What Is Data Residency: Your 2026 Compliance Guide
|
0
min. Lesezeit

A lot of teams think they've already solved data residency because they picked the “right” cloud region. Then legal forwards a customer questionnaire asking for proof that personal data, backups, logs, and downstream processing never leave a specific jurisdiction.
That's the moment the easy answer falls apart.
You start tracing the actual path of data. Application writes land in one region. Managed backups replicate elsewhere. Analytics events flow into a third-party platform. A support export gets downloaded by a team in another country. A machine learning workflow copies a slice into a different environment. Nobody planned a violation, but the architecture still created one.
That's why “what is data residency” isn't a basic glossary question anymore. It's a system design question. It affects how you structure storage, pipelines, observability, disaster recovery, vendor selection, and audit evidence. The teams that handle it well treat it as an operational constraint from day one, not a checkbox added after procurement.
Table of Contents
Your Data Isn't Where You Think It Is
The usual scenario looks familiar. A product team launches in Europe, selects an EU cloud region, and assumes the residency question is closed. Months later, enterprise procurement asks for written assurance that customer data will remain inside European borders across storage, processing, recovery, and monitoring.
That's when teams realize they know where the main database sits, but not where everything else goes.
The backup policy may replicate snapshots to a second geography. A managed message queue may fail over across regions. A BI tool may cache extracts outside the intended jurisdiction. A support workflow may include manual CSV exports. Even metadata can become a problem if tools ship table samples or query traces to a vendor-controlled SaaS backend.
The hidden map nobody maintains
Most organizations have fragments of the truth in different places. Infrastructure knows the cloud regions. Security knows the vendors. Data engineering knows the pipelines. Application teams know the services they integrated. Nobody owns the full movement map unless the company has built that discipline deliberately.
That's why data residency work often starts with discovery, not configuration.
If you need a clean way to reason about movement, storage, and transformation, it helps to separate origin from flow. This overview of data provenance vs data lineage is useful because residency problems usually hide in the path between systems, not only in the final table.
The fastest way to fail a residency review is to answer with your primary storage region and ignore backups, logs, temp files, and vendor side effects.
What breaks in practice
What works poorly is a narrow view of “data location” that only checks the production database.
What works better is asking harder questions:
Where is data ingested: Web app, mobile app, batch import, API, partner feed.
Where is it processed: ETL jobs, feature engineering, search indexing, analytics, alerting.
Where is it copied: Snapshots, restores, test environments, archives, data shares.
Who can move it: Admins, vendors, support staff, automation, managed services.
The important shift is practical. Residency isn't a document your legal team files away. It's a property of the architecture you run.
Unpacking Data Residency and Its Core Principle
Data residency is the physical or geographic location where data is stored and processed. It has become more important for compliance because cross-border data flows have surged by over 300% in the last decade, according to StratoKey's explanation of data residency.
Think of a bank vault
A simple analogy helps. If you place valuables in a safe deposit box, the location of that vault matters. A vault in Paris sits under one legal and operational environment. A vault in Toronto sits under another. The same logic applies to digital systems.
When people ask what is data residency, the shortest useful answer is this: it's the commitment to keep data inside a defined geographic boundary for storage and processing.
That sounds simple, but the key word is defined. The boundary might be a country, a region such as the EU, or an industry-specific jurisdiction tied to contract or regulation. Engineers need that boundary to be concrete enough to implement in infrastructure and policy.
Why the physical location matters
Physical location decides which local rules attach to the systems that hold the data. That makes residency a design requirement, not just a legal phrase. If your architecture writes data into one region but your batch jobs enrich it in another, your system may violate the residency requirement even though your “main” store looks compliant.
A useful mental model is to treat residency as a placement constraint.
Storage must be pinned to approved geography.
Processing must run in approved geography.
Operational copies must stay in approved geography.
Evidence must show that those rules are enforced.
Practical rule: If you can't answer where the data is stored, processed, backed up, restored, and observed, you don't yet have a residency design.
Where teams get tripped up
Teams usually understand the first copy. They miss the derived copies.
Common trouble spots include application logs, warehouse extracts, staging buckets, replay queues, support dumps, notebook-based analysis, and temporary files created by data tooling. Each one is small enough to ignore in isolation. Together they form the actual residency posture of the platform.
That's why the core principle is broader than “pick a local region.” You're defining where data is allowed to exist throughout its working life.
Residency vs Sovereignty vs Localization
People mix these terms constantly, and that leads to bad decisions. A team hears “keep data in the EU” and assumes the legal issue is solved. Often it isn't.

The short version
Data residency asks where data is physically stored and processed.
Data sovereignty asks which legal authority can claim jurisdiction over that data.
Data localization is the stricter policy stance that requires data to stay within national borders, often by law or sector rule.
A concrete example makes the distinction clearer. A US company can store customer data in Germany and satisfy a German residency requirement for location. But sovereignty questions can still remain because legal access may depend on the provider's control structure and applicable foreign law.
Side by side comparison
Concept | Primary Focus | Example | Key Question |
|---|---|---|---|
Data Residency | Physical location of storage and processing | Customer records stored on servers in Germany | Where does the data live and run? |
Data Sovereignty | Legal jurisdiction and authority over data | Data in Germany may still face foreign lawful access claims depending on provider control | Whose laws can reach this data? |
Data Localization | Mandated in-country retention and processing | A national rule requiring regulated data to stay within domestic infrastructure | Must the data remain inside this country at all times? |
The legal layer matters more than many architecture diagrams admit. F5's analysis on sovereignty, resilience, and residency notes that sovereign access by foreign governments can override physical residency, and cites 2025 to 2026 industry analysis showing 42% of EU enterprises face sovereignty risks even when data is stored in EU regions.
Why engineers should care
If you're designing only for location, you can miss the actual compliance risk. Provider choice, corporate control, subcontractors, key management, support access, and legal response obligations all matter.
That means architecture reviews need both technical and legal questions:
Technical: Which region stores the data? Where do jobs run? Where do replicas go?
Legal: Which entity controls the service? Which jurisdiction applies to vendor access?
Operational: Can you prove data stayed in approved boundaries during incidents and restores?
Here's a short explainer if you want a non-text summary before taking this to stakeholders.
Localization changes the implementation burden
Localization is where flexibility drops fast. Residency may allow approved regional processing under specific conditions. Localization often expects a far tighter answer: domestic hosting, domestic processing, domestic support controls, and limited or tightly governed transfer mechanisms.
If residency tells you where to place the system, localization tells you how little freedom you have to move any part of it.
That's why teams shouldn't use these words as synonyms in contracts, architecture docs, or vendor reviews. They drive different technical commitments.
The Regulatory and Business Drivers of Data Residency
The regulatory push is obvious. The business push is just as strong.

Regulation forces precision
GDPR is the reference point many teams know first. As summarized in the verified guidance, GDPR requires that data on EU citizens be stored within the EU or in countries with equivalent data protection standards, and non-compliance penalties can reach up to 4% of annual global turnover. That framing is captured in this explanation of data residency and GDPR obligations.
Even when the law allows transfers under controlled mechanisms, the operational burden remains. Companies still need to know where data sits, where it moves, and how they justify each movement. In healthcare, finance, and the public sector, that burden is often even tighter because customer contracts and sector rules go beyond baseline privacy law.
Customers ask before auditors do
The commercial side has changed too. Enterprise buyers now ask detailed questions during procurement. They want to know where the data is stored, where support is provided, whether backups remain in-region, and whether subprocessors can move metadata or content out of the approved boundary.
Those questions aren't only for heavily regulated sectors. Any company selling into larger accounts will see them.
A clear answer creates trust. A vague answer slows deals, increases legal review, and raises doubts about whether the platform is mature enough for sensitive workloads.
The practical business case
Residency affects more than compliance posture.
Market access: Some customers won't sign unless data stays in a specific country or region.
Vendor selection: Region control, key management, and support model become buying criteria.
Incident response: It's easier to answer regulators and customers when system boundaries are explicit.
Reputation: Teams that can prove disciplined data handling look safer to buyers and boards.
The strongest organizations don't treat residency as a legal afterthought. They treat it as part of platform governance, alongside security, access control, and recovery planning.
Architecting for Residency Compliance A Practical Guide
Most residency failures don't come from one dramatic mistake. They come from ordinary automation doing exactly what it was configured to do.
A particularly important issue is the silent export. Residency is a lifecycle requirement across backups, disaster recovery, and processing pipelines, not just primary storage. A 2026 HIPAA guide reports that 68% of healthcare organizations experienced unintended cross-border data transfers due to backup replication ignoring residency rules, as described in Konfirmity's guide to HIPAA data residency.
Start with data mapping not provider marketing
“EU region available” is not a residency architecture.
Start by building a map of actual data motion:
Identify regulated datasets. Tag personal data, financial records, healthcare data, public-sector data, and contract-restricted datasets.
Trace all processing paths. Include ETL jobs, stream processors, warehouse transformations, model features, exports, and reverse ETL.
List every copy. Primary databases, replicas, snapshots, archives, caches, data science workspaces, and test refreshes.
Document vendors. Analytics, support, monitoring, fraud tools, CDPs, and file transfer services often move more than teams expect.
This work is tedious, but there's no substitute for it. Residency controls only work when they're attached to real flows.
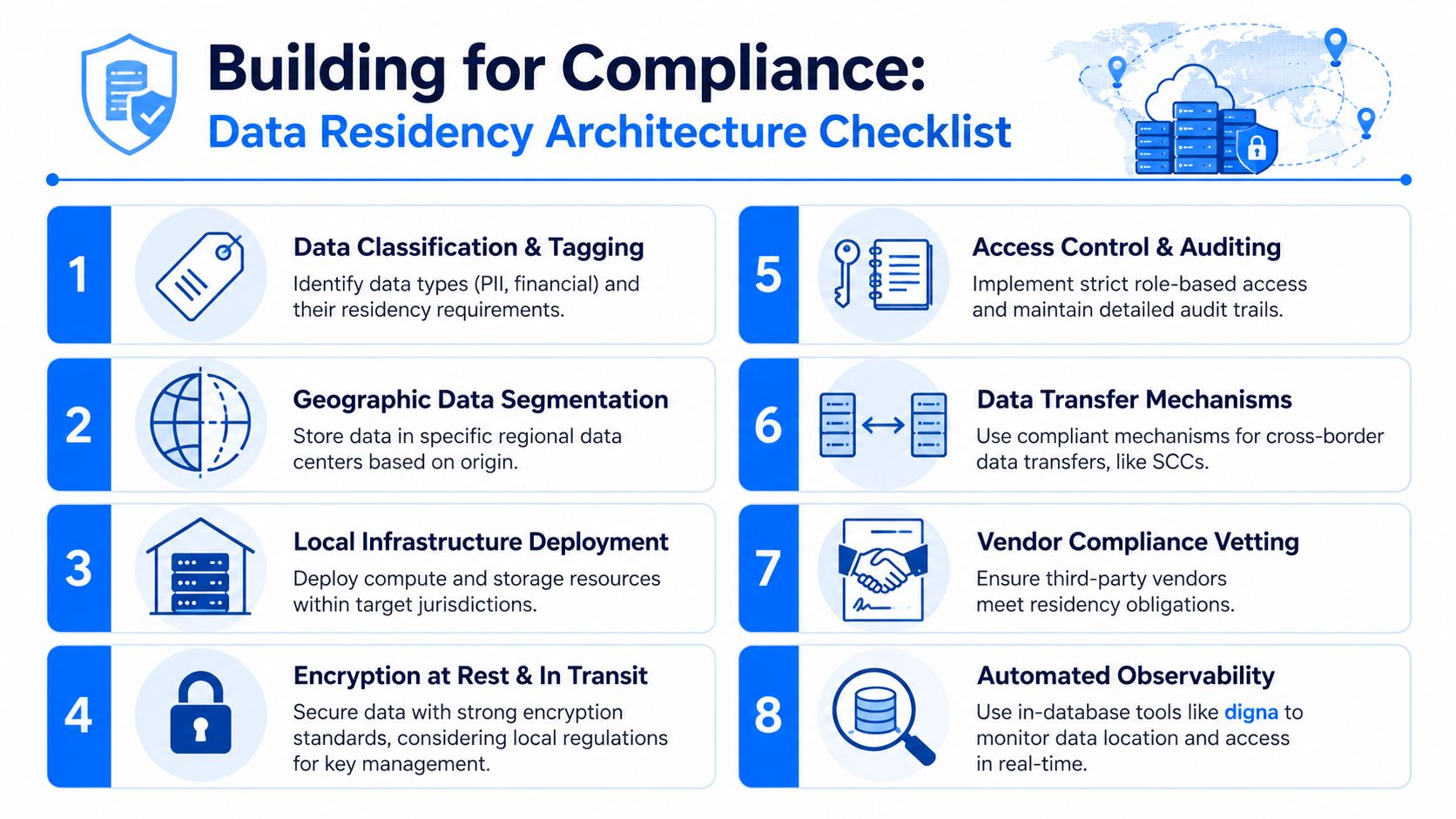
Design for every copy not just the primary copy
Engineers often secure the database and forget the surrounding system.
Residency-compliant design usually includes the following patterns:
Regional isolation: Separate storage, compute, and pipeline execution by jurisdiction instead of centralizing everything and hoping policy catches up.
Location-aware routing: Send user data to the correct regional path at ingestion time.
Region-locked backups: Keep snapshots, replicas, and disaster recovery targets inside the approved boundary.
Controlled analytics: Avoid tools that extract or mirror data into unmanaged SaaS environments.
Restricted test data usage: Don't refresh lower environments with production data unless those environments follow the same residency rules.
Local key control: Match encryption strategy to jurisdictional requirements and vendor exposure.
What usually doesn't work is a hybrid compromise where production is regional but all “operational” services remain global. Logs, monitoring, model training workspaces, and support tooling can undo the design.
Backups are where many residency architectures tell on themselves. Teams document the primary region, then discover the recovery policy was global by default.
Use an operating checklist teams can follow
Residency controls need to survive normal platform changes. A working checklist helps more than a policy PDF.
Audit deployments regularly: New services, managed features, and cloud defaults can introduce cross-region replication.
Pin processing jobs explicitly: Don't assume serverless or managed compute will stay local without clear constraints.
Review vendor data paths: Ask where telemetry, metadata, support artifacts, and temporary processing occur.
Test failover plans: A disaster recovery drill should prove that the recovery region is compliant, not just available.
Watch temporary exports: CSV downloads, notebook extracts, and ad hoc file transfers are common weak points.
Record evidence continuously: Region settings, audit trails, and flow diagrams should stay current enough for review.
A practical architecture also needs observability. If teams can't see where data moved, they won't catch violations early. That's where lineage, storage telemetry, access logs, and pipeline-level monitoring become useful as control mechanisms rather than just debugging tools.
Ensuring Residency with In-Database Data Observability
Observability tooling can help with residency, but it can also break it.

Why observability tooling can create the problem
A common pattern in SaaS monitoring is simple: collect metadata, query results, samples, logs, or schema details and send them to the vendor's cloud for analysis. That can be operationally convenient, but it creates a residency question immediately. Even if the source tables remain in-region, the monitoring layer may export enough information to create compliance exposure.
This is one reason teams need to understand the difference between data observability and data quality. The tooling category matters less than the execution model. If the platform depends on moving data or metadata out of your controlled environment, residency review gets harder.
What changes with in-database execution
An in-database approach changes the risk profile. Analysis runs inside the customer-controlled environment, whether that's private cloud or on-prem, and the platform interface surfaces results without requiring the vendor to access production datasets.
That model fits residency-sensitive environments because it reduces data movement by design.
In practical terms, teams should look for tooling that supports:
Capability | Why it matters for residency |
|---|---|
In-environment execution | Keeps checks and metric computation inside the approved boundary |
Private deployment options | Avoids shipping operational data into a vendor-managed SaaS region |
Schema and pipeline monitoring | Detects changes that can trigger unintended transfers or downstream misuse |
Audit-friendly outputs | Gives teams evidence for reviews, customer questionnaires, and incident analysis |
One example is digna, which provides anomaly detection, validation, timeliness monitoring, analytics, and schema tracking while executing analyses inside customer databases in private cloud or on-prem environments. That architecture is useful when the goal is visibility without exporting operational data to a separate control plane.
Good residency tooling doesn't just report where the primary data lives. It helps prove that monitoring itself isn't creating a side channel out of the jurisdiction.
The deeper point is architectural. If residency is about controlling data motion, then observability should follow the same rule set as storage and processing. Otherwise the compliance gap just moves from the pipeline to the monitoring stack.
Data Residency Is an Ongoing Discipline Not a Switch
Data residency isn't a setting you enable once and forget. It's an operating discipline that has to hold across ingestion, storage, processing, backup, recovery, analytics, and tooling.
The teams that handle it well don't ask only where the database is. They ask where every meaningful copy can appear, who can access it, what automation can move it, and how they'll prove control during an audit or customer review.
That changes the way you design platforms. Residency becomes part of architecture review, vendor procurement, pipeline deployment, and disaster recovery testing. In mature environments, it sits next to security and reliability as a standard engineering concern.
If you're still treating it as a legal appendix, you're already behind. If you treat it as a full-lifecycle system property, it becomes manageable.
If your team needs data quality and observability without exporting production data outside your controlled environment, digna is worth evaluating. Its in-database execution model fits organizations that need monitoring, anomaly detection, validation, and pipeline visibility while keeping data resident in private cloud or on-prem infrastructure.



