Data Lake vs Data Mart: Make the Right Choice for 2026
|
0
min. czyt.

Your leadership team wants faster dashboards, cleaner KPIs, and room for AI and machine learning. At the same time, your data team is dealing with raw logs, SaaS extracts, operational databases, and file drops that don't arrive on schedule. That's where the data lake vs data mart decision usually gets framed in an oversimplified way.
In practice, this isn't just a storage choice. It's a trust choice. A data lake gives you flexibility and scale. A data mart gives business teams consistency and speed. The hard part is what happens between them. If you don't control quality, lineage, and change detection, the lake becomes a liability and the mart becomes a polished layer of bad assumptions.
For most organizations planning a next-gen data platform, the key question isn't which one is universally better. It's which role each should play, and how you'll keep the path from raw data to business-ready data reliable.
Table of Contents
What Is a Data Lake and What Is a Data Mart
A data lake is a central repository for raw data in many forms. It can hold structured tables, semi-structured event data, application logs, documents, and other source data before a team has fully decided how that data will be modeled or queried. The operating idea is flexibility. You land data first, then shape it later when a business or analytical use case becomes clear.
A data mart is different. It's a curated, purpose-built data layer for a specific domain such as finance, sales, operations, or customer support. Data is cleaned, standardized, tested, and organized before business users consume it. The operating idea is usability. People shouldn't have to reverse-engineer raw source systems just to answer a reporting question.

The easiest mental model
Think of the data lake as a reservoir. It stores large volumes of incoming data in its original state. That makes it valuable when the business wants to preserve detail, support data science work, or keep options open for future analysis.
Think of the data mart as a bottling plant. It takes selected water from the reservoir, filters it, checks quality, packages it, and delivers it for a known purpose. That makes it valuable when finance needs a controlled revenue definition or operations needs a reliable service-level dashboard.
Practical rule: If users need freedom to explore unknown questions, start closer to a lake. If they need repeatable answers for a known process, start closer to a mart.
Why the distinction matters to leadership
Leaders often hear that lakes are modern and marts are old-fashioned, or that marts are rigid and lakes are cheap. Neither framing is useful. What matters is the business job each serves.
A lake supports breadth. It's where engineering teams preserve source fidelity, onboard new data sources quickly, and support exploratory analytics. A mart supports precision. It's where governance teams define business logic, align metrics, and reduce decision friction.
If you're also evaluating managed relational services as part of the broader platform, this RDS guide for Philippine businesses is a useful reference for understanding where operational databases fit alongside analytical layers. Transaction systems, raw analytical storage, and curated analytical models each solve different problems.
Where teams get into trouble
The common failure mode in the data lake vs data mart discussion is assuming the lake is just staging and the mart is just reporting. That misses the operating burden in the middle. Raw flexibility creates downstream cleanup work. Curated accessibility creates upstream modeling discipline.
Teams that want a middle path often look at a lakehouse approach and ways to maintain data quality, especially when they want to reduce duplication between raw storage and analytical serving layers. Even then, the same architectural truth holds. Raw data and trusted business data shouldn't be treated as if they have the same quality standard.
Architectural Deep Dive A Side-by-Side Comparison
The cleanest way to compare data lake vs data mart is to look at how each behaves under real operational pressure.
Characteristic | Data Lake | Data Mart |
|---|---|---|
Data structure | Raw, mixed-format, often minimally transformed | Structured, cleaned, business-ready |
Schema approach | Schema-on-read | Schema-on-write |
Primary purpose | Preserve detail and support flexible exploration | Deliver consistent analytics for a defined business function |
Typical users | Data engineers, data scientists, ML teams | Analysts, finance teams, BI users, business stakeholders |
Processing style | Often ELT-oriented | Often ETL-oriented before consumption |
Query pattern | Exploratory, batch-heavy, varied workloads | Repetitive, high-value reporting and dashboard access |
Governance posture | Often lighter at ingestion, stronger later if maturity exists | Stronger upfront because outputs are meant for business decisions |
Change tolerance | Higher tolerance for source variation | Lower tolerance because reports must remain stable |
Performance expectation | Good for large-scale storage and experimentation | Better suited to fast, focused analytical consumption |
Cost profile | Storage-efficient, but operational complexity can grow | More transformation and modeling effort, but clearer business value at consumption time |
Flexibility versus control
A lake wins when the organization doesn't yet know every future question it wants to ask. Product telemetry, clickstream events, logs, documents, and source extracts can all land without forcing immediate modeling decisions. That's useful when your roadmap includes experimentation, feature engineering, or broad retention of source history.
A mart wins when the organization does know the question. Monthly close, margin reporting, pipeline reviews, claims analysis, and regulatory dashboards all depend on stable definitions. Users expect a trusted number, not a starting point for interpretation.
A lake stores possibility. A mart delivers commitment.
The hidden architectural trade-off
Many leadership teams compare only storage format and user type. The fundamental trade-off is operating model.
A lake shifts effort downstream. Engineers can ingest quickly, but someone still has to reconcile identifiers, handle missing values, standardize dates, define business rules, and resolve source conflicts. If that discipline never arrives, the lake accumulates data without producing trustworthy outputs.
A mart shifts effort upstream. Teams must agree on definitions before data is widely consumed. That can feel slower, but it reduces recurring confusion. The cost isn't just technical work. It's organizational alignment.
What works and what doesn't
A few patterns consistently work:
Use the lake for landing and preservation: Keep source fidelity where raw detail matters.
Use the mart for decision-grade data: Put governed KPIs and curated dimensions where business teams operate.
Separate ingestion speed from consumption trust: Fast onboarding and reliable reporting shouldn't be forced into the same layer.
Other patterns usually fail:
Letting every team query the lake directly: That often produces inconsistent metrics and duplicated logic.
Building isolated marts from operational systems: It's fast at first, then expensive to maintain.
Treating raw data as business-ready because it's available: Availability isn't the same as quality.
The leadership view
If you're funding a platform, don't ask only where data will live. Ask where metric definitions will live, who owns source conformity, and how breakages will be detected before executives see them. That's where the lake-versus-mart decision becomes a platform strategy rather than a tooling debate.
Matching the Architecture to the Use Case
The right architecture becomes obvious when you look at the work people need to do.
When a data lake is the right fit
A product and ML team usually needs raw behavioral detail. They want session logs, event payloads, support interactions, device signals, and model training inputs without heavy filtering at ingest. They may revisit old data with a new hypothesis, or combine sources that weren't originally designed to answer the same question.
That's a data lake use case. The team needs room to explore, join, enrich, and reprocess. Forcing all of that into a tightly curated mart too early strips away detail and creates constant remodelling work.
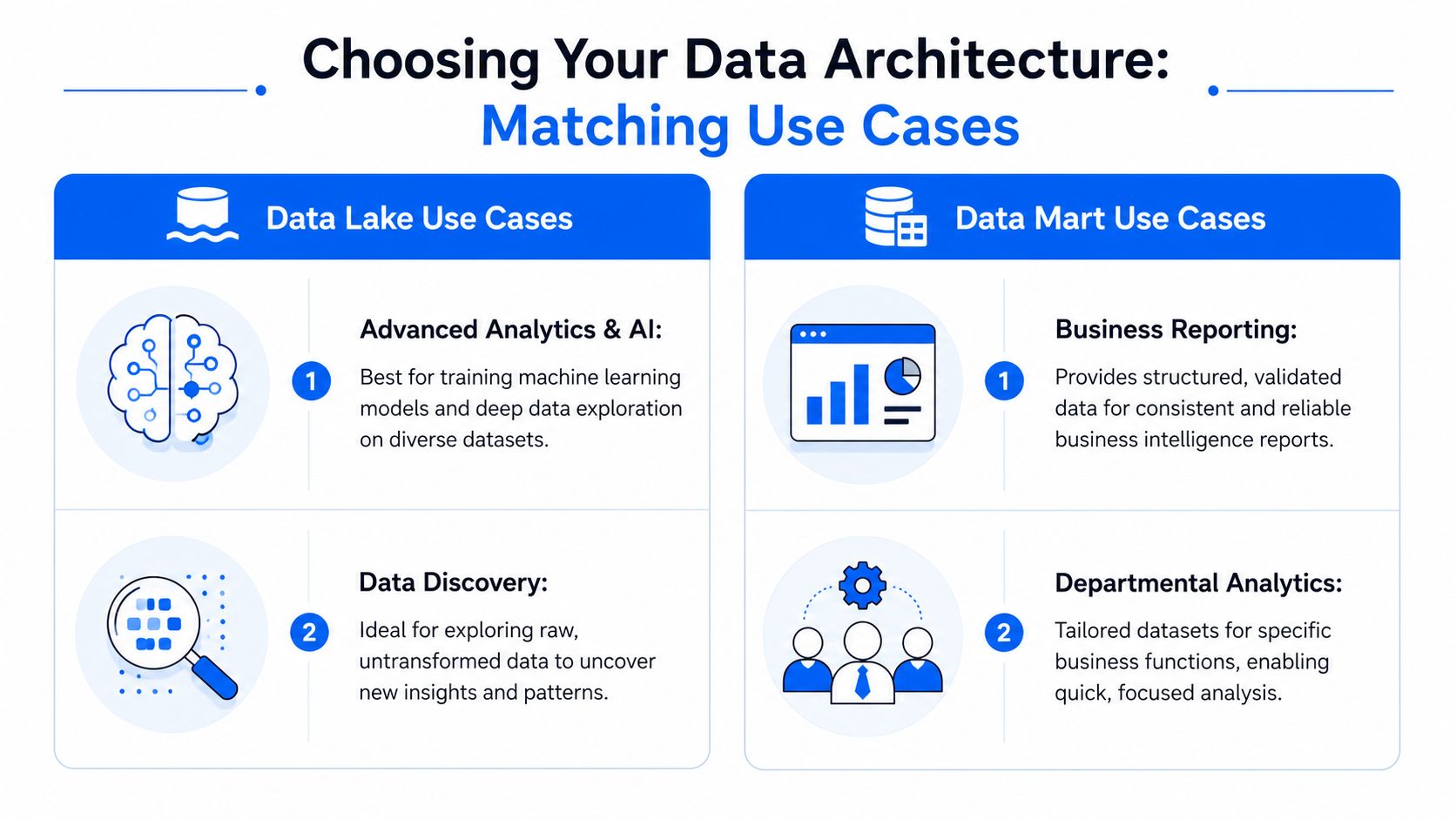
When a data mart is the better answer
A finance team has almost the opposite need. It doesn't want every raw transaction state, every intermediate event, or multiple possible revenue interpretations. It wants one governed set of definitions for bookings, recognized revenue, cost allocation, and period-close reporting.
That's a data mart use case. The mart narrows the scope on purpose. It removes ambiguity so that quarterly reporting doesn't turn into an argument about source-system semantics.
Two practical examples
Consider these common patterns:
Data science workflow: Engineers land application events, API outputs, and historical snapshots in a lake. Data scientists build features from raw sequences and adjust transformations as model requirements change.
Departmental BI workflow: Analytics engineers publish a finance mart with conformed dimensions, approved measures, and tested joins so controllers and executives can use the same numbers.
Neither pattern is more modern than the other. They're solving different business problems.
If the job is discovery, optimize for access to raw context. If the job is accountability, optimize for consistency.
What leadership should standardize
The strongest platforms don't force one architecture everywhere. They standardize decision criteria:
Consumer type: Is this dataset for engineers and scientists, or for business operators?
Tolerance for ambiguity: Can users interpret raw signals, or do they need approved definitions?
Frequency of change: Will the transformation logic evolve often, or should it remain stable for governance?
Consequence of error: Is this exploratory analysis, or a number used for budget, compliance, or external reporting?
Those questions usually settle the data lake vs data mart debate faster than a long tool comparison ever will.
The Critical Path from Lake to Mart Governance and Quality
The dangerous assumption in many architectures is that moving data from a lake into a mart is a routine pipeline task. It isn't. It's where raw, inconsistent, source-shaped information gets turned into business truth. That conversion introduces validation, normalization, matching, deduplication, enrichment, and policy decisions that many teams underestimate.

Why the handoff breaks
Raw data rarely arrives in a mart-ready state. Source systems encode statuses differently. Keys don't line up cleanly. Optional fields become mandatory downstream. Timestamps drift. Files arrive late. A schema change in one source can subtly invalidate transformation logic several steps later.
That's why governance can't be bolted on after launch. Validation rules, ownership, lineage, and acceptance criteria need to be built into the path from the start.
A practical guide to data contracts and implementation is useful here because contracts force teams to define what upstream systems are expected to deliver before downstream marts depend on them.
The quality failure that leadership should care about
A 2024 healthcare study found that up to 40% of data lake exports fail business rule validation before reaching data marts when automated quality checks are absent, leading to pipeline breaks and stale reporting, as described in this healthcare data quality study. That's the operational reality many architecture diagrams leave out.
The business implication is direct. If your mart is the layer executives trust, then the lake-to-mart path is not just engineering plumbing. It's a control point.
Operating advice: Don't approve a new mart without agreeing on validation ownership, exception handling, and rollback rules.
What strong teams put in place
Teams that manage this transition well usually formalize a few controls:
Entry criteria for source data: Define what must be present before a dataset can move forward.
Transformation checkpoints: Test joins, null handling, code mappings, and business-rule conformance during processing.
Release discipline: Version transformation logic and document metric-definition changes before publishing them.
Escalation paths: Make sure failed checks trigger action, not just logs.
A short explainer on the pipeline mindset is useful before tooling discussions:
Hidden cost is usually operational, not storage
Leaders often budget for storage and underestimate the cost of remediation. The expensive part isn't keeping raw data in a lake. It's the recurring effort required when poor-quality data slips downstream and teams scramble to reconcile broken reports, rerun jobs, and explain conflicting numbers.
That's why data lake vs data mart decisions should include governance design as a first-order concern. If the path between them is weak, the platform will look complete on paper and unreliable in practice.
Ensuring Trust with Data Observability
Most data incidents don't begin where users notice them. They surface in the mart because that's where people look, but the underlying issue often starts upstream in the lake or in ingestion flows feeding it.
Why monitoring the mart alone isn't enough
A dashboard can break because a source file arrived late, a column type changed, a load partially completed, or a previously stable distribution drifted enough to break a downstream assumption. If you only monitor the final table or the dashboard query, you're discovering the problem after the business has already been exposed to it.
Recent 2024 research indicates that 65% of data quality incidents in data marts originate from unmonitored issues in upstream data lakes, including schema modifications and delayed loads, according to this research on upstream causes of downstream data quality incidents.

What observability needs to watch
In a modern platform, observability should cover at least these failure modes:
Timeliness issues: Detect delayed or missing arrivals before reporting windows are affected.
Schema drift: Catch added, removed, or retyped fields before transformation jobs break unexpectedly.
Data anomalies: Flag unexpected distribution changes, volume shifts, or unusual values that may indicate source problems.
Validation gaps: Confirm that records still meet the rules required by downstream business processes.
Data observability integrates into architecture, not just operations. If your lake is flexible by design, then your monitoring has to be disciplined by design.
One practical tooling pattern
Teams typically combine orchestration alerts, transformation tests, metadata lineage, and observability tooling. One example is data observability vs data quality explained, which is useful for clarifying that observing pipeline behavior and validating business rules are related but not identical activities.
In that category, digna is one option for monitoring anomalies, timeliness, schema changes, and record-level validation across lakes, warehouses, and pipelines while executing analysis inside the customer environment. That matters in regulated settings where teams need operational visibility without broad data movement.
A reliable mart depends on a monitored lake. Trust downstream starts upstream.
What changes once observability is in place
The biggest shift is organizational. Data teams stop relying on business users to discover issues first. Engineers see delayed arrivals before the CFO sees a stale dashboard. Analysts get context on whether a metric changed because the business changed or because the data changed. Governance teams gain a clearer audit trail for why a published dataset was or wasn't fit for use.
That's the missing layer in many data lake vs data mart conversations. Architecture choices matter, but trust comes from how actively you watch the path between them.
The Decision Framework Which Do You Need
The wrong way to answer data lake vs data mart is with a blanket preference. The right way is to ask a short set of business and operating questions.
The checklist leaders should use
Do you need to retain raw, multi-format data for future analysis? If yes, you likely need a lake component.
Do your users need governed metrics for recurring business decisions? If yes, you need one or more marts.
Are your primary consumers data scientists and engineers? Favor raw access and flexible processing.
Are your primary consumers analysts, controllers, or executives? Favor curated models and stable semantics.
Can your team support quality controls between layers? If not, don't assume a lake will simplify the platform.
Is metric consistency more important than source completeness for this use case? If yes, publish through a mart, not directly from raw storage.

The answer is often both
In mature platforms, the choice is usually and, not or. The lake becomes the landing and exploration layer. The mart becomes the consumption layer for defined business domains. The strategic work is deciding where quality gates sit, who owns transformations, and how issues are detected before they affect reporting.
If leadership wants one principle to carry forward, use this one: store broadly, publish narrowly, and monitor the path in between. That approach gives the business room to evolve without sacrificing trust in the numbers people use to run the company.
If your team is building a platform where raw data lakes feed decision-critical marts, digna is worth evaluating as part of the operating layer. It focuses on data quality and observability across anomalies, schema changes, timeliness, and validation so teams can detect issues earlier and keep curated outputs trustworthy.



