'événements ou des dépôts de fichiers.
Le Stockage conserve les données brutes ou préparées dans un endroit durable, souvent dans des plateformes comme Amazon S3, Snowflake ou Databricks.
Le Traitement transforme les données en quelque chose d'exploitable. Il implique le nettoyage, la déduplication, le filtrage, le formatage et les jointures.
La Distribution expose le résultat aux tableaux de bord, aux outils de reverse ETL, aux modèles, aux applications ou aux consommateurs en aval.
L'un des résumés modernes les plus clairs provient de l'explication de Striim sur les composants d'un pipeline de données moderne, qui décrit le cœur comme l'ingestion, la transformation et le stockage, et note que les échecs de transformation entraînent directement des rapports obsolètes et des tableaux de bord cassés lorsque des données malformées atteignent la couche de consommation. Je sépare toujours la distribution comme une préoccupation architecturale propre car de nombreuses équipes construisent le pipeline mais sous-conçoivent le transfert vers les personnes et les systèmes qui le consomment.
Là où les équipes se trompent généralement
Les erreurs se produisent rarement aux extrémités. Elles surviennent lors des transitions.
Quelques exemples reviennent constamment :
Les données brutes arrivent sans vérification de contrat. Le pipeline accepte les enregistrements, mais personne ne vérifie si des champs clés sont de type incorrect ou manquants.
Le stockage devient un dépotoir. Les équipes conservent chaque version de chaque élément mais ne distinguent pas les zones de réception, de traitement et prêtes pour les consommateurs.
Les transformations deviennent un monolithe. Une seule tâche immense gère toute la logique, de sorte que le débogage d'une métrique nécessite de lire l'ensemble du domaine.
La distribution est traitée comme « juste de la BI ». En réalité, la cohérence sémantique, les attentes de fraîcheur et les schémas d'accès ont tous leur place ici.
Règle pratique : Si un consommateur ne peut pas expliquer d'où vient un chiffre, votre couche de distribution n'est pas finalisée.
Une bonne architecture maintient chaque pilier suffisamment distinct pour fonctionner de manière autonome, mais assez connecté pour que les défaillances ne se cachent pas entre eux. Cette séparation est ce qui rend les décisions ultérieures sur les modèles, la résilience et l'observabilité gérables plutôt que chaotiques.
Principaux modèles architecturaux de pipelines de données
Les modèles architecturaux sont le domaine où les équipes commettent des erreurs coûteuses car chaque option fonctionne bien pour un cas précis. Le mauvais choix n'est généralement pas une « mauvaise technologie ». C'est une inadéquation entre les besoins de latence, la complexité opérationnelle et le type d'analyse requis par l'entreprise.
ETL et ELT résolvent des problèmes différents
L'ETL convient aux environnements où la transformation doit se produire avant que les données n'arrivent à destination. C'est fréquent lorsque le nettoyage initial est strict, que la capacité de calcul de destination est limitée ou que la gestion réglementaire exige des contrôles avant le chargement.
L'ELT fonctionne mieux lorsque la plateforme de destination est conçue pour des traitements lourds et que les équipes souhaitent de la flexibilité après le chargement. Les bases de données décisionnelles (warehouses) et les lakehouses ont rendu ce modèle beaucoup plus pratique car vous pouvez charger les données rapidement et les façonner plus tard avec des transformations basées sur SQL.
Aucun modèle n'est universellement supérieur. L'ETL offre un contrôle plus serré avant l'ingestion. L'ELT offre plus d'agilité pour les équipes d'analyse. Si vous évaluez des outils pour l'amont du pipeline, cet aperçu des logiciels d'ingestion de données est un endroit utile pour comparer l'impact des décisions de capture source sur le reste de la pile.
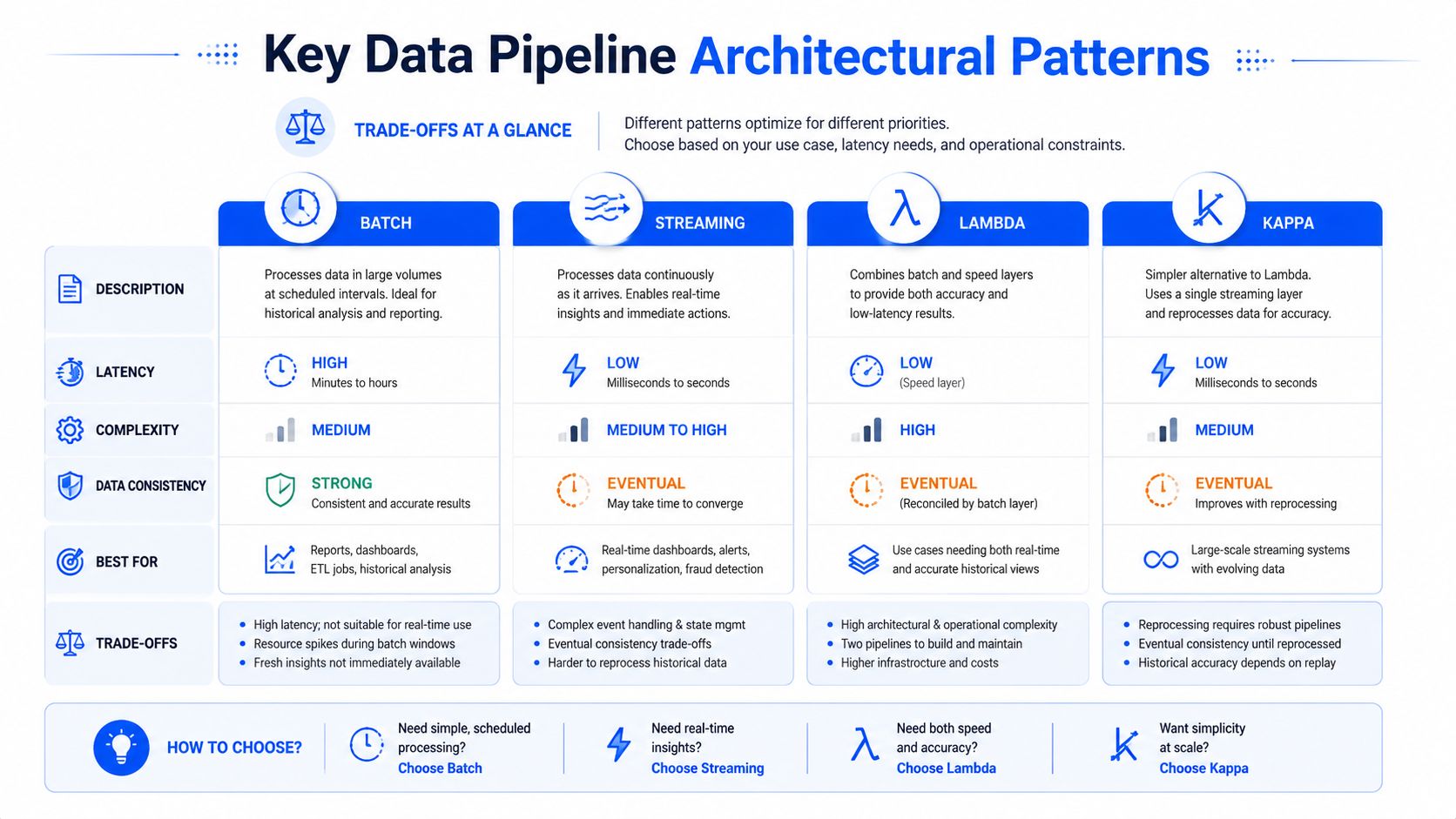
Batch, streaming, lambda et kappa
Le traitement par lots (batch) et le streaming représentent une bifurcation plus importante.
Le batch est le meilleur choix lorsque l'entreprise peut tolérer des livraisons planifiées et que le pipeline doit traiter de grands volumes historiques de manière cohérente. Les rapports financiers de fin de journée en sont un exemple classique. Le streaming s'adresse aux situations où le retard nuit à l'utilité même du cas d'usage, comme la surveillance opérationnelle, les alertes ou les flux de travail pilotés par les événements.
Les formes hybrides importent lorsque vous avez besoin des deux. L'article de Striim sur les modèles d'architecture Lambda et Kappa illustre bien cette distinction. L'architecture Lambda équilibre la rapidité du temps réel avec la fiabilité du batch en exécutant des flux de données parallèles. Un chemin à chaud gère le streaming en temps réel, un chemin à froid gère le traitement historique, et une couche de distribution fusionne les résultats. L'architecture Kappa supprime la couche batch distincte et gère à la fois le temps réel et l'historique via un seul pipeline de streaming, ce qui simplifie les opérations en éliminant les systèmes doublés.
Cette simplification est séduisante, mais Kappa présente un véritable compromis. Retraiter l'historique des flux via un seul pipeline n'est élégant que si vos outils, votre stratégie de rétention et votre discipline opérationnelle sont assez solides pour supporter le rejeu en toute sécurité.
Comparaison des modèles de pipelines de données
Modèle | Cas d'usage principal | Avantages | Inconvénients |
|---|---|---|---|
Batch | Analyses planifiées et rapports périodiques | Prévisible, adapté aux grands volumes historiques, plus facile à appréhender | Latence plus élevée, moins adapté aux réponses opérationnelles immédiates |
Streaming | Cas d'usage événementiels et visibilité en temps réel | Faible latence, idéal pour les alertes et les opérations en direct | Gestion des erreurs, rejeu et gestion des états plus complexes |
Lambda | Équipes nécessitant à la fois une profondeur historique et des insights immédiats | Associe la fiabilité du batch et la rapidité du temps réel | Deux chemins à concevoir, tester et maintenir |
Kappa | Environnements centrés sur le streaming souhaitant un seul modèle de traitement | Modèle opérationnel plus simple que les systèmes à double chemin | La stratégie de rejeu et la rigueur du streaming deviennent critiques |
Une banque peut utiliser le batch pour les rapports réglementaires, le streaming pour les signaux de fraude, et un modèle hybride pour l'activité des clients qui nécessite une réaction immédiate doublée d'une réconciliation historique. C'est tout le principe. Choisissez le modèle qui correspond à la fenêtre de décision, et non celui qui semble le plus moderne sur une présentation.
Construire des pipelines qui ne cassent pas
Les pipelines qui causent le plus de soucis sont généralement ceux qui « fonctionnaient très bien » jusqu'à ce que l'entreprise change. Une nouvelle source arrive. Un champ est renommé. Une équipe ajoute de la logique pour un tableau de bord, une autre ajoute des fonctionnalités de ML, et soudainement une défaillance paralyse trois sorties sans lien parce que tout réside dans la même chaîne rigide.

La modularité est un trait de survie
La conception modulaire n'est pas une question de style. C'est ce qui empêche un changement de se transformer en panne.
La discussion de Monte Carlo sur l'architecture de pipeline modulaire et automatisée va droit au but : les pipelines fiables doivent être modulaires et automatisés, tandis que les conceptions non modulaires créent des ruptures qui dissuadent les équipes d'y apporter des modifications. Cette description est d'une justesse douloureuse. Dès lors que les gens craignent de modifier un pipeline, sa qualité commence à se dégrader car les problèmes connus subsistent plus longtemps qu'ils ne le devraient.
Une structure modulaire pratique comprend généralement :
Des unités d'ingestion alignées sur les sources capables d'échouer ou de rejouer de manière autonome.
Des couches de transformation avec des contrats clairs afin que la logique de préparation, de conformité et métier ne s'effondrent pas en une seule étape.
Des vérifications de qualité réutilisables intégrées au module plutôt que de résider dans un tableur externe.
L'automatisation du déploiement pour que les versions soient reproductibles et que les retours en arrière ne relèvent pas du travail héroïque.
Tests de lignage et exécution parallèle
Le point de défaillance suivant est l'aveuglement face aux dépendances. Les équipes pensent savoir ce qui consomme une table jusqu'à ce qu'elles suppriment une colonne et cassent une métrique dont personne ne se rappelait l'existence.
Le suivi automatisé du lignage corrige cela. Le suivi manuel ne survit pas à la complexité, surtout lorsque plusieurs outils d'orchestration, d'entrepôts de données et de couches de distribution sont en jeu. Lorsqu'un pipeline glisse ou qu'un schéma change, le lignage réduit l'analyse des causes profondes, passant de conjectures à une recherche délimitée.
Voici la séquence opérationnelle que je recommande avant de considérer un pipeline comme prêt pour la production :
Isoler les composants afin qu'un changement ne nécessite pas une refonte complète.
Rédiger des attentes d'interface pour chaque transfert, y compris pour le schéma et la ponctualité.
Tester les modules et l'ensemble des chemins car un test unitaire propre ne détectera pas de mauvaises hypothèses entre les étapes.
Un guide utile sur les pratiques de pipelines résilients est disponible ci-dessous.
Et un autre aspect est souvent négligé : l'exécution parallèle n'est pas une optimisation que l'on ajoute à la fin. Pour les charges de travail modernes, elle doit faire partie intégrante de la conception. Lorsque des tâches indépendantes peuvent s'exécuter simultanément, vous réduisez les goulots d'étranglement et préservez les fenêtres de livraison à mesure que le volume de données augmente. Si vous ne planifiez pas cela dès le départ, chaque augmentation de l'activité source se transforme en problème de planification.
Construisez le pipeline de façon à ce qu'une équipe puisse modifier un composant sans avoir à demander l'autorisation à cinq autres équipes.
Sécuriser les pipelines de données dans votre environnement
L'architecture de sécurité commence par une question directe : où résident les données pendant l'exécution du pipeline ? De nombreuses équipes se concentrent sur le chiffrement et le contrôle d'accès mais ignorent le mouvement des données. C'est une erreur, en particulier dans les secteurs de la finance, de la santé, des télécoms et du secteur public, où la résidence des données et les chemins d'exposition comptent autant que la logique de transformation.
La résidence des données modifie la conception
Les déploiements sur site (on-premise) et en cloud privé imposent une meilleure discipline architecturale car ils ne vous permettent pas d'éluder la question de l'emplacement des données sensibles. Si un pipeline copie des données de production dans des zones de transit non gérées, élargit l'accès pendant la transformation ou envoie des charges utiles à des services externes pour des contrôles de qualité, vous étendez la surface d'attaque avant même que les données n'atteignent les outils d'analyse.
Maintenir l'exécution au sein de l'environnement contrôlé par le client change cette posture. Cela réduit les mouvements inutiles, restreint l'accès aux données de production et simplifie grandement les audits. Cela s'avère crucial lorsque des données réglementées doivent résider dans un environnement spécifique ou lorsque la politique interne interdit l'accès des tiers à des ensembles de données réels.
Les contrôles de sécurité qui ont leur place dans le plan
Une architecture de pipeline de données sécurisée partage généralement plusieurs caractéristiques :
Le chiffrement en transit et au repos pour que l'extraction, le transfert et le stockage ne créent pas de points d'exposition en texte clair.
L'accès basé sur les rôles qui sépare les opérateurs de pipelines, les développeurs, les analystes et les utilisateurs métier.
La segmentation des environnements pour que le développement, les tests et la production ne se mélangent pas.
Des chemins de validation vérifiables pour les règles métier ayant des implications de Compliance.
Une conception limitant les copies afin d'éviter que l'architecture ne génère des ensembles de données sensibles doublés uniquement pour les surveiller.
La sécurité croise également les attentes de livraison. Si votre architecture intègre des SLA sur la ponctualité et la détection des retards, les opérateurs peuvent analyser un retard anormal à la fois comme un problème de fiabilité et comme un signal potentiel de sécurité. Un flux qui s'arrête de manière inattendue peut provenir de la source, mais il peut aussi s'agir d'un problème d'identifiants, de politique ou de connectivité méritant une attention immédiate.
Les conceptions les plus robustes considèrent la Compliance comme une propriété architecturale et non comme un exercice de documentation. Si vous avez besoin de qualité des données, de détection d'anomalies et de suivi de schéma, concevez ces contrôles de façon à ce qu'ils s'exécutent là où les données résident déjà. C'est généralement plus sûr, plus facile à gouverner et plus simple à défendre lors d'un audit.
Intégrer la qualité des données et l'Observability dès la conception
De nombreuses organisations pensent disposer d'une observabilité alors qu'elles n'ont en réalité qu'une surveillance de la destination. Elles savent si la table de l'entrepôt existe. Elles savent si la tâche de BI s'est terminée. Elles ne savent pas si les données sont entrées dans le pipeline dans un état sain, si elles ont changé de forme de manière dangereuse ou si elles sont arrivées assez en retard pour fausser le rapport.

L'Observability commence dès l'ingestion
Cette lacune explique précisément pourquoi l'observabilité doit s'intégrer directement dans l'architecture. La discussion d'Alation sur les modèles d'architecture de pipelines de données et l'observabilité établit une distinction importante : la validation de la qualité a sa place au point d'entrée, et pas seulement après le traitement. Si vous attendez les vérifications de la destination, la dérive silencieuse, les modifications de schéma et les valeurs manquantes se sont déjà propagées dans le flux.
La pression du marché rencontre la réalité opérationnelle. Le marché des outils de pipelines de données est estimé à 14,76 milliards de dollars avec un TCAC de 26,8 %, et la même source précise que les pipelines modernes peuvent traiter plus de 800 millions d'enregistrements par jour. À cette échelle, une couche d'observabilité suivant des indicateurs tels que les enregistrements traités par seconde et les taux d'erreur par étape n'est pas un luxe. C'est du contrôle opérationnel élémentaire.
Pourquoi la détection apprise surpasse les règles rigides
Les vérifications basées sur des règles restent importantes, notamment pour les contraintes métier explicites. Mais elles montrent leurs limites lorsque le problème est comportemental plutôt que binaire.
La détection des anomalies convient mieux à cette tâche car elle peut apprendre les modèles attendus et signaler les valeurs aberrantes sans nécessiter une maintenance manuelle constante des seuils. FirstEigen présente la détection d'anomalies basée sur l'IA dans les flux de données comme un processus consistant à établir des profils de référence pour des données de haute qualité, puis à faire remonter les écarts suspects pour examen. L'aperçu d'Oracle sur les méthodes statistiques et neuronales pour la détection d'anomalies apporte un complément d'information utile : la classification, les méthodes basées sur la densité comme LOF, et les auto-encodeurs aident à détecter des anomalies locales et subtiles que les tests plus simples manquent.
Pour les équipes gérant des pipelines riches en documents, le même principe s'applique au niveau des champs. Ce guide sur la validation des données pour les factures et bons de commande rappelle opportunément que la validation ne concerne pas uniquement les schémas. Elle consiste également à appliquer des règles au niveau de l'enregistrement avant que les mauvaises valeurs ne se propagent dans la logique en aval.
Une mauvaise donnée interceptée lors de l'ingestion est un incident évité. Une mauvaise donnée découverte sur un tableau de bord est un problème de confiance.
Ce qu'il faut instrumenter dès le premier jour
Une conception d'observabilité native doit surveiller au moins quatre dimensions :
La ponctualité suit le moment où les données sont attendues et observe les décalages de livraison.
Le volume détecte les chutes soudaines, les pics ou les changements de distribution inhabituels.
Le schéma signale les ajouts et suppressions de colonnes ainsi que les changements de types avant que les transformations ne plantent de manière invisible.
La validation applique des règles métier au niveau de l'enregistrement là où l'exactitude doit être explicite.
Si le pipeline traite des données séquentielles ou événementielles, les schémas temporels méritent une attention particulière. L'explication de Nile Secure sur le prétraitement des données et la détection d'anomalies temporelles met en évidence le rôle du prétraitement, de la création de caractéristiques (feature engineering) et des modèles adaptés aux comportements séquentiels comme les LSTM. Cela se justifie parce que de nombreux « échecs de pipeline » sont en réalité des échecs de ponctualité : les données arrivent, mais pas au moment où l'entreprise en a besoin.
Voici un modèle mental utile : la surveillance vous indique qu'une tâche s'est exécutée. L'observabilité vous indique si les données sont restées fiables pendant cette exécution. Pour une comparaison concrète de ces rôles, ce comparatif entre l'observabilité des données et la qualité des données est à garder sous la main lors de la conception de la couche de contrôle.
Une liste de contrôle pratique pour votre prochain pipeline
La façon la plus rapide d'améliorer l'examen d'un pipeline est d'arrêter de se demander si le système fonctionne, mais plutôt de chercher à savoir dans quelles conditions il cesse d'être fiable.

Utilisez cette liste de contrôle avant de valider une nouvelle conception ou d'auditer un système existant :
Définir les contrats sources très tôt. Connaissez-vous la structure, la propriété, la fréquence de mise à jour et les modes de défaillance de chaque source ?
Choisir le modèle de traitement selon la fenêtre de décision. Ce cas d'usage relève-t-il du batch, du streaming ou d'une approche hybride en fonction de la rapidité requise pour agir sur ces données ?
Séparer les couches brutes, transformées et distribuées. Pouvez-vous rejouer l'ingestion sans reconstruire la logique métier de zéro ?
Concevoir des modules, pas des monstres. Une équipe peut-elle modifier un composant sans exposer des consommateurs non concernés ?
Cartographier le lignage automatiquement. Si un schéma change aujourd'hui, pouvez-vous identifier rapidement les tables, tableaux de bord et modèles impactés ?
Prévoir l'exécution parallèle. Le débit restera-t-il stable lorsque les sources se multiplieront ou que les fenêtres de rafraîchissement se chevaucheront ?
Définir des attentes de ponctualité. Existe-t-il un SLA clair ou une attente de fonctionnement indiquant quand les données doivent arriver et quand le retard se transforme en incident ?
Intégrer la validation et l'observabilité dès la première version. La fraîcheur, le volume, le schéma et les contrôles au niveau des enregistrements font-ils partie intégrante de l'architecture plutôt que d'être de simples ajouts successifs ?
Conserver les données sensibles locales par défaut. Votre conception limite-t-elle les copies et restreint-elle les accès lors des phases de surveillance et de transformation ?
Documenter les transferts. Un nouveau chef d'équipe peut-il facilement comprendre ce qui entre, ce qui change, ce qui est stocké et qui consomme ces données ?
Un bon pipeline n'est pas le plus complexe. C'est celui que votre équipe peut modifier en toute sécurité, surveiller clairement et auquel elle peut faire confiance sous la pression.
Si votre équipe souhaite bénéficier de ces contrôles sans déplacer les données de production hors de votre environnement, digna mérite un examen attentif. Elle associe la qualité des données et l'observabilité sur une seule plateforme, s'exécute au sein de clouds privés contrôlés par les clients ou d'environnements sur site, et aide les équipes à intercepter les anomalies, les changements de formats, les problèmes de ponctualité et les échecs de validation des enregistrements avant qu'ils ne se transforment en rapports obsolètes ou en défaillances des systèmes en aval.



