Por qué los trabajos de Databricks se vuelven impredecibles - Y cómo los equipos detectan la inestabilidad temprano
|
5
minuto de lectura

Databricks los entornos están diseñados para la elasticidad. Los clústeres se escalan, las cargas de trabajo evolucionan y los volúmenes de datos crecen continuamente. Esta flexibilidad es poderosa; sin embargo, también introduce un desafío que muchas empresas enfrentan eventualmente:
Trabajos que una vez se comportaron de manera predecible comienzan a fluctuar en tiempo de ejecución, uso de DBU y costo.
Las canalizaciones aún tienen éxito. Los paneles de control todavía se actualizan. Nada parece “roto.” Sin embargo, la previsibilidad operativa se erosiona.
Entender por qué esto sucede y cómo detectarlo temprano es crítico para los equipos que ejecutan Databricks como una plataforma de datos y AI de producción.
La inestabilidad en Databricks se trata de comportamiento, no de fallos
En los sistemas tradicionales, la inestabilidad a menudo significaba sobrecarga del sistema o límites de hardware. La inestabilidad de Databricks es diferente.
Debido a que los clústeres se autoescalan y las cargas de trabajo se distribuyen dinámicamente, la inestabilidad se manifiesta como:
Aumento del consumo de DBU para los mismos trabajos
Incremento de la varianza en duración de ejecución
Rendimiento de tareas impredecible
Eventos de redimensionamiento de clúster más frecuentes
Los trabajos pueden completarse con éxito, pero su comportamiento cambia con el tiempo. Estos cambios a menudo son invisibles en los paneles de control enfocados solo en el éxito/fallo.
¿Qué causa que los trabajos de Databricks se vuelvan impredecibles?
1. El crecimiento de datos altera los planes de ejecución
A medida que los volúmenes de datos crecen:
Aumentan los mezclados
Se hacen más pesadas las uniones
Las estrategias de particionamiento se degradan
Cambia la efectividad del almacenamiento en caché
Incluso sin cambios de código, los planes de ejecución de Spark cambian. Esto lleva a un mayor uso de DBU y tiempos de ejecución más largos.
El trabajo aún “funciona,” pero consume más computación que antes.
2. Deriva de lógica en cuadernos y canalizaciones
Las cargas de trabajo de Databricks evolucionan rápidamente.
Los equipos añaden:
Uniones adicionales
Agregaciones adicionales
Nuevos cálculos de características ML
Filtros más amplios
Cada modificación añade sobrecarga. Individualmente, los cambios parecen menores. Con el tiempo, alteran fundamentalmente el comportamiento de la carga de trabajo.
3. El autoescalado oculta problemas de recursos
El autoescalado es tanto una fortaleza como un punto ciego.
Cuando las cargas de trabajo demandan más computación:
Los clústeres se expanden automáticamente
Los trabajos se completan con éxito
Los costos aumentan silenciosamente
En lugar de fallar, el sistema absorbe ineficiencias, ocultando regresiones de rendimiento detrás de una infraestructura elástica.
La primera señal a menudo aparece como un aumento del consumo de DBU, no un error.
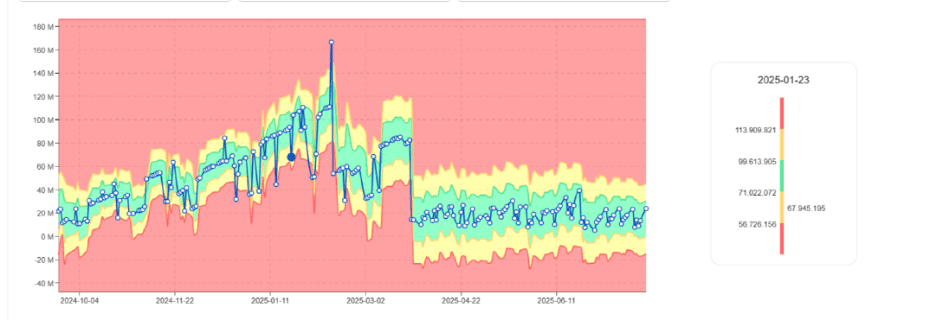
Tendencia de uso de DBU aumentando gradualmente para el mismo trabajo
4. Desequilibrio de sesgo y shuffle
Desviación de datos causa que ciertas tareas procesen cantidades desproporcionadas de datos.
En Databricks, esto se manifiesta como:
Tareas de larga duración
Retrasos
Incremento en la varianza de duración de la etapa
Debido a que Spark distribuye las tareas dinámicamente, el sesgo produce tiempos de ejecución inestables y consumo de DBU impredecible.
5. Comportamiento de reintento y fallas ocultas
Los reintentos de tareas son comunes en sistemas distribuidos.
Problemas transitorios, presión de memoria o pérdida de ejecutores pueden desencadenar reintentos que:
Aumentan el tiempo de ejecución
Inflan el consumo de DBU
Añaden volatilidad
Los trabajos tienen éxito, pero la inestabilidad aumenta.
6. Temporalidad en las cargas de trabajo
Los trabajos de Databricks a menudo reflejan ciclos de negocio:
Procesamiento de final de mes
Picos de informes semanales
Horarios de reentrenamiento de modelos
Sin modelar estos patrones, los equipos ignoran anomalías o se abruman con alertas falsas.
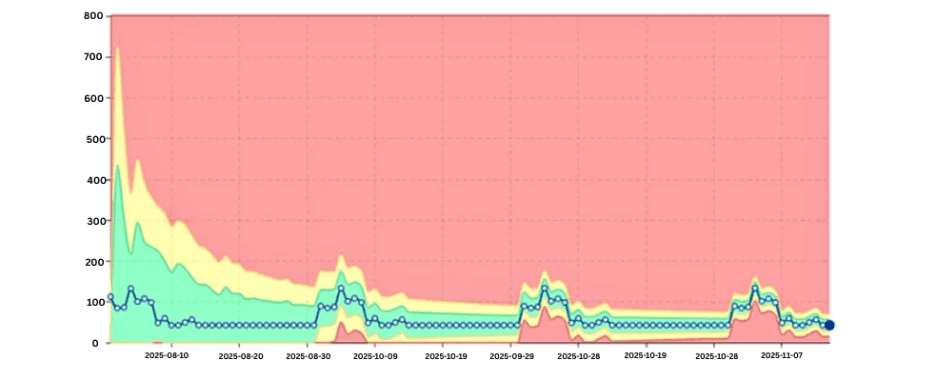
Patrón estacional de DBU con picos esperados
Por qué el monitoreo tradicional pierde señales tempranas
La mayoría de los equipos confían en:
Métricas de éxito/fallo de trabajos
Paneles de control de costos
Vistas de utilización de clústeres
Estas herramientas muestran resultados, no cambios de comportamiento.
No revelan:
Trabajos que se vuelven más caros con el tiempo
Aumento de la variabilidad en tiempo de ejecución
Cambios estructurales en la ejecución de la carga de trabajo
La inestabilidad comienza mucho antes de que se crucen los umbrales.
El cambio hacia el monitoreo del comportamiento
Detectar inestabilidad temprano requiere analizar cómo se comportan las cargas de trabajo con el tiempo, no solo si tienen éxito.
Señales clave incluyen:
Tendencias de uso de DBU
Evolución del tiempo de ejecución
Varianza en la duración de la tarea
Frecuencia de escalado de clúster
Al convertir estas métricas en datos de series temporales, los equipos pueden identificar desviaciones, volatilidad y cambios estructurales.
Detectando inestabilidad temprano
Aprendiendo el comportamiento normal de trabajos
En lugar de umbrales de DBU fijos, los enfoques modernos aprenden:
Rango típico de DBU por trabajo
Patrones esperados de tiempo de ejecución
Comportamiento normal del clúster
A medida que las cargas de trabajo se estabilizan, los rangos de comportamiento aceptables se estrechan.
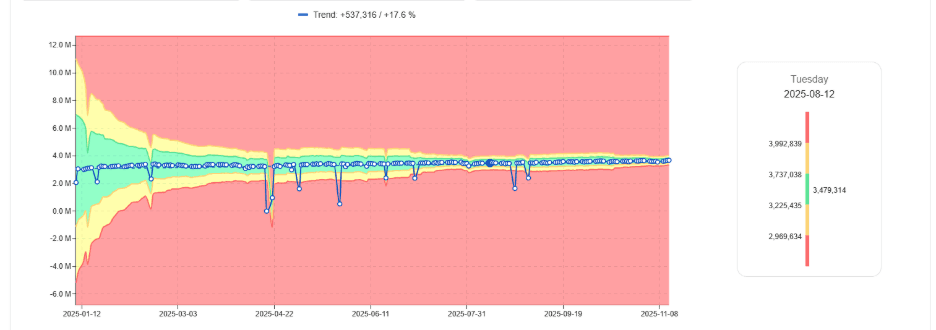
Banda de DBU aprendida normal estrechándose con el tiempo
Detectando deriva gradual de DBU
Uno de los mayores impulsores de costos es el crecimiento lento de DBU.
Al comparar el uso actual con las líneas base históricas, los equipos pueden identificar qué trabajos están consumiendo progresivamente más computación.
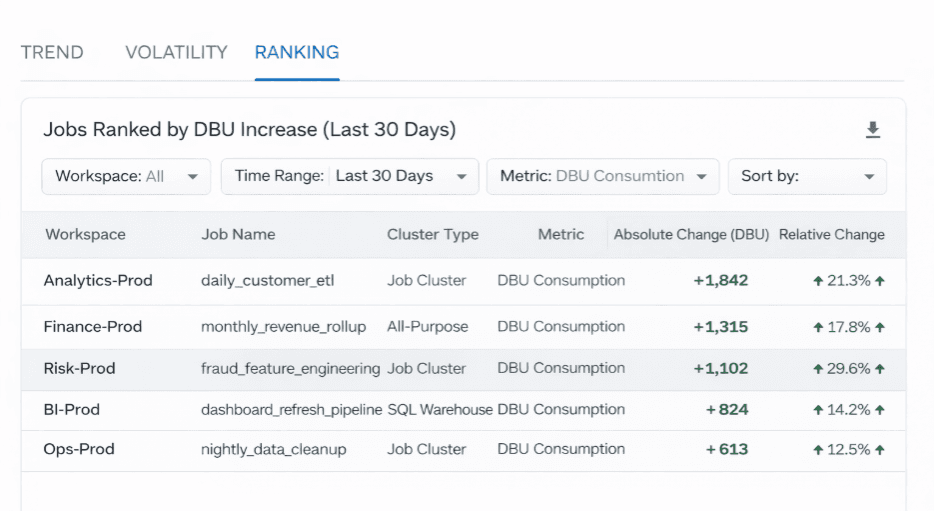
Trabajos clasificados por aumento de DBU mes a mes
Midiendo la volatilidad del tiempo de ejecución
Incluso si el tiempo de ejecución promedio se mantiene constante, una alta varianza señala inestabilidad.
Los trabajos volátiles son más difíciles de planificar y más propensos a causar retrasos posteriores.
Teniendo en cuenta la temporalidad
Los sistemas de comportamiento distinguen picos cíclicos esperados de anomalías genuinas, reduciendo el ruido de alertas.
Dónde encaja digna
digna analiza las métricas de carga de trabajo de Databricks, como uso de DBU, tiempo de ejecución y comportamiento de volumen a lo largo del tiempo. En lugar de límites estáticos, utiliza AI para aprender patrones normales y detectar desviaciones improbables temprano, ya sean picos repentinos o derivas graduales.
Esto permite que los equipos aborden problemas antes de que aparezcan en informes de costos o incumplimientos de SLA.
Más sobre este enfoque impulsado por anomalías se puede encontrar:
digna Data Anomalies | Ver demostración
Por qué importa la detección temprana
Cuando se detecta inestabilidad temprano, las organizaciones pueden:
Optimizar consultas antes de que los costos se disparen
Estabilizar canalizaciones antes de que se vean afectadas las SLAs
Reducir la lucha contra incendios
Mejorar la previsibilidad para los equipos de FinOps
Pensamiento final
Los trabajos de Databricks rara vez fallan por completo. Se vuelven impredecibles.
Esa imprevisibilidad es visible en el cambio de comportamiento de DBU, la variabilidad del tiempo de ejecución y los patrones de ejecución en evolución, señales que el monitoreo estático no puede capturar.
Los equipos que adoptan el monitoreo del comportamiento obtienen visibilidad temprana de la inestabilidad, manteniendo el control mientras sus entornos de Databricks escalan.



