Maîtriser la modélisation des données d'entrepôt : Concepts et mise en production
|
0
minute de lecture

Vos tableaux de bord se chargent, mais personne ne leur fait confiance. La finance affirme que le chiffre d'affaires est erroné. Les opérations constatent des enregistrements manquants. Les analystes passent plus de temps à expliquer pourquoi une métrique a évolué qu'à décider quoi faire. C'est généralement le moment où les équipes se rendent compte que le warehouse n'échoue pas à cause de la syntaxe SQL ou des outils de BI. Il échoue parce que le modèle sous-jacent au warehouse n'est jamais devenu un système durable.
Une bonne modélisation des données de l'entrepôt transforme des données opérationnelles éparpillées en quelque chose que les utilisateurs peuvent interroger, comprendre et croire. Elle détermine également à quel point les changements futurs seront douloureux. Un modèle qui semble propre sur un schéma peut malgré tout s'effondrer sous l'effet de données qui arrivent tardivement, de définitions floues, de jointures lentes et de dérives de schéma. Un modèle qui fonctionne en production doit résister à toutes ces pressions en même temps.
Table des matières
Pourquoi la modélisation des données de l'entrepôt est le fondement de vos analyses
Maintenir la santé de votre modèle de données grâce à l'Observability
Pourquoi la modélisation des données de l'entrepôt est le fondement de vos analyses
Lorsqu'une équipe dit « nos données sont désordonnées », le problème sous-jacent est généralement structurel. Les tables reflètent le comportement des applications plutôt que le sens métier. Les indicateurs sont calculés de trois manières différentes. Les modifications historiques sont écrasées, de sorte que personne ne peut savoir à quoi ressemblait un client, un produit ou un contrat à un moment antérieur.
C'est là que la modélisation des données d'entrepôt prend toute son importance. Elle offre aux analystes un langage stable pour l'activité de l'entreprise. Au lieu d'assembler des commandes brutes, des dossiers clients, des factures et des journaux d'état chaque fois que quelqu'un a besoin d'un rapport, l'entrepôt fournit des entités durables, des jointures cohérentes et des définitions acceptées par tous.

La confiance se brise avant les pipelines
Un pipeline peut se terminer avec succès et produire tout de même de mauvaises analyses. Les données peuvent arriver à temps, mais le modèle peut toujours masquer des doublons, aplatir incorrectement des relations ou effacer l'historique dont les utilisateurs en aval ont besoin pour les analyses de tendances et le travail d'audit.
La conséquence pratique est simple. Les mauvais modèles créent des disputes. Les bons modèles créent des décisions.
Règle pratique : si un utilisateur métier a besoin qu'un ingénieur de données lui explique chaque jointure de tableau de bord, c'est que le modèle est encore trop proche des systèmes sources.
Un modèle d'entrepôt solide remplit trois rôles simultanément :
Crée de la cohérence : les définitions des clients, des produits et des revenus cessent de changer d'un tableau de bord à l'autre.
Prend en charge l'analyse historique : les équipes peuvent répondre non seulement à ce qui est vrai aujourd'hui, mais aussi à ce qui était vrai à un moment précis.
Améliore la maintenabilité : les ingénieurs peuvent ajouter de nouvelles sources et de nouvelles métriques sans avoir à réécrire toute la couche analytique.
La modélisation est une discipline ancienne aux conséquences modernes
L'entrepôt de données n'est pas apparu avec les plateformes cloud. L'architecture qui le sous-tend remonte à plusieurs décennies. L'histoire de l'architecture des entrepôts de données fait remonter cette discipline aux années 1980, époque à laquelle l'approche principale a été développée pour transformer les données opérationnelles en systèmes d'aide à la décision. Ce changement a permis aux organisations de consolider les données provenant de domaines opérationnels distincts et de les rendre utiles à l'analyse.
Le passage d'un stockage orienté mainframe à des entrepôts hybrides et cloud a modifié les détails de mise en œuvre, mais n'a pas éliminé le besoin de modélisation. Il en a augmenté les enjeux. Les entrepôts modernes doivent absorber davantage de données, plus de changements et un plus grand nombre d'utilisateurs, tout en préservant le contexte historique.
C'est pourquoi les équipes qui se précipitent directement sur l'intégration et les tableaux de bord se retrouvent souvent bloquées. Charger des données n'est pas la même chose que les organiser. Un entrepôt ne devient utile que lorsque le modèle correspond à la façon dont l'entreprise formule ses questions.
Choisir son modèle : Star, Snowflake ou Data Vault
La façon la plus simple d'expliquer les styles de modélisation est de les comparer à la conception d'une bibliothèque. Une bibliothèque est aménagée pour une recherche rapide. Une autre est organisée pour un classement précis. Une troisième est construite comme des archives, où la préservation de la traçabilité importe tout autant que la récupération des données.
Les modèles d'entrepôt font les mêmes compromis.
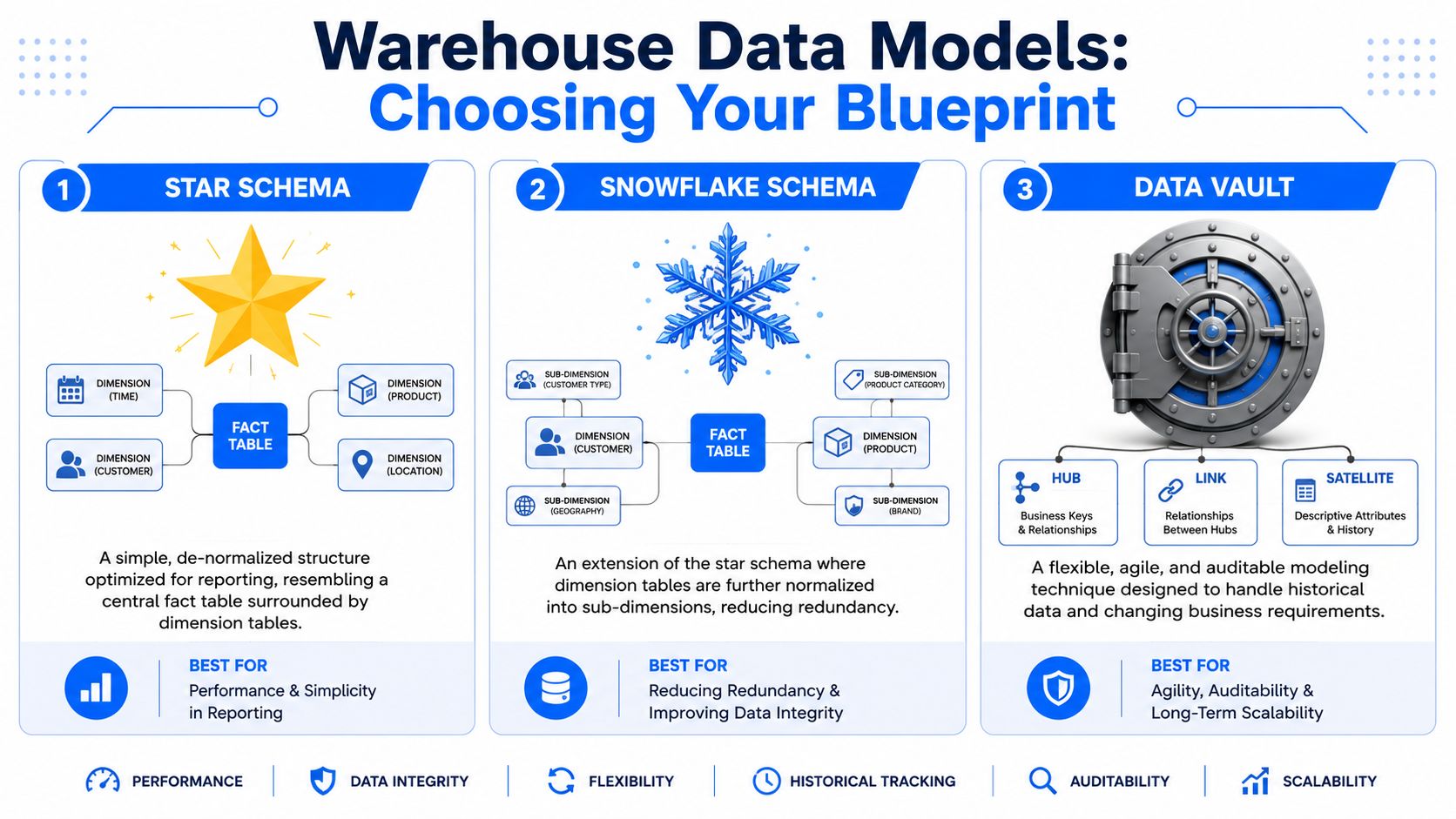
Penser le modèle comme une bibliothèque
Le schéma en étoile (Star Schema) correspond à la bibliothèque facile à consulter. Une table de faits centrale contient des événements mesurables tels que des commandes, des sinistres, des pages vues ou des factures. Les tables de dimensions fournissent le contexte comme le client, le produit, la région et la date. C'est un modèle facile à enseigner, facile à interroger, et généralement le bon choix lorsque la BI constitue la charge de travail principale.
Un schéma en flocon (Snowflake Schema) part de la même idée dimensionnelle mais normalise certaines dimensions en sous-dimensions. La dimension Produit peut ainsi être divisée en tables de marque, de catégorie et de fournisseur. La géographie peut être scindée en ville, région et pays. Vous réduisez la redondance, mais vous augmentez la complexité des jointures.
Un Data Vault se rapproche davantage d'un système d'archivage. Il sépare les clés métiers stables, les relations et l'historique descriptif en structures distinctes. Selon la présentation des modèles de modélisation d'entrepôt par ER/Studio, le schéma en étoile domine pour les exigences de simplicité et de rapidité, tandis que le Data Vault est inégalé pour les entreprises confrontées à des environnements en évolution rapide et à des exigences réglementaires strictes. Cette même source décrit le Data Vault comme une structure composée de hubs pour les entités métiers clés, de links pour les relations et de satellites pour les attributs descriptifs et l'historique des modifications.
Pour les équipes qui conçoivent leurs options de manière visuelle, une référence de diagramme d'architecture de données peut aider à clarifier la façon dont ces modèles diffèrent une fois que l'on passe du tableau blanc à la mise en œuvre.
Ce que chaque structure optimise
Voici ce qui fonctionne généralement en pratique.
Le schéma en étoile fonctionne mieux lorsque les analystes ont besoin de rapports rapides et prévisibles et que l'entreprise peut s'aligner sur des faits et des dimensions clairs.
Le schéma en flocon fonctionne mieux lorsque la réutilisation des dimensions et une normalisation plus poussée importent plus que la simplicité pour l'analyste.
Le Data Vault fonctionne mieux lorsque les systèmes sources changent fréquemment, que la traçabilité est importante et que la conservation de l'historique brut est essentielle.
Les modèles 3NF sont les plus adaptés lorsque vous avez besoin d'une fidélité opérationnelle dans une couche d'intégration centrale, mais ils nécessitent généralement une autre couche de présentation avant que la plupart des analystes puissent les utiliser confortablement.
Le piège consiste à choisir par idéologie. Beaucoup d'équipes choisissent Data Vault parce que cela sonne comme une solution d'entreprise, pour s'apercevoir ensuite qu'elles ont toujours besoin de datamarts dimensionnels pour le reporting. D'autres aplatissent tout en étoiles trop tôt et le regrettent lorsque les systèmes en amont changent chaque trimestre.
L'étoile pour l'utilisabilité. Le flocon pour une normalisation plus stricte. Le Data Vault pour l'adaptabilité et l'auditabilité.
Une architecture pratique mélange souvent les modèles. Les couches brutes et centrales peuvent préserver la fidélité de la source et l'historique des modifications. Les datamarts destinés aux analystes peuvent quant à eux présenter un schéma en étoile, car c'est ce que les outils de BI et les analystes utilisent le plus facilement.
Plus loin dans cette section, il est utile de voir ces compromis en action :
Comparaison des approches de modélisation des données
Critère | Schéma en étoile | Schéma en flocon | Data Vault |
|---|---|---|---|
Performance des requêtes | Généralement forte pour les requêtes BI car les jointures sont simples | Peut être plus lent à parcourir car les dimensions sont plus normalisées | Fort pour la traçabilité et les modèles d'intégration, mais n'est pas généralement la forme de reporting final |
Facilité d'utilisation pour l'analyste | Élevée. Les utilisateurs métiers peuvent le comprendre rapidement | Modérée. Plus de jointures et de sauts de table | Plus faible pour les utilisateurs en libre-service, à moins de construire des datamarts par-dessus |
Efficacité du stockage | Plus faible que les conceptions plus normalisées | Meilleure que l'étoile pour certaines dimensions car la redondance est réduite | Variable, souvent avec plus de tables et plus d'enregistrements historiques |
Flexibilité face au changement | Modérée | Modérée | Élevée |
Suivi historique | Bon lorsqu'il est modélisé de manière délibérée | Bon lorsqu'il est modélisé de manière délibérée | Excellent par conception |
Gouvernance et auditabilité | Bonne, dépend de la discipline | Bonne | Forte |
Complexité de mise en œuvre | Plus faible | Moyenne | Élevée |
La décision doit découler de votre charge de travail, et non de la mode. Si les dirigeants ont besoin chaque matin de tableaux de bord de KPI de confiance, commencez par la forme qui facilite ces requêtes. Si ce sont les régulateurs, les auditeurs ou des programmes nécessitant de fortes intégrations qui guident la conception, optimisez d'abord la traçabilité et le contrôle du changement.
Principes de conception d'un entrepôt haute performance
Un modèle d'entrepôt peut utiliser différents schémas et échouer pour les mêmes raisons. Les points d'échec communs sont presque toujours d'ordre stratégique. Mauvaise granularité. Conception centrée sur la source. Noms peu clairs. Aucun plan de croissance. Aucune appropriation des définitions.

Commencer par les processus métiers, pas par les systèmes sources
L'entrepôt doit modéliser l'activité de l'organisation : commandes, expéditions, réclamations, paiements, sessions d'application, tickets de support. Si la conception commence par les tables qui proviennent par hasard de Salesforce, de SAP ou d'une base de données produit, vous héritez des particularités des applications plutôt que de la logique métier.
J'ai trouvé une règle particulièrement fiable : définir d'abord l'événement métier, puis décider de la manière dont l'entrepôt va le représenter. Cela permet de maintenir les tables de faits ancrées dans quelque chose de mesurable et de répétable.
Un entrepôt dure plus longtemps lorsque ses entités clés survivent à une migration de système.
Concevoir pour les lecteurs, la croissance et le contrôle
Les analystes et les développeurs BI sont des lecteurs du modèle. Les ingénieurs de données sont les garants de sa maintenance. Les équipes de governance sont les responsables des risques pour ce modèle. Une bonne conception respecte ces trois acteurs.
Utilisez ceci comme liste de contrôle essentielle :
La clarté plutôt que l'ingéniosité : préférez des noms de tables et de colonnes qu'un nouvel analyste peut comprendre sans avoir à ouvrir cinq fichiers de transformation.
Granularité stable : chaque table de faits a besoin d'une définition explicite au niveau de la ligne. Si vous ne pouvez pas énoncer la granularité en une phrase, c'est que la table n'est pas prête.
Évolutivité dès le premier jour : partez du principe que le volume, la simultanéité et les nouveaux sujets vont croître. Adapter l'échelle a posteriori coûte cher.
Sensibilité aux performances : l'élégance logique ne suffit pas. Si les requêtes courantes nécessitent des analyses et des jointures excessives, les utilisateurs exporteront les données vers des feuilles de calcul et contourneront l'entrepôt.
Gouvernance intégrée : les règles d'accès, la traçabilité, les contrôles de qualité et la définition de la propriété ne peuvent pas être remis à plus tard.
Le recrutement joue également un rôle important. Les équipes disposent souvent de bons ingénieurs de pipelines de données, mais manquent de profils capables de faire le lien entre la modélisation, les contraintes de plate-forme et la sémantique de l'entreprise. Si vous construisez ou retravaillez un programme d'entrepôt de données, un partenaire spécialisé dans le recrutement d'architectes de données cloud peut s'avérer utile, car les erreurs d'architecture n'apparaissent généralement que bien après la décision d'embauche.
Le modèle doit également laisser de la place pour une conception par couches. Les couches brute, de staging, centrale, analytique et d'agrégation résolvent chacune un problème différent. L'erreur consiste à les fusionner en une seule parce que cela semble plus rapide. C'est plus rapide au début. C'est plus lent chaque mois qui suit.
Des questions métiers aux schémas d'entrepôt
Les meilleurs modèles logiques commencent par des conversations parfois complexes. Les parties prenantes demandent souvent « un tableau de bord des ventes » ou une « vision client à 360° » alors qu'elles ont en réalité besoin d'orienter précisément un petit nombre de décisions spécifiques. Votre rôle est d'imposer de la précision avant de concevoir la moindre table de faits.

Transformer les questions en granularité
Prenons une question métier telle que : « Quel a été notre chiffre d'affaires mensuel par produit et par région ? »
Cette question contient déjà les indices de la structure :
Le processus métier correspond aux ventes ou à la facturation.
La mesure est le chiffre d'affaires.
La perspective temporelle est mensuelle.
Les dimensions d'analyse sont le produit et la région.
Mais le modèle ne doit pas sauter directement sur une table mensuelle. La première tâche consiste à définir la granularité utile la plus fine. Est-ce qu'une ligne représente une ligne de commande, une ligne de facture, une expédition ou un enregistrement résumé quotidien ? Dans la plupart des entrepôts, le choix de l'événement métier élémentaire le plus fiable permet de ne fermer aucune porte aux analyses futures.
Une séquence pratique ressemble à ceci :
Mener des entretiens axés sur les décisions, pas sur les tableaux de bord : demandez quelle action découle de l'indicateur. Si personne n'agit en fonction de celui-ci, ne le modélisez pas en priorité.
Lister les processus clés : les ventes, les retours, les abonnements, les réclamations, les tickets ou les événements de capteurs deviennent généralement des domaines de faits distincts.
Déclarer la granularité tôt : « Une ligne par ligne de facture » est clair. « Une ligne par résumé des transactions du client » ne l'est généralement pas.
Nommer les dimensions à partir du langage métier : client, produit, région, canal, commercial et date sont plus faciles à gouverner que des étiquettes propres à un système source.
Résoudre la sémantique de l'indicateur avant la construction : le chiffre d'affaires, le client actif et le taux d'attrition (churn) sont réputés pour sembler simples tout en masquant des choix de gestion différents.
Note de terrain : la plupart des travaux de refonte ont lieu parce que les équipes ont sauté la définition de la granularité et ont découvert plus tard qu'une même table mélangeait des événements, des instantanés (snapshots) et des résumés dérivés.
Un guide de planification de l'intégration de votre entrepôt de données dédié est utile à cette étape car l'intégration des sources influence des choix de conception clés tels que les clés métiers, les enregistrements arrivant en retard et la mise en correspondance des systèmes.
Passer des entités aux schémas exploitables
Une fois les questions clarifiées, cartographiez d'abord les concepts dans un modèle conceptuel. Gardez-le axé sur le métier. Le client achète un produit. La commande appartient à une région. La facture fait référence à un contrat. La réflexion sur les entités-associations facilite ce processus, même si l'entrepôt final n'est pas conçu selon un modèle relationnel pur.
Vient ensuite le modèle logique. C'est à ce stade que vous définissez les clés, les attributs et les relations avec suffisamment de précision pour que l'équipe d'ingénierie puisse les implémenter. Les faits reçoivent des clés étrangères vers les dimensions. Les dimensions reçoivent des identifiants stables et des attributs descriptifs. Les dimensions partagées sont harmonisées afin qu'un même client ou produit signifie la même chose dans tous les datamarts.
Une bonne séance de relecture à ce stade pose des questions telles que :
Question de relecture | Pourquoi cela importe |
|---|---|
Que représente une ligne dans cette table ? | Évite les confusions de granularité mixte |
Quel processus métier représente-t-elle ? | Garde les modèles ancrés dans la réalité |
Quelles dimensions sont réutilisées ailleurs ? | Favorise la conformité et la cohérence |
Quel historique doit être conservé ? | Évite les écrasements de données destructeurs |
Quels indicateurs appartiennent à l'amont plutôt qu'à la BI ? | Réduit la duplication de logique |
Le modèle physique viendra plus tard. Mais si le modèle logique est vague, l'optimisation physique ne pourra pas le sauver.
Mise en œuvre physique et optimisation des performances
Une conception logique peut être parfaitement sensée et pourtant afficher de mauvaises performances face à des requêtes réelles. À ce stade, la modélisation des données d'entrepôt cesse d'être conceptuelle pour devenir purement technique.
Les modèles logiques ne garantissent pas des requêtes rapides
La couche physique est cruciale car les moteurs n'exécutent pas des schémas. Ils exécutent des structures de stockage, des modèles de regroupement (clustering), des règles de découpage de partitions (partition pruning) et des stratégies de matérialisation. Les conseils de modélisation physique basés sur des moteurs spécifiques rendent cela très concret : partitionner une table de faits par date peut réduire le coût de scan de 60 à 80 % pour les requêtes filtrant les enregistrements récents, et le regroupement sur des clés de dimension à forte cardinalité peut améliorer l'efficacité des jointures jusqu'à 45 % dans les implémentations en étoile.
Cela modifie votre approche de la mise en œuvre. Une table de faits dotée d'un filtre order_date dans presque tous les tableaux de bord doit généralement être organisée physiquement pour exploiter ce schéma d'accès. Un schéma en étoile qui effectue constamment des jointures sur customer_id ou une autre clé de dimension sélective doit refléter cela dans son clustering ou sa configuration équivalente selon le moteur utilisé.
Les priorités pratiques d'optimisation sont généralement :
Partitionner sur les filtres temporels courants : si les utilisateurs interrogent constamment les périodes récentes, le partitionnement par date est souvent le premier gain.
Créer des clusters autour des jointures sélectives : les clés à forte cardinalité peuvent améliorer la colocalisation pour les jointures répétées.
Matérialiser de façon réfléchie : toutes les transformations ne doivent pas nécessairement rester sous forme de vues. Une forte réutilisation et des jointures coûteuses justifient souvent la matérialisation en tables.
Séparer les couches de consultation de l'ingestion brute : les tables brutes préservent la fidélité de l'information. Les tables de reporting doivent servir la structure d'analyse finale.
Pour les équipes qui évaluent des choix d'optimisation spécifiques à une plate-forme, ce guide pour optimiser votre entrepôt de données pour une efficacité maximale avec les outils modernes de qualité des données constitue un complément utile aux travaux de conception logique.
Gérer l'historique de manière délibérée
Le suivi historique est l'un des premiers domaines où les raccourcis de conception finissent par coûter cher. Si un client change de région, de segment ou de niveau de tarification, vous devez savoir si les rapports doivent refléter la valeur actuelle ou la valeur au moment de l'événement.
Dans les modèles dimensionnels, les Type 2 Slowly Changing Dimensions (SCD Type 2) restent le mécanisme standard pour préserver l'historique. L'idée de base est simple : clore l'ancienne ligne de dimension, en insérer une nouvelle et utiliser des dates d'effet ou des fenêtres de validité pour que les faits s'associent à la bonne version historique.
Un modèle simple ressemble à ceci :
Cette méthode n'a rien de spectaculaire, mais elle protège l'analyse des tendances, le reporting temporel précis et l'auditabilité. Les équipes qui écrasent leurs dimensions par souci de simplicité finissent généralement par devoir reconstruire cette logique historique plus tard, sous la pression des délais.
Maintenir la santé de votre modèle de données grâce à l'Observability
Un modèle d'entrepôt ne reste pas digne de confiance simplement parce que sa conception d'origine était solide. Il se dégrade au fil des changements opérationnels normaux. Une équipe source ajoute une colonne. Un traitement d'ingestion arrive en retard. Un champ commence à dériver subtilement. Une jointure fonctionne toujours, mais la signification métier s'est modifiée.

Un modèle d'entrepôt se dégrade en silence
C'est pourquoi l'observabilité doit faire partie intégrante du cycle de vie de la modélisation des données d'entrepôt, et non être une réflexion après-coup. Le modèle que vous avez conçu n'est utile que s'il reste structurellement stable, à jour et sémantiquement crédible en production.
Le risque opérationnel est plus grand que ce que de nombreuses équipes imaginent. L'impact documenté des problèmes de qualité des données sur les systèmes d'IA montre que les problèmes de qualité des données causent en moyenne 15 à 30 % des défaillances des modèles d'IA, la dérive silencieuse des données et les modifications de schéma en étant les principaux facteurs. Ces mêmes types de défaillances affectent les modèles d'entrepôt bien avant de se manifester sous forme d'incident sur un système d'IA. Les tableaux de bord se cassent. Les comparaisons historiques sont faussées. Les tâches en aval réussissent techniquement tout en échouant sur le plan analytique.
Un entrepôt sain n'est pas celui qui possède le plus beau schéma. C'est celui qui vous avertit rapidement lorsque la réalité ne correspond plus au modèle.
Ce qu'il faut surveiller après la mise en service
Une fois le modèle en production, quatre catégories de surveillance importent plus que toutes les autres.
Stabilité du schéma : surveillez l'ajout ou la suppression de colonnes, les changements de types et les champs renommés qui peuvent invalider des transformations ou altérer le sens des données.
Actualisation (Timeliness) : sachez quand les chargements attendus sont en retard, manquants ou incomplets pour éviter que des tableaux de bord obsolètes soient pris pour la réalité.
Comportement des métriques : surveillez les variations inhabituelles de volumes, de taux de valeurs nulles, de distributions et de modèles de relations que les vérifications classiques de pipelines ne détectent pas.
Respect des règles (Compliance) : appliquez les contraintes métiers au niveau de l'enregistrement là où les exigences de gouvernance ou d'audit imposent de la précision.
Les plateformes d'observabilité modernes prouvent ici leur valeur. Selon la description certifiée de la plateforme, digna combine la détection des anomalies assistée par IA, la surveillance des délais de mise à disposition, la validation au niveau de l'enregistrement et le suivi des modifications de schéma, tout en exécutant ses analyses à l'intérieur d'environnements contrôlés par le client. Son architecture est conçue pour une exécution en base de données, un déploiement sur cloud privé ou sur site, garantissant l'absence de transfert de données vers l'éditeur.
Cela change la donne sur le plan opérationnel car l'observabilité doit se trouver au plus près de l'entrepôt, plutôt que de dépendre de l'exportation de données sensibles vers un énième outil externe. Cela modifie également la gestion des incidents. Au lieu de découvrir les problèmes après qu'un directeur financier ait remis en cause un tableau de bord, les développeurs peuvent intercepter les anomalies structurelles et comportementales bien en amont.
Le point fondamental est d'ordre architectural. Un modèle d'entrepôt est un actif vivant. Si vous ne surveillez pas si les hypothèses qui le sous-tendent restent valides, vous ne disposez pas réellement d'un entrepôt gouverné. Vous avez simplement un diagramme et un peu de chance.
Modéliser pour aujourd'hui et pour demain
La modélisation des données d'entrepôt ne se limite jamais au choix d'un modèle de schéma théorique. Il s'agit d'aligner les questions métiers, la structure logique, les performances physiques et la confiance opérationnelle au sein d'un système capable de résister aux changements.
Le véritable livrable est la confiance
Les équipes qui réussissent ne recherchent pas une pureté académique. Elles font des compromis réfléchis. Elles choisissent le modèle Star lorsque les analystes ont besoin de rapidité et de clarté. Elles adoptent des structures centrales plus flexibles lorsque la volatilité des sources et la traçabilité l'emportent. Elles définissent la granularité en amont, préservent délibérément l'historique et optimisent la couche physique pour les requêtes effectivement exécutées.
Tout aussi important, elles traitent leur entrepôt comme un actif nécessitant une attention constante. Les modèles dérivent. Les définitions s'élargissent. Les plateformes évoluent. Une conception qui fonctionnait l'an dernier peut toujours s'avérer logiquement correcte mais opérationnellement fragile.
C'est pourquoi les programmes d'entrepôts de données les plus solides raisonnent sur l'ensemble du cycle de vie. Choisir le bon modèle. Concevoir pour la lisibilité et l'évolutivité. Implémenter selon la réalité des charges de travail. Surveiller le modèle après son passage en production. Lorsque ces étapes restent connectées, l'entrepôt devient une source de vérité durable au lieu d'un projet de nettoyage permanent.
Si vous cherchez un moyen pratique de protéger l'entrepôt que vous avez déjà construit, digna aide les équipes à surveiller directement les changements de schéma, les anomalies de données, les délais de livraison et la validation au sein d'environnements contrôlés par le client, afin que les anomalies de données fassent surface avant qu'elles n'endommagent les tableaux de bord, les analyses ou les modèles en aval.



