Data Lake vs Data Mart: Dokonaj właściwego wyboru na rok 2026
|
7
min. czyt.

Twój zespół kierowniczy chce szybszych pulpitów nawigacyjnych, czystszych wskaźników KPI i przestrzeni dla sztucznej inteligencji oraz uczenia maszynowego. W tym samym czasie Twój zespół ds. danych zmaga się z surowymi logami, wyciągami z systemów SaaS, operacyjnymi bazami danych i zrzutami plików, które nie docierają na czas. Właśnie w takich sytuacjach decyzja dotycząca wyboru między data lake a data mart jest zazwyczaj przedstawiana w zbyt uproszczony sposób.
W praktyce nie jest to tylko kwestia wyboru miejsca przechowywania danych. To wybór dotyczący zaufania. Jezioro danych (data lake) zapewnia elastyczność i skalowalność. Mart danych (data mart) daje zespołom biznesowym spójność i szybkość. Najtrudniejsza część to to, co dzieje się pomiędzy nimi. Jeśli nie kontrolujesz jakości, pochodzenia danych (lineage) i wykrywania zmian, jezioro staje się obciążeniem, a mart danych – jedynie dopracowaną warstwą błędnych założeń.
Dla większości organizacji planujących platformę danych nowej generacji kluczowe pytanie nie brzmi, które rozwiązanie jest ogólnie lepsze. Chodzi o to, jaką rolę powinno odgrywać każde z nich i jak zachować niezawodność na ścieżce od surowych danych do danych gotowych dla biznesu.
Spis treści
Czym jest Data Lake, a czym Data Mart
Data lake (jezioro danych) to centralne repozytorium dla surowych danych w wielu formatach. Może przechowywać ustrukturyzowane tabele, półstrukturyzowane dane o zdarzeniach, logi aplikacji, dokumenty i inne dane źródłowe, zanim zespół ostatecznie zdecyduje, jak te dane będą modelowane lub odpytywane. Naczelną ideą jest elastyczność. Najpierw gromadzisz dane, a dopiero później nadajesz im kształt, gdy pojawia się jasny przypadek użycia biznesowego lub analitycznego.
Data mart (mart danych) działa inaczej. To wyselekcjonowana, dedykowana warstwa danych dla określonego obszaru, takiego jak finanse, sprzedaż, operacje czy obsługa klienta. Dane są oczyszczane, standaryzowane, testowane i organizowane, zanim trafią do użytkowników biznesowych. Naczelną ideą jest użyteczność. Ludzie nie powinni analizować wstecznie surowych systemów źródłowych tylko po to, by odpowiedzieć na proste pytanie raportowe.

Najprostszy model mentalny
Pomyśl o data lake jak o zbiorniku retencyjnym. Przechowuje on duże ilości napływających danych w ich pierwotnym stanie. Dzięki temu jest wartościowy, gdy firma chce zachować szczegółowość, wspierać prace z zakresu data science lub zachować otwarte opcje na potrzeby przyszłych analiz.
Pomyśl o data mart jak o rozlewni wody. Pobiera ona wybraną wodę ze zbiornika, filtruje ją, sprawdza jakość, pakuje i dostarcza w określonym celu. To sprawia, że jest wartościowy, gdy finanse potrzebują kontrolowanej definicji przychodów, a dział operacyjny potrzebuje wiarygodnego pulpitu nawigacyjnego poziomu usług.
Zasada praktyczna: Jeśli użytkownicy potrzebują swobody w badaniu nieznanych pytań, zacznij bliżej jeziora. Jeśli potrzebują powtarzalnych odpowiedzi na potrzeby znanego procesu, zacznij bliżej martu.
Dlaczego to rozróżnienie ma znaczenie dla kadry kierowniczej
Liderzy często słyszą, że jeziora danych są nowoczesne, a marty przestarzałe, albo że marty są sztywne, a jeziora tanie. Żadne z tych ujęć nie jest pomocne. Liczy się to, jakiemu zadaniu biznesowemu służy każde z nich.
Jezioro wspiera szerokość. To tutaj zespoły inżynieryjne zachowują wierność źródłom, szybko wdrażają nowe źródła danych i wspierają analitykę eksploracyjną. Mart wspiera precyzję. To tutaj zespoły ds. governance definiują logikę biznesową, dostosowują wskaźniki i zmniejszają opory przy podejmowaniu decyzji.
Jeśli w ramach szerszej platformy oceniasz również zarządzane usługi relacyjne, ten przewodnik po RDS dla firm na Filipinach stanowi przydatne źródło wiedzy o tym, jak bazy operacyjne współistnieją z warstwami analitycznymi. Systemy transakcyjne, surowe magazyny analityczne i wyselekcjonowane modele analityczne rozwiązują różne problemy.
Gdzie zespoły wpadają w kłopoty
Częstym błędem w dyskusjach dotyczących wyboru między data lake a data mart jest zakładanie, że jezioro służy tylko do etapowania (staging), a mart wyłącznie do raportowania. Pomija to ciężar operacyjny pośrodku. Surowa elastyczność generuje pracę nad czyszczeniem danych na dalszych etapach. Z kolei uporządkowana dostępność wymaga dyscypliny w modelowaniu na wcześniejszych etapach.
Zespoły szukające drogi środka często analizują podejście lakehouse i sposoby na utrzymanie jakości danych, zwłaszcza gdy chcą zmniejszyć dublowanie danych między surowym magazynem a analitycznymi warstwami prezentacji. Nawet wtedy obowiązuje ta sama prawda architektoniczna: surowe dane i zaufane dane biznesowe nie powinny być traktowane tak, jakby obowiązywał je ten sam standard jakości.
Głęboka analiza architektoniczna – bezpośrednie porównanie
Najczystszym sposobem na porównanie data lake vs data mart jest przyjrzenie się, jak każde z nich zachowuje się pod realną presją operacyjną.
Cecha | Data Lake | Data Mart |
|---|---|---|
Struktura danych | Surowa, o różnych formatach, często minimalnie przetworzona | Ustrukturyzowana, oczyszczona, gotowa dla biznesu |
Podejście do schematu | Schema-on-read (nakładany przy odczycie) | Schema-on-write (nakładany przy zapisie) |
Główny cel | Zachowanie szczegółów i wsparcie elastycznej eksploracji | Dostarczanie spójnych analiz dla określonej funkcji biznesowej |
Typowi użytkownicy | Inżynierowie danych, naukowcy ds. danych, zespoły ML | Analitycy, zespoły finansowe, użytkownicy BI, interesariusze biznesowi |
Styl przetwarzania | Często zorientowany na ELT | Często zorientowany na ETL przed konsumpcją |
Wzorzec zapytań | Badawczy, zdominowany przez procesy wsadowe, zróżnicowane obciążenia | Powtarzalny, wysoka wartość raportów i dostęp do pulpitów |
Podejście do governance | Często łagodniejsze przy pobieraniu, silniejsze później (przy odpowiedniej dojrzałości) | Silniejsze na starcie, ponieważ wyniki służą do podejmowania decyzji biznesowych |
Tolerancja na zmiany | Wyższa tolerancja na zmienność źródeł | Niższa tolerancja, ponieważ raporty muszą pozostać stabilne |
Oczekiwana wydajność | Dobra do przechowywania na dużą skalę i eksperymentów | Lepiej dostosowana do szybkiej, celowanej konsumpcji analitycznej |
Profil kosztów | Wydajne przechowywanie, lecz złożoność operacyjna może rosnąć | Większy nakład pracy na transformację i modelowanie, ale wyraźniejsza wartość biznesowa przy konsumpcji |
Elastyczność kontra kontrola
Jezioro wygrywa, gdy organizacja nie zna jeszcze wszystkich pytań, jakie zada w przyszłości. Telemetria produktów, zdarzenia typu clickstream, logi, dokumenty i wyciągi źródłowe mogą trafiać do systemu bez konieczności natychmiastowego modelowania. Jest to przydatne, gdy Twoja mapa drogowa obejmuje eksperymenty, inżynierię cech lub szerokie zachowywanie historii źródeł.
Mart wygrywa, gdy organizacja zna pytania. Miesięczne zamknięcie, raportowanie marż, przeglądy pipeline'ów, analiza roszczeń i pulpity regulacyjne zależą od stabilnych definicji. Użytkownicy oczekują zaufanej liczby, a nie punktu wyjścia do własnej interpretacji.
Jezioro przechowuje możliwości. Mart dostarcza zobowiązania.
Ukryty kompromis architektoniczny
Wiele zespołów kierowniczych porównuje jedynie format przechowywania i typ użytkownika. Podstawowym kompromisem jest jednak model operacyjny.
Jezioro przesuwa wysiłek na dalsze etapy. Inżynierowie mogą szybko pobierać dane, ale ktoś nadal musi uzgadniać identyfikatory, radzić sobie z brakującymi wartościami, standaryzować daty, definiować reguły biznesowe i rozwiązywać konflikty źródłowe. Jeśli ta dyscyplina nigdy nie zostanie wdrożona, jezioro gromadzi dane, nie generując wiarygodnych wyników.
Mart przesuwa wysiłek na wcześniejsze etapy. Zespoły muszą uzgodnić definicje, zanim dane zostaną udostępnione do powszechnego użytku. Może to wydawać się wolniejsze, ale zmniejsza powtarzające się zamieszanie. Kosztem jest nie tylko praca techniczna. To wewnętrzne dopasowanie organizacji.
What works and what doesn't
Kilka schematów konsekwentnie się sprawdza:
Używaj jeziora do zapisu i zachowywania: Zachowaj wierność źródłom tam, gdzie surowe szczegóły mają znaczenie.
Używaj martu do danych decyzyjnych: Umieść zarządzane wskaźniki KPI i wyselekcjonowane wymiary tam, gdzie działają zespoły biznesowe.
Oddziel szybkość pozyskiwania od zaufania przy konsumpcji: Szybkie wdrażanie i niezawodne raportowanie nie powinny być wymuszane na tej samej warstwie.
Inne schematy zazwyczaj zawodzą:
Pozwalanie każdemu zespołowi bezpośrednio odpytywać jezioro: Często prowadzi to do niespójnych metryk i powielania logiki.
Budowanie odizolowanych martów bezpośrednio z systemów operacyjnych: Na początku jest to szybkie, ale później kosztowne w utrzymaniu.
Traktowanie surowych danych jako gotowych dla biznesu tylko dlatego, że są dostępne: Dostępność to nie to samo co jakość.
Perspektywa kadry kierowniczej
Jeśli finansujesz platformę, nie pytaj tylko, gdzie dane będą przechowywane. Zapytaj, gdzie będą znajdować się definicje metryk, kto odpowiada za zgodność ze źródłem i jak wykrywane będą błędy, zanim zobaczą je dyrektorzy. To właśnie w tym miejscu decyzja dotykająca wyboru między jeziorem a martem staje się strategią platformy, a nie debatą o narzędziach.
Dopasowanie architektury do przypadku użycia
Właściwa architektura staje się oczywista, gdy przyjrzysz się pracy, jaką ludzie muszą wykonać.
Kiedy data lake jest odpowiednim wyborem
Zespół ds. produktu i ML zazwyczaj potrzebuje surowych szczegółów behawioralnych. Chcą logów sesji, ładunków zdarzeń, interakcji ze wsparciem, sygnałów z urządzeń i danych wejściowych do trenowania modeli bez silnego filtrowania przy pobieraniu. Mogą wracać do starych danych z nową hipotezą lub łączyć źródła, które pierwotnie nie były zaprojektowane do odpowiadania na to samo pytanie.
To jest przypadek użycia dla data lake. Zespół potrzebuje przestrzeni do eksploracji, łączenia, wzbogacania i ponownego przetwarzania. Wciskanie tego zbyt wcześnie do ściśle kontrolowanego martu usuwa szczegóły i generuje ciągłą pracę nad przebudową modeli.
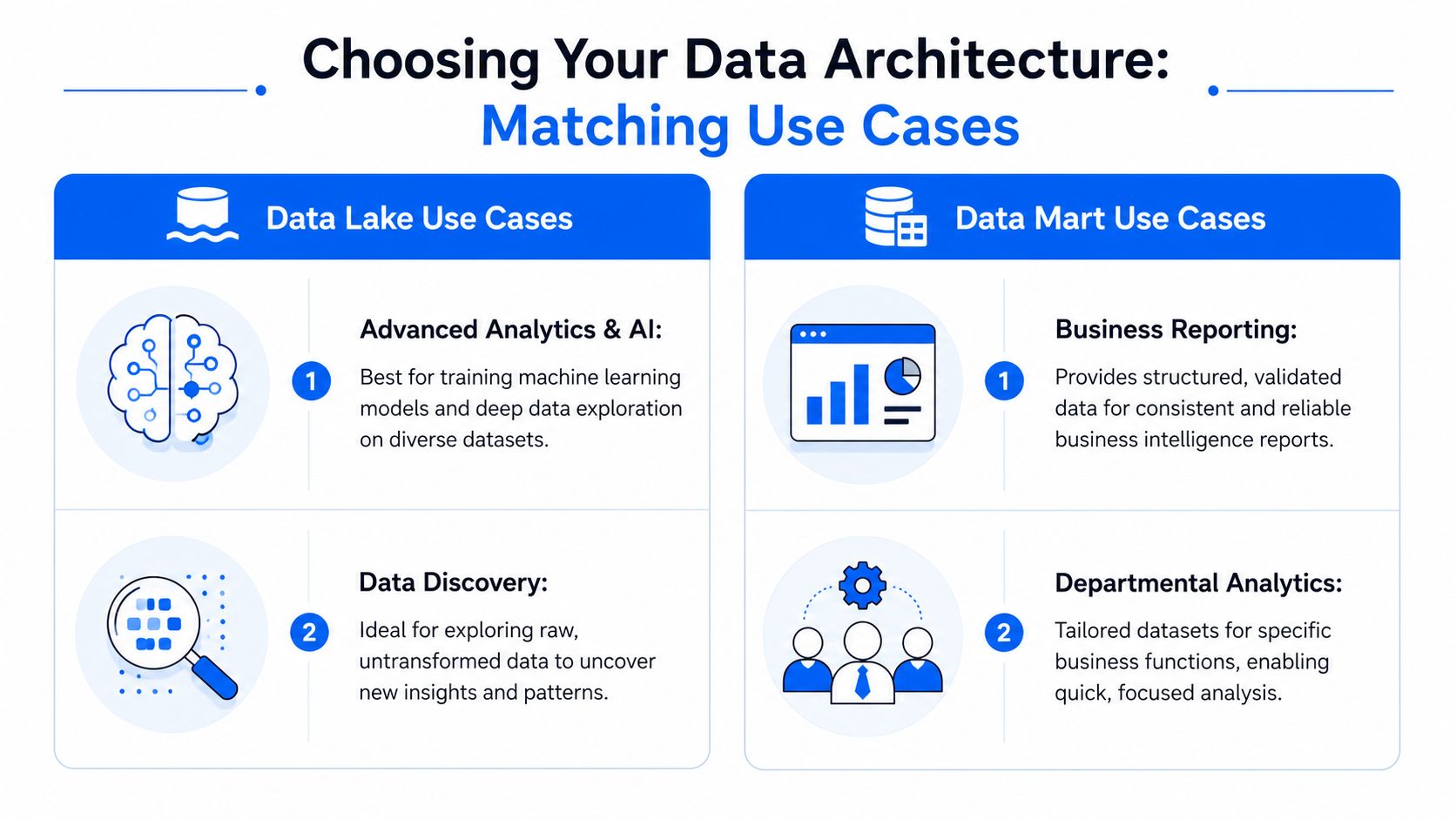
Kiedy data mart jest lepszym rozwiązaniem
Zespół finansowy ma niemal odwrotne potrzeby. Nie potrzebuje każdego surowego stanu transakcji, każdego pośredniego zdarzenia ani wielu możliwych interpretacji przychodów. Chce jednego, poddanego nadzorowi zestawu definicji dla rezerwacji, uznanych przychodów, alokacji kosztów i raportów z zamknięcia okresu.
To jest przypadek użycia dla data mart. Mart celowo zawęża zakres. Eliminuje niejednoznaczność, dzięki czemu kwartalne raportowanie nie zamienia się w kłótnię o semantykę systemów źródłowych.
Dwa praktyczne przykłady
Rozważ te powszechne wzorce:
Przepływ pracy data science: Inżynierowie zapisują zdarzenia aplikacji, dane wyjściowe z API i migawki historyczne w jeziorze. Naukowcy ds. danych budują cechy na podstawie surowych sekwencji i dostosowują transformacje do zmieniających się wymagań modeli.
Przepływ pracy BI dla działu: Inżynierowie analityczni publikują mart finansowy ze spójnymi wymiarami, zatwierdzonymi miarami i przetestowanymi powiązaniami, aby kontrolerzy i kadra kierownicza mogli korzystać z tych samych liczb.
Żaden z tych wzorców nie jest bardziej nowoczesny od drugiego. Rozwiązują one różne problemy biznesowe.
Jeśli zadaniem jest odkrywanie, zoptymalizuj system pod kątem dostępu do surowego kontekstu. Jeśli zadaniem jest rozliczalność, zoptymalizuj pod kątem spójności.
Co kadra kierownicza powinna ustandaryzować
Najsilniejsze platformy nie narzucają jednej architektury wszędzie. Standaryzują kryteria decyzyjne:
Typ konsumenta: Czy ten zestaw danych jest dla inżynierów i naukowców, czy dla operatorów biznesowych?
Tolerancja na niejednoznaczność: Czy użytkownicy mogą interpretować surowe sygnały, czy potrzebują zatwierdzonych definicji?
Częstotliwość zmian: Czy logika transformacji będzie ewoluować często, czy powinna pozostać stabilna na potrzeby ładu (governance)?
Konsekwencje błędu: Czy jest to analiza eksploracyjna, czy liczba używana do budżetu, Compliance lub raportowania zewnętrznego?
Te pytania zazwyczaj rozstrzygają debatę o data lake vs data mart szybciej niż jakiekolwiek długie porównanie narzędzi.
Kluczowa ścieżka od jeziora do martu: governance i jakość danych
Niebezpiecznym założeniem w wielu architekturach jest to, że przenoszenie danych z jeziora do martu to rutynowe zadanie rurociągu danych (pipeline). Tak nie jest. To faza, w której surowe, niespójne, dopasowane do systemów źródłowych informacje zamieniają się w prawdę biznesową. Ta konwersja wprowadza walidację, normalizację, dopasowywanie danych, deduplikację, wzbogacanie i decyzje dotyczące polityk, które wiele zespołów bagatelizuje.

Dlaczego przekazywanie danych kończy się niepowodzeniem
Surowe dane rzadko trafiają do martu w stanie gotowym do użytku. Systemy źródłowe różnie kodują statusy. Klucze nie pasują do siebie idealnie. Opcjonalne pola stają się obowiązkowe na dalszych etapach. Znaczniki czasu ulegają przesunięciu. Pliki przychodzą z opóźnieniem. Zmiana schematu w jednym źródle może subtelnie unieważnić logikę transformacji kilka kroków dalej.
Dlatego governance nie może być dodawany na siłę po uruchomieniu. Reguły walidacji, własność, pochodzenie danych (lineage) i kryteria akceptacji muszą być wbudowane w tę ścieżkę od samego początku.
Pomocny jest tu praktyczny przewodnik po kontraktach danych i ich wdrażaniu, ponieważ koncepcja Data Contract zmusza zespoły do zdefiniowania, co systemy nadrzędne mają dostarczyć, zanim zależne będą od nich końcowe marty danych.
Błędy jakościowe, którymi powinna przejmować się kadra kierownicza
W badaniu z 2024 roku dotyczącym sektora opieki zdrowotnej wykazano, że aż do 40% eksportów z data lake kończy się niepowodzeniem walidacji reguł biznesowych przed dotarciem do martów danych, gdy brakuje zautomatyzowanych kontroli jakości, co prowadzi do przerw w działaniu rurociągów danych i nieaktualnych raportów, jak opisano w tym badaniu jakości danych w opiece zdrowotnej. To jest rzeczywistość operacyjna, którą wiele diagramów architektonicznych pomija.
Konsekwencje biznesowe są bezpośrednie. Jeśli Twój mart danych jest warstwą, której ufa kadra zarządzająca, wówczas ścieżka od jeziora do martu nie jest tylko hydraulicznym systemem inżynierii. To punkt kontrolny.
Porada operacyjna: Nie zatwierdzaj nowego martu bez uzgodnienia odpowiedzialności za walidację, obsługi wyjątków i zasad wycofywania zmian (rollback).
Co wdrażają silne zespoły
Zespoły, które dobrze zarządzają tym przejściem, zazwyczaj formalizują kilka mechanizmów kontrolnych:
Kryteria wejściowe dla danych źródłowych: Określ, co musi znajdować się w zbiorze danych, zanim będzie mógł pójść dalej.
Punkty kontrolne transformacji: Testuj połączenia (joins), obsługę wartości null, mapowanie kodów i zgodność z regułami biznesowymi podczas przetwarzania.
Dyscyplina wdrożeń: Zarządzaj wersjami logiki transformacji i dokumentuj zmiany definicji metryk przed ich opublikowaniem.
Ścieżki eskalacji: Upewnij się, że nieudane kontrole wywołują konkretne działania, a nie tylko zapis w logach.
Krótkie wyjaśnienie podejścia zorientowanego na rurociągi danych (pipelines) jest pomocne przed przystąpieniem do dyskusji o narzędziach:
Ukryty koszt jest zazwyczaj operacyjny, a nie związany z przechowywaniem
Liderzy często planują budżet na przechowywanie, nie doceniając kosztów naprawy danych. Najdroższą częścią nie jest utrzymywanie surowych danych w jeziorze. To powtarzający się wysiłek wymagany, gdy dane o słabej jakości przedostają się na dalsze etapy, a zespoły gorączkowo próbują uzgadniać zepsute raporty, ponownie uruchamiać zadania i wyjaśniać sprzeczne liczby.
Dlatego decyzje data lake vs data mart powinny uwzględniać projekt governance jako kluczowy element. Jeśli ścieżka między nimi jest słaba, platforma będzie wyglądać na kompletną na papierze, ale w praktyce będzie niewiarygodna.
Zapewnienie zaufania dzięki Data Observability
Większość incydentów związanych z danymi nie zaczyna się tam, gdzie zauważają je użytkownicy. Ujawniają się one w marcie, ponieważ tam ludzie patrzą, ale źródło problemu często tkwi wcześniej – w jeziorze lub w zasilających je przepływach pobierania danych.
Dlaczego samo monitorowanie martu danych nie wystarcza
Pulpit nawigacyjny może przestać działać, ponieważ plik źródłowy przyszedł za późno, zmienił się typ kolumny, ładowanie zakończyło się tylko częściowo lub rozkład danych, który dotychczas był stabilny, przesunął się na tyle, że naruszył założenia kolejnych procesów. Jeśli monitorujesz tylko tabelę końcową lub zapytanie pulpitu nawigacyjnego, odkrywasz problem dopiero po tym, jak firma zdążyła już zderzyć się z konsekwencjami.
Najnowsze badania z 2024 roku wskazują, że 65% incydentów związanych z jakością danych w martach danych ma swoje źródło w niemonitorowanych problemach we wcześniejszych jeziorach danych, w tym w modyfikacjach schematów oraz opóźnieniach w ładowaniu, jak podaje to badanie nad przyczynami incydentów jakości na wcześniejszych etapach.

Co musi śledzić Observability
W nowoczesnej platformie Observability powinno obejmować przynajmniej następujące scenariusze błędów:
Problemy z terminowością: Wykrywaj opóźnione lub brakujące dane, zanim wpłynie to na okna raportowe.
Odchylenia schematu (schema drift): Wychwytuj dodane, usunięte lub zmodyfikowane pola, zanim zadania transformacji nieoczekiwanie się wyłożą.
Anomalie w danych: Oznaczaj nieoczekiwane zmiany w rozkładzie danych, przesunięcia wolumenu lub nietypowe wartości, które mogą wskazywać na problemy ze źródłem.
Luki walidacyjne: Potwierdzaj, że rekordy nadal spełniają wymagania stawiane przez dalsze procesy biznesowe.
Data Observability integruje się z architekturą, a nie tylko z operacjami. Jeśli Twoje jezioro jest elastyczne z założenia, to Twój monitoring musi charakteryzować się dyscypliną z założenia.
Jeden praktyczny schemat narzędziowy
Zespoły zazwyczaj łączą alerty orkiestracji, testy transformacji, pochodzenie metadanych i narzędzia do obserwacji. Jednym z przykładów jest artykuł o tym, jak wyjaśniono różnice między data observability a jakością danych, który pomaga zrozumieć, że obserwowanie zachowania rurociągów danych, a walidacja reguł biznesowych to działania powiązane, ale nie identyczne.
W tej kategorii jednym z rozwiązań monitorujących anomalie, terminowość, zmiany schematów i walidację na poziomie rekordów w jeziorach, hurtowniach i rurociągach danych jest digna. Wykonuje ono analizy wewnątrz środowiska klienta, co ma kluczowe znaczenie w regulowanych branżach, gdzie zespoły potrzebują widoczności operacyjnej bez masowego przenoszenia danych.
Niezawodny mart zależy od monitorowanego jeziora. Zaufanie na dalszych etapach zaczyna się na wcześniejszych szczeblach.
Co się zmienia po wdrożeniu Observability
Najważniejsza zmiana ma charakter organizacyjny. Zespoły ds. danych przestają polegać na użytkownikach biznesowych jako pierwszych wykrywcach problemów. Inżynierowie widzą opóźnienia w dostawach danych, zanim CFO zobaczy nieaktualny pulpit. Analitycy zyskują kontekst pozwalający ocenić, czy metryka zmieniła się pod wpływem zmian w biznesie, czy z powodu problemów z samymi danymi. Zespoły ds. governance zyskują czytelniejszą ścieżkę audytu, która wyjaśnia, dlaczego dany zestaw danych nadawał się lub nie nadawał do użytku.
To jest brakujące ogniwo w wielu dyskusjach o data lake vs data mart. Wybory architektoniczne są ważne, ale zaufanie wynika z tego, jak aktywnie obserwujesz ścieżkę pomiędzy nimi.
Ramy decyzyjne – czego potrzebujesz
Błędnym sposobem na rozstrzygnięcie dylematu data lake vs data mart jest kierowanie się ogólnymi preferencjami. Właściwa droga to zadanie kilku konkretnych pytań biznesowych i operacyjnych.
Lista kontrolna dla liderów
Czy potrzebujesz zachować surowe dane w wielu formatach do celów przyszłych analiz? Jeśli tak, prawdopodobnie potrzebujesz elementu typu lake.
Czy Twoi użytkownicy potrzebują nadzorowanych metryk do podejmowania powtarzalnych decyzji biznesowych? Jeśli tak, potrzebujesz co najmniej jednego elementu typu mart.
Czy Twoimi głównymi odbiorcami są naukowcy ds. danych i inżynierowie? Postaw na dostęp do surowych danych i elastyczne przetwarzanie.
Czy Twoimi głównymi odbiorcami są analitycy, kontrolerzy lub kadra zarządzająca? Postaw na dopracowane modele i stabilną semantykę.
Czy Twój zespół jest w stanie utrzymać mechanizmy kontroli jakości między warstwami? Jeśli nie, nie zakładaj, że jezioro uprości platformę.
Czy w tym przypadku użycia spójność metryk jest ważniejsza niż kompletność źródła danych? Jeśli tak, publikuj dane przez mart, a nie bezpośrednio z surowego magazynu.

Odpowiedzią często są oba rozwiązania
W dojrzałych platformach wybór brzmi zazwyczaj „i”, a nie „lub”. Jezioro staje się warstwą zapisu i eksploracji. Mart staje się warstwą konsumpcji dla określonych obszarów biznesowych. Strategiczne zadanie polega na podjęciu decyzji, gdzie umieścić bramki jakościowe, kto odpowiada za transformacje i jak wykrywać problemy, zanim wpłyną one na raportowanie.
Jeśli kadra zarządzająca chciałaby zapamiętać jedną kluczową zasadę, oto ona: przechowuj szeroko, publikuj wąsko i monitoruj ścieżkę pomiędzy nimi. Takie podejście daje firmie przestrzeń do rozwoju bez utraty zaufania do liczb, za pomocą których zarządza się przedsiębiorstwem.
Jeśli Twój zespół buduje platformę, w której surowe jeziora danych zasilają krytyczne dla decyzji biznesowych marty danych, warto rozważyć wdrożenie rozwiązania digna jako części warstwy operacyjnej. Koncentruje się ono na jakości danych i Observability w obszarze anomalii, zmian schematów, terminowości oraz walidacji, umożliwiając zespołom szybsze wykrywanie problemów i utrzymanie zaufania do wyselekcjonowanych danych wyjściowych.




Poznaj zespół tworzący platformę
Zespół z Wiednia, składający się z ekspertów od AI, danych i oprogramowania, wspierany rygorem akademickim i doświadczeniem korporacyjnym.