Niezawodne potoki Data Science: buduj, wdrażaj, monitoruj
|
6
min. czyt.

Prawdopodobnie masz teraz do czynienia z jedną z dwóch sytuacji. Albo model produkcyjny zaczął zachowywać się dziwnie i nikt nie potrafi określić, czy problem leży po stronie logiki cech, danych źródłowych, czy opóźnionego ładowania na wcześniejszym etapie. Albo Twój zespół posiada potok, który „działa” przez większość dni, ale każde wydanie wydaje się ryzykowne, ponieważ jedna zmiana schematu, jedna brakująca partycja lub jeden uszkodzony plik może skazić wyniki na dalszych etapach.
Tak właśnie wyglądają potoki data science w środowisku produkcyjnym. Trudną częścią zazwyczaj nie jest trenowanie modelu. Jest nią utrzymanie wiarygodnego przepływu danych na etapach pozyskiwania, transformacji, tworzenia cech, wdrażania i ciągłego monitorowania. Zespoły, które skupiają się wyłącznie na orkiestracji, przekonują się o tym na własnej skórze. Zielony DAG nie gwarantuje poprawności danych, a pomyślne uruchomienie zadania nie gwarantuje użytecznych danych wejściowych dla modelu.
Spis treści
h2 id="63">Why Data Science Pipelines Are the Backbone of Modern AI
Wiele niepowodzeń AI nie zaczyna się od złego modelowania. Zaczynają się od potoku, który dostarczył niekompletne cechy, zduplikowane rekordy, nieaktualne agregaty lub błędnie oznaczone dane treningowe. Model jest obwiniany, ponieważ jest widoczny. Potok unika kontroli, ponieważ jest ukryty pod harmonogramami, skryptami, konektorami i zadaniami w hurtowni danych.
Dlatego traktuję potoki data science jako infrastrukturę, a nie spoiwo projektu. Zasilają one eksperymenty, zadania treningowe, scoring wsadowy, funkcje wnioskowania online, pulpity nawigacyjne i pętle ponownego trenowania. Kiedy dochodzi do dryfu w ich działaniu, cierpi na tym każdy kolejny etap przetwarzania.

Sygnał biznesowy jest jasny. Według raportu Fortune Business Insights na temat rynku potoków danych, globalny rynek potoków danych jest wyceniany na 10,01 mld USD w 2024 r. i prognozuje się, że osiągnie 43,61 mld USD do 2032 r., przy średniorocznej stopie wzrostu (CAGR) na poziomie 19,9%, a 90% projektów AI i uczenia maszynowego bezpośrednio zależy od tych potoków. Zespoły nie inwestują w infrastrukturę potoków danych dlatego, że jest to modne. Robią to, ponieważ systemy AI nie przetrwają bez silnych fundamentów danych.
Co psuje się w rzeczywistych środowiskach
Oczywiste awarie są łatwe do zauważenia. Zadanie ulega awarii. Plik nie zostaje zapisany. Wygasa limit czasu połączenia konektora.
Niebezpieczne awarie są bardziej ciche:
Dryf aktualności, gdy codzienne dane zaczynają docierać coraz później
Dryf semantyczny, gdy pole nadal istnieje, ale zmieniło się jego znaczenie na wcześniejszym etapie
Dryf dystrybucji, gdy wartości mieszczą się w ograniczeniach typu, ale wykraczają poza normalne zachowanie
Częściowy sukces, gdy potok zapisuje dane wyjściowe, ale tylko dla części oczekiwanego zakresu
Zasada praktyczna: Jeśli jedynym sygnałem o stanie systemu jest sukces zadania, to nie monitorujesz potoku. Monitorujesz harmonogram zadań.
Niezawodne potoki data science muszą każdego dnia odpowiadać na dwa pytania: Czy zadania się uruchomiły? Oraz czy wyprodukowały dane, które nadal nadają się do trenowania, scoringu i podejmowania decyzji?
Unpacking the Data Science Pipeline Concept
Najprostszym modelem mentalnym jest linia fabryczna. Surowce napływają od różnych dostawców. Na każdej stacji ktoś czyści, zmienia kształt, sprawdza, wzbogaca lub montuje dany element. Na koniec nie chcesz otrzymać sterty części. Chcesz gotowego produktu, któremu możesz zaufać.
Potok data science działa w ten sam sposób. Pobiera surowe dane z aplikacji, logów, plików, interfejsów API, strumieni zdarzeń i tabel hurtowni. Następnie przekształca te dane w zestawy treningowe, cechy, prognozy i monitorowane wyniki, z których mogą korzystać inne systemy.
Więcej niż ETL
Podstawowe zadanie ETL przenosi i przekształca dane. To ważne, ale to tylko część układanki. Potoki data science zazwyczaj dodają kroki, których standardowe potoki analityczne w pełni nie obejmują:
Tworzenie cech pod kątem danych wejściowych gotowych do użycia w modelach
Generowanie zbiorów danych treningowych i walidacyjnych
Powtarzalność eksperymentów
Pakowanie i wdrażanie modeli
Pętle sprzężenia zwrotnego po wdrożeniu
Ta różnica ma znaczenie operacyjne. Uszkodzony raport BI jest bolesny. Uszkodzony potok wejściowy modelu może wpływać na rankingi, kontrole oszustw, prognozowanie, kwalifikację lub procesy weryfikacji klinicznej, w zależności od dziedziny.
Skrypt a potok produkcyjny
Projekty data science często zaczynają się od notebooka lub skryptu w języku Python. To normalne. To również miejsce, w którym zaczyna się wiele problemów z niezawodnością.
Jednorazowy skrypt może być dobry do eksploracji. Jest jednak słabym systemem produkcyjnym, ponieważ często zależy od lokalnych założeń:
Scenariusz | Co się dzieje |
|---|---|
Proces pracy w notebooku | Ścieżki, poświadczenia, wersje pakietów i opcje próbkowania istnieją w środowisku jednej osoby |
Potok produkcyjny | Dane wejściowe, wyjściowe, zależności, ponowne próby, testy, pochodzenie danych i własność są jasno zdefiniowane |
Potoki data science klasy produkcyjnej wymagają powtarzalności. Jeśli te same dane wejściowe nadejdą jutro, system powinien uruchomić tę samą logikę z kontrolowanymi zmianami, znanymi zależnościami i obserwowalnymi wynikami. Zazwyczaj oznacza to współpracę takich narzędzi jak Airflow, Dagster, Prefect, Spark, dbt, natywny SQL w hurtowni, potoki CI i infrastruktura serwowania modeli, zamiast jednego zintegrowanego stosu technologicznego.
Potok nie jest dojrzały tylko dlatego, że jest zautomatyzowany. Jest dojrzały wtedy, gdy inny inżynier może go bezpiecznie zmienić i stwierdzić, czy dane wyjściowe są nadal godne zaufania.
To jest standard, do którego warto dążyć.
Siedem głównych etapów potoku data science
Większość systemów produkcyjnych wygląda na skomplikowane w szczegółach, ale ich cykl życia jest spójny. Jeśli zespoły dzielą wspólne słownictwo dotyczące etapów, debugowanie staje się łatwiejsze, a odpowiedzialność bardziej przejrzysta.
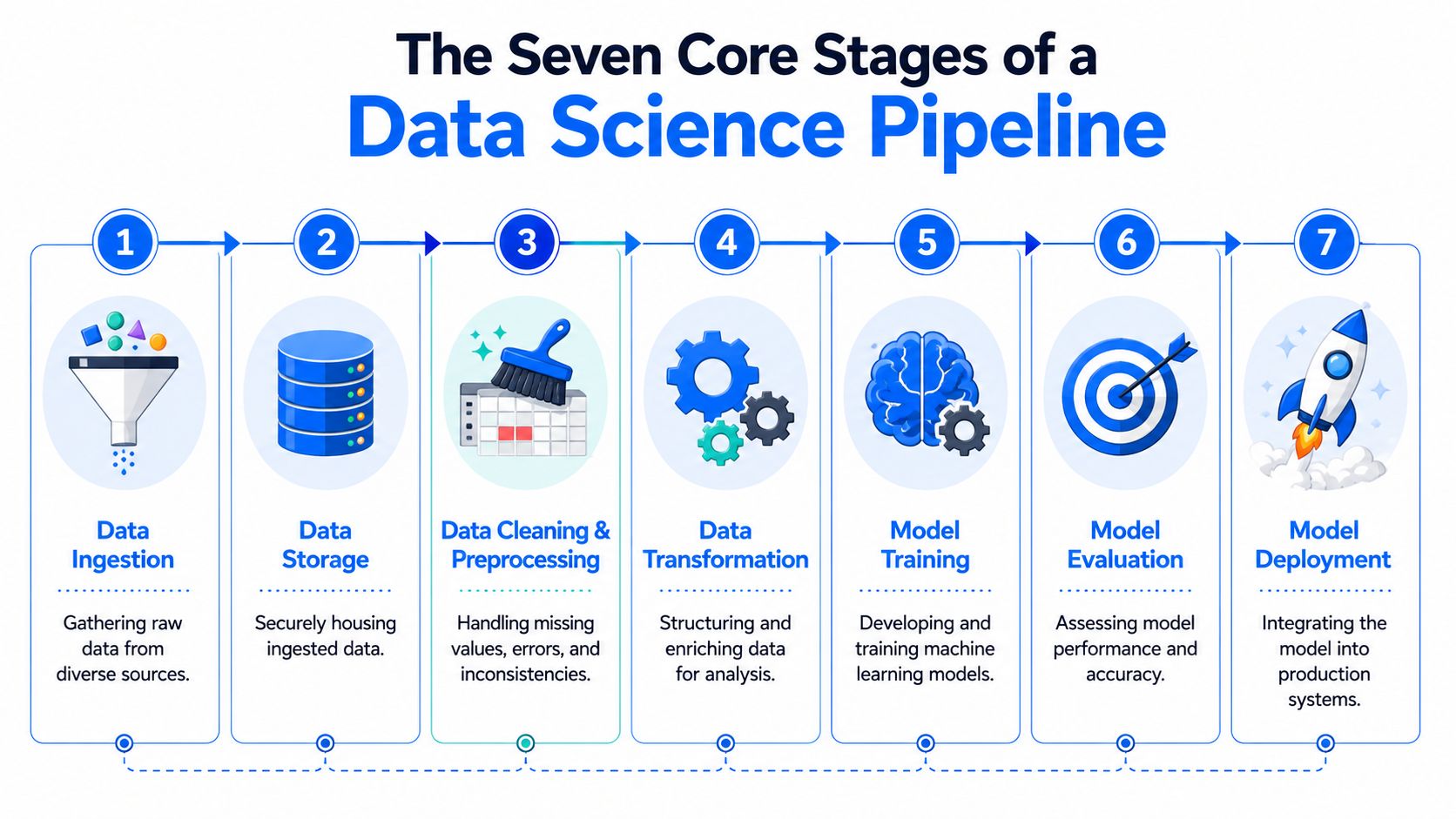
Pozyskiwanie danych
Potok zderza się z rzeczywistością w momencie, gdy napływają dane. Dane pochodzą z baz danych OLTP, narzędzi SaaS, strumieni CDC, magazynów obiektowych, logów aplikacji i interfejsów API. Niektóre źródła są ustrukturyzowane i stabilne. Inne nie.
Główną decyzją na tym etapie jest wybór przetwarzania wsadowego (batch), strumieniowego lub obu na raz. Przetwarzanie wsadowe jest prostsze do przeanalizowania i łatwiejsze w przypadku ponownego zasilania (backfill). Przetwarzanie strumieniowe obsługuje przypadki użycia o niskim opóźnieniu, ale podnosi poprzeczkę w kwestii kolejności, deduplikacji, opóźnionych zdarzeń i obsługi punktów kontrolnych (checkpoints).
Do typowych narzędzi należą Kafka, Pub/Sub, Kinesis, Airbyte, Fivetran, niestandardowe konektory oraz bezpośrednie zadania pozyskiwania danych do hurtowni.
Przechowywanie i integracja danych
Gdy dane już trafią do systemu, potrzebują trwałego miejsca i kształtu, na którym mogą polegać odbiorcy na dalszych etapach. Zespoły dokonują wtedy wyboru między ETL a ELT, definiują warstwy surowe w porównaniu do wyselekcjonowanych oraz decydują, jak duża część transformacji powinna odbywać się w zadaniach Spark, a jak duża w modelach SQL.
Ten etap zazwyczaj generuje:
Surowe strefy lądowania danych (landing zones) do celów odtwarzania i audytu
Ujednolicone zbiory danych do współdzielonego użytku
Zintegrowane dane wejściowe cech z różnych obszarów, takich jak dane klientów, produktów, roszczeń lub urządzeń
Dobra warstwa integracji zachowuje wystarczająco dużo surowych szczegółów do ponownego przetworzenia, dając jednocześnie użytkownikom na dalszych etapach stabilne interfejsy.
Przed przejściem do kolejnych etapów warto wdrożyć jedno praktyczne zabezpieczenie. Solidne praktyki walidacji danych w potokach produkcyjnych zapobiegają przedostawaniu się oczywistych błędów na dalsze etapy przetwarzania.
Przetwarzanie danych i inżynieria cech
Wiele potoków staje się specyficznych dla danej dziedziny, w miarę jak zespoły radzą sobie z brakującymi wartościami, kodują kategorie, budują cechy opóźnione (lagged features), agregują zdarzenia w oknach czasowych, obliczają wskaźniki i łączą dane o zachowaniach z danymi referencyjnymi.
Logika cech często zaczyna się w notebookach, a następnie jest utrwalaną w transformacjach SQL, Spark lub Python. Model awarii jest przewidywalny: logika zostaje skopiowana między ścieżkami treningowymi i wnioskowania, a następnie zaczyna się rozchodzić. Rozwiązanie również jest przewidywalne: scentralizowanie definicji cech i wersjonowanie ich.
Kilka wzorców sprawdza się wyjątkowo dobrze:
Oddziel surowe oczyszczanie od logiki biznesowej
Trzymaj definicje cech blisko testów
Projektuj transformacje tak, aby były idempotentne
Zapisuj wersję danych użytą do każdego uruchomienia treningowego
Oto wbudowany przewodnik po całym cyklu życia:
Trenowanie i dostrajanie modeli
Trenowanie konsumuje przetworzone zbiory danych i przekształca je w modele kandydackie. Mechanika różni się w zależności od stosu technologicznego. Niektóre zespoły używają scikit-learn na wyciągach z hurtowni danych. Inne korzystają ze Spark ML, XGBoost, PyTorch, TensorFlow lub zarządzanych platform ML.
Kwestia operacyjna to nie tylko dostrajanie hiperparametrów. To przede wszystkim powtarzalność. Jeśli model w przyszłym miesiącu osiągnie gorsze wyniki, musisz wiedzieć, która wersja kodu, który zestaw cech, jaki wycinek danych treningowych i jakie parametry go wygenerowały.
Walidacja i wybór modelu
Ten etap decyduje o tym, co zyskuje prawo do przejścia dalej. Zespoły porównują modele kandydackie z wydzielonymi zestawami danych testowych (holdout data), ograniczeniami biznesowymi, wymogami dotyczącymi wyjaśnialności oraz limitami operacyjnymi, takimi jak opóźnienie wnioskowania lub zużycie pamięci.
Walidacja powinna obejmować więcej niż tylko metryki modelu. Powinna również odpowiadać na pytanie, czy leżące u podstaw dane wciąż reprezentują docelowy proces. Model o wysokiej ocenie, ale przeszkolony na niestabilnych danych wejściowych, może nadal zawieść na produkcji.
Najlepszym kandydatem na model jest ten, który Twoja platforma może bezpiecznie obsłużyć, a nie tylko ten z najlepszym wynikiem offline.
Wdrożenie modelu
Wdrożenie zmienia artefakt w usługę lub zaplanowany proces scoringowy. Typowe wzorce obejmują scoring wsadowy do tabeli w hurtowni danych, wnioskowanie w czasie rzeczywistym za interfejsem API oraz konfiguracje hybrydowe, w których usługa działająca w czasie rzeczywistym odwołuje się do wstępnie obliczonych cech.
Ten etap wymaga jasnych kontraktów:
Kwestia wdrożeniowa | Co należy zdefiniować |
|---|---|
Dane wejściowe | Wymagane pola, typy, obsługę wartości null oraz oczekiwania dotyczące aktualności |
Dane wyjściowe | Schemat predykcji, pola poziomu ufności i lokalizację zapisu |
Przywracanie wersji (Rollback) | Poprzednią wersję modelu, warunki wyzwalające oraz ścieżkę przywracania |
Monitorowanie i ponowne trenowanie
Potok nie kończy się na wdrożeniu. Monitorowanie produkcji musi obejmować stan działania usługi, aktualność cech, stabilność schematu, jakość danych oraz wyzwalacze ponownego trenowania.
Ponowne trenowanie powinno odbywać się z konkretnego powodu, a nie dlatego, że tak nakazuje harmonogram cron. W dojrzałych systemach decyzje o ponownym trenowaniu są powiązane z zaobserwowanym dryfem danych, zmieniającym się kontekstem biznesowym lub informacją zwrotną o działaniu modelu. W przeciwnym razie zespoły automatyzują jedynie zbędną pracę.
Integrating Pipelines with Data Warehouses and Lakes
Potoki data science zazwyczaj nie powstają w izolacji. Są budowane na bazie tabel hurtowni danych, pamięci jezior danych lub kombinacji obu tych rozwiązań. Wybór architektury wpływa na opóźnienia, governance, szybkość eksperymentowania oraz ilość powielanej logiki, którą musisz utrzymywać.

Wzorce typu „najpierw hurtownia”
Hurtownie danych sprawdzają się najlepiej, gdy dane wejściowe są już w miarę ustrukturyzowane, a biznes potrzebuje kontrolowanych, łatwych do odpytania zbiorów danych. Snowflake, BigQuery, Redshift i podobne systemy to świetny wybór, gdy inżynieria analityczna i generowanie cech ML muszą korzystać z tych samych wyselekcjonowanych tabel.
W tym wzorcu hurtownia zazwyczaj staje się źródłem prawdy dla:
Ustandaryzowanych encji, takich jak klient, konto, dostawca czy sprzedawca
Wyselekcjonowanych cech używanych wielokrotnie przez różne zespoły
Wyników modeli zapisywanych z powrotem na potrzeby analiz BI i raportowania operacyjnego
Konfiguracja oparta w pierwszej kolejności na hurtowni ułatwia realizację governance. Kontrakty schematów, transformacje oparte na SQL, kontrola dostępu i audytowalność są zazwyczaj bardziej przejrzyste niż w doraźnych systemach opartych na plikach. Dobrze współgra to również z zespołami planującymi strategię migracji z hurtowni do jeziora danych dla mieszanych obciążeń.
Wzorce typu „najpierw jezioro danych”
Jeziora danych (data lakes) są lepsze, gdy zespoły potrzebują elastyczności w zakresie surowych plików, danych półstrukturyzowanych, logów, dokumentów lub dużych eksperymentalnych zbiorów danych. Pozwalają one badaczom danych (data scientists) badać szczegóły na poziomie źródłowym bez konieczności zbyt wczesnego wtłaczania każdego sygnału w sztywny schemat hurtowni.
Sprawdza się to dobrze w takich przypadkach użycia, jak:
Generowanie cech bogatych w zdarzenia
Rozwój modeli na surowych danych telemetrycznych
Potoki danych tekstowych, obrazów lub dokumentów
Ponowne przetwarzanie danych historycznych po zmianach w logice cech
Ceną za to jest dyscyplina operacyjna. Jeziora danych dają swobodę, ale ułatwiają też gromadzenie niespójnych formatów, duplikowanie zasobów i zacieranie granic odpowiedzialności za dane.
Co sprawdza się w środowiskach mieszanych
Większość przedsiębiorstw kończy z modelem hybrydowym. Surowe dane o wysokim wolumenie lądują w jeziorze danych. Wyselekcjonowane, kontrolowane i skierowane do biznesu wyniki końcowe żyją w hurtowni. Potok danych porusza się między obydwoma tymi środowiskami.
Praktyczny podział często wygląda tak:
Warstwa | Najlepsze zastosowanie |
|---|---|
Jezioro danych (Lake) | Surowe pozyskiwanie danych, odtwarzanie, eksperymentowanie i przetwarzanie pośrednie na dużą skalę |
Hurtownia (Warehouse) | Zweryfikowane wymiary, wyselekcjonowane fakty, funkcje wielokrotnego użytku i raportowanie na dalszych etapach. |
Logika potoku | Przepływ danych, transformacja, walidacja i serwowanie danych pomiędzy dwoma środowiskami |
Zachowaj swobodę eksperymentalną na wcześniejszych etapach (upstream). Utrzymuj zaufane zużycie biznesowe na dalszych etapach (downstream).
Taki podział pozwala uniknąć powszechnego błędu. Zespoły albo zbyt wcześnie wymuszają przeniesienie wszystkiego do hurtowni, co spowalnia eksperymentowanie, albo pozostawiają zbyt wiele w jeziorze danych, co sprawia, że analityka końcowa i Compliance stają się trudniejsze niż powinny.
Beyond Orchestration Data Quality and Observability
Harmonogram zadań może Ci powiedzieć, czy zadania się uruchomiły. Nie powie Ci jednak, czy rekordy miały sens, czy krytyczne pole nie spłaszczyło się do niemal stałych wartości, ani czy producenci danych na wcześniejszym etapie nie zmienili znaczenia biznesowego przy zachowaniu tego samego schematu.
Dlatego sama orkiestracja nie wystarczy.

Jak wyglądają ciche awarie
Obciążenie operacyjne jest większe, niż przyznaje wiele zespołów. Potoki danych borykają się z ciągłą niestabilnością – od 30% do 40% z nich ulega awarii każdego tygodnia. Awarie te przekładają się średnio na 67 incydentów z danymi miesięcznie w organizacji, a rozwiązanie każdego z nich zajmuje około 15 godzin, według zestawienia statystyk inżynierii danych Folio3.
Te liczby opisują jedynie widoczne incydenty. W praktyce niektóre z najkosztowniejszych awarii wcale nie są twardymi błędami. Są to ciche przesunięcia jakości:
Źródło zaczyna wysyłać puste ciągi znaków zamiast wartości null
Typ wyliczeniowy (enum) zyskuje nową kategorię, którą logika na dalszym etapie ignoruje
Znacznik czasu (timestamp) dociera w innej strefie czasowej
Dystrybucja cechy zmienia się na tyle powoli, że reguły progowe tego nie wychwytują
Gdy dzieje się to w systemach ML, model może nadal serwować prognozy, podczas gdy zaufanie do danych wyjściowych systematycznie spada.
Cztery sygnały, które mają znaczenie
Zespoły potrzebują jednego widoku operacyjnego, łączącego jakość i obserwowalność, zamiast rozdzielać je na niepowiązane narzędzia i pulpity nawigacyjne. Traktowałbym te cztery sygnały jako niezbędne.
Jakość danych
To poprawność na poziomie pojedynczego rekordu. Czy wymagane pola są wypełnione? Czy wartości spełniają reguły biznesowe? Czy klucze obce mapują się poprawnie? Czy obliczone pola są spójne wewnętrznie?
Najważniejsze są jednoznaczne walidacje. Testy jakości powinny znajdować się blisko danych, które chronią, a nie tylko w kodzie aplikacji lub notebookach na końcowych etapach.
Terminowość
Świeże dane, które docierają zbyt późno, nadal stanowią problem produkcyjny. Monitorowanie terminowości powinno śledzić oczekiwane wzorce przybywania danych, opóźnione partycje, niekompletne ładowania i spóźnione aktualizacje ze źródeł.
W środowiskach wsadowych oznacza to zazwyczaj kontrole uwzględniające harmonogram. W przypadku potoków zdarzeń oznacza to obserwowanie opóźnień w pozyskiwaniu danych (ingestion lag) oraz zachowań niezgodnych z kolejnością.
Integralność schematu
Błąd schematu jest oczywisty, gdy znika kolumna i zadanie ulega awarii. Trudniejszym przypadkiem jest zmiana polegająca na dodaniu elementów lub modyfikacji typów, która nie powoduje natychmiastowego błędu, ale zmienia znaczenie danych. Zespoły powinny uważać na dodane lub usunięte kolumny, modyfikacje typów oraz dryf kontraktów na poziomie pól.
Wykrywanie anomalii
Reguły wyłapują znane problemy. Wykrywanie anomalii wychwytuje nieoczekiwane zmiany w wolumenie, dystrybucji, wzorcach i trendach zachowań. Potrzebujesz obu tych podejść.
Użyteczne porównanie wygląda następująco:
Typ sygnału | Dobrze wykrywa | Słabo wykrywa |
|---|---|---|
Reguły statyczne | Nagłe skoki wartości null, nieprawidłowe zakresy, naruszenia formatu | Nowe wzorce dryfu, których nie przewidziano |
Wykrywanie anomalii | Nieoczekiwane przesunięcia w zachowaniu i dystrybucji danych | Jawne błędy logiki biznesowej, o ile nie zostały zakodowane |
Dla zespołów porównujących te dwie dyscypliny bezpośrednio, ten przewodnik na temat data observability versus data quality w praktyce stanowi użyteczny punkt odniesienia, ponieważ traktuje je jako uzupełniające się mechanizmy kontrolne, a nie konkurujące ze sobą kategorie.
Dlaczego jednolite monitorowanie wygrywa z nadmiarem narzędzi
Rozproszone środowiska same generują incydenty. Jedno narzędzie obserwuje świeżość danych. Drugie sprawdza schemat. Trzecie uruchamia walidacje. Czwarte wysyła alerty. Inżynierowie spędzają potem czas przeznaczony na obsługę incydentu na uzgadnianiu sprzecznych sygnałów i szukaniu odpowiedzialnych za dany system osób.
O wiele lepiej sprawdza się ujednolicony model operacyjny:
Jedno miejsce do kontrolowania kondycji systemu na wszystkich etapach potoku
Jeden widok incydentu łączący świeżość danych, schemat, jakość i anomalie
Jedna struktura odpowiedzialności za eskalację i naprawę problemów
Jedna ścieżka audytu pokazująca, co i kiedy się zmieniło
Jeśli inżynier potrzebuje czterech różnych pulpitów nawigacyjnych, aby wyjaśnić jedną błędną prognozę, to projekt systemu monitorowania sam w sobie stanowi część problemu.
W środowiskach chmury prywatnej i lokalnej (on-prem) ta unifikacja ma jeszcze większe znaczenie, ponieważ zespoły często nie mogą polegać na w pełni zarządzanych, natywnych dla chmury usługach monitorowania. Potrzebują mechanizmów kontrolnych, które wpisują się w granice przedsiębiorstwa bez wymuszania dodatkowego transferu danych.
On-Prem and Private Cloud Pipeline Considerations
Środowiska lokalne (on-prem) i chmury prywatnej zmieniają priorytety projektowe. Typowe porady dotyczące chmury publicznej nie zawsze dobrze się sprawdzają, gdy dane nie mogą opuścić sieci, cykle zakupowe są wolniejsze, a audyty bezpieczeństwa – bardziej rygorystyczne.
To nie oznacza, że budowanie solidnych potoków data science jest z definicji trudniejsze. Oznacza to jedynie, że architektura musi od samego początku szanować lokalne ograniczenia.

Ograniczenia bezpieczeństwa i architektury
W sektorach regulowanych zespoły zazwyczaj chcą, aby obliczenia odbywały się tam, gdzie dane już się znajdują. Zmniejsza to ryzyko naruszenia bezpieczeństwa, pozwala uniknąć niepotrzebnego kopiowania i upraszcza procesy kontroli governance. W praktyce oznacza to często transformacje wewnątrz bazy danych, lokalne obliczanie metryk, walidację natywną dla hurtowni oraz kontrolowane granice usług wokół trenowania modeli lub wnioskowania.
Główne pytania architektoniczne są proste:
Czy ten komponent może działać bez eksportowania wrażliwych danych w inne miejsce
Czy zespoły ds. bezpieczeństwa mogą kontrolować, kto i czego dotykał
Czy zespoły platformowe mogą wdrażać poprawki i obsługiwać dane rozwiązanie za pomocą istniejących mechanizmów kontrolnych
Czy potok potrafi bezpiecznie zgłosić błąd (fail-safe), gdy jakaś zależność działa gorzej
Otwarte formaty, jasne kontrakty i minimalny ruch danych udowadniają tu swoją wartość.
Planowanie wydajności i całkowity koszt
Zespoły on-prem nie mogą rozwiązać każdego problemu z przepustowością poprzez kliknięcie „skaluj w górę”. Planowanie wydajności ma znaczenie na wcześniejszym etapie i musi opierać się na realistycznych obciążeniach. Wskazówki Google dotyczące benchamarkingu zadań Dataflow z przepustowością na rdzeń vCPU są tutaj przydatne, ponieważ kładą nacisk na testowanie z oczekiwanymi typami danych, rozmiarami, zachowaniem sieci oraz rzeczywistymi warunkami źródła i celu, zamiast na idealnych testach syntetycznych.
Ocena kosztów musi również uwzględniać zachowanie w przypadku awarii. Jak wyjaśnia Databricks w swoich wytycznych dotyczących oceny stosunku kosztów potoków do wydajności, zarówno całkowite koszty obliczeniowe, jak i wskaźniki awaryjności powinny być uwzględniane w kalkulacji, ponieważ częste awarie zadań wymuszają ponowne przetwarzanie danych i opóźniają czas uzyskania wartości.
What holds up in enterprise environments
Najważniejsze wzorce, jakie widziałem w środowiskach korporacyjnych, są w najlepszy możliwy sposób przewidywalne. Przedkładają one stabilność nad nowości.
Usługi modułowe: Dbaj o to, aby pozyskiwanie, transformacja, walidacja i serwowanie danych były ze sobą luźno powiązane, tak aby jedna awaria nie paraliżowała całego systemu.
Deterministyczne zasilanie wsteczne (backfills): Uruchamiaj ponownie logikę dla określonego przedziału czasu przy użyciu tego samego kodu i z jasną historią pochodzenia danych.
Lokalna obserwowalność: Przechowuj sygnały o stanie systemu tam, gdzie inżynierowie mogą je kontrolować bez naruszania granic bezpieczeństwa.
Jasna odpowiedzialność: Każdy potok, tabela i dane wejściowe modelu muszą mieć przypisany zespół odpowiedzialny za obsługę incydentów.
Niezawodność w skali przedsiębiorstwa wynika zazwyczaj ze zdyscyplinowanego wyznaczania granic, a nie z efektownych diagramów architektury.
Systemy w chmurze prywatnej i środowiskach lokalnych (on-prem) premiują projekty, które są łatwe do kontrolowania, przetestowane pod kątem wydajności i ostrożne w kwestii przesyłania danych. Jest to szczególnie ważne, gdy potoki AI zależą od współdzielonej infrastruktury hurtowni i jezior danych, z której korzysta wiele zespołów jednocześnie.
Conclusion Building Your Resilient Pipeline Strategy
Niezawodne potoki data science to nie tylko harmonogramy zadań. To systemy operacyjne określające, w jaki sposób surowe dane stają się wiarygodnymi zbiorami treningowymi, cechami produkcyjnymi, wynikami modeli i decyzjami biznesowymi.
Faza budowy przyciąga najwięcej uwagi. Faza utrzymania decyduje o tym, czy potok nadal dostarcza wartość. To właśnie tutaj wiele zespołów ponosi porażkę. Automatyzują one przepływ, ale nie zaufanie. Monitorują zadania, ale nie kondycję danych. Dodają nowe narzędzia, ale nie przejrzystość.
Lepsza strategia jest prostsza do opisania niż do wdrożenia. Buduj jasne etapy. Dbaj o to, aby decyzje dotyczące przechowywania i serwowania danych były dostosowane do rzeczywistych obciążeń. Traktuj jakość danych, terminowość, integralność schematu oraz wykrywanie anomalii jako jedną dyscyplinę operacyjną. W środowiskach prywatnych trzymaj procesy obliczeniowe blisko danych i przeprowadzaj testy wydajnościowe w realistycznych warunkach.
Najlepszym kolejnym krokiem zazwyczaj nie jest uruchomienie nowego projektu platformowego. Jest nim audyt najbardziej krytycznego z punktu widzenia biznesu potoku, który już posiadasz. Sprawdź, gdzie może ulec awarii, nie wywołując alarmu. Sprawdź, jak szybko Twój zespół potrafi wyjaśnić błędne dane wyjściowe. Sprawdź, czy obserwowalność i jakość nie są wciąż rozproszone w zbyt wielu miejscach.
Jeśli szukasz praktycznego sposobu na ujednolicenie wykrywania anomalii, walidacji na poziomie rekordów, monitorowania terminowości i śledzenia schematów bez przenoszenia danych poza swoje środowisko, zapoznaj się z digna. Zostało ono stworzone dla zespołów wdrażających rozwiązania z zakresu Modern Data Quality i Observability bezpośrednio we własnych bazach danych, chmurze prywatnej lub infrastrukturze lokalnej (on-prem).




Poznaj zespół tworzący platformę
Zespół z Wiednia, składający się z ekspertów od AI, danych i oprogramowania, wspierany rygorem akademickim i doświadczeniem korporacyjnym.