Robuste Data-Science-Pipelines: Erstellen, Bereitstellen, Überwachen
|
6
min. Lesezeit

Sie haben es im Moment wahrscheinlich mit einer von zwei Situationen zu tun. Entweder verhält sich ein Modell in der Produktion plötzlich merkwürdig, und niemand kann sagen, ob das Problem in der Feature-Logik, den Quelldaten oder einer verspäteten Bereitstellung im Upstream-Bereich liegt. Oder Ihr Team verfügt über eine Pipeline, die an den meisten Tagen „funktioniert“, bei der sich aber jedes Release riskant anfühlt, weil eine einzige Schemaänderung, eine fehlende Partition oder eine fehlerhafte Datei nachgelagerte Ergebnisse verfälschen kann.
So sehen Data-Science-Pipelines in der Produktion aus. Der schwierige Teil ist normalerweise nicht das Trainieren eines Modells. Es geht vielmehr darum, den Datenfluss über Ingestion, Transformation, Feature-Erstellung, Deployment und fortlaufendes Monitoring hinweg vertrauenswürdig zu halten. Teams, die sich nur auf die Definition von Abläufen konzentrieren, müssen dies auf die harte Tour lernen. Ein fehlerfreier Arbeitsablauf (DAG) garantiert keine validen Daten, und ein erfolgreich ausgeführter Job garantiert keine nützlichen Modelleingaben.
Inhaltsverzeichnis
Warum Data-Science-Pipelines das Rückgrat moderner KI sind
Viele KI-Fehler beginnen nicht mit schlechter Modellierung. Sie beginnen mit einer Pipeline, die unvollständige Features, duplizierte Datensätze, veraltete Aggregate oder falsch gelabelte Trainingsdaten geliefert hat. Die Schuld wird dem Modell zugeschoben, weil es sichtbar ist. Die Pipeline entgeht der Aufmerksamkeit, weil sie unter Schedulern, Skripten, Konnektoren und Warehouse-Jobs vergraben ist.
Deshalb betrachte ich Data-Science-Pipelines als Infrastruktur und nicht als bloßes Projekt-Bindeglied. Sie speisen Experimente, Trainings-Jobs, Batch-Scoring, Online-Inferenz-Features, Dashboards und Retraining-Schleifen. Wenn sie abweichen, ist jeder nachgelagerte Konsument von den Folgeschäden betroffen.

Das wirtschaftliche Signal ist eindeutig. Der weltweite Markt für Daten-Pipelines wird im Jahr 2024 auf 10,01 Milliarden USD geschätzt und soll bis 2032 einen Wert von 43,61 Milliarden USD erreichen – bei einer jährlichen Wachstumsrate (CAGR) von 19,9 %, wobei 90 % der KI- und Machine-Learning-Projekte direkt von diesen Pipelines abhängen, so der Bericht von Fortune Business Insights über den Daten-Pipeline-Markt. Teams investieren nicht in Pipeline-Infrastruktur, weil es modern ist. Sie tun es, weil KI-Systeme ohne solide Datenfundamente nicht überleben können.
Was in realen Umgebungen schiefgeht
Die offensichtlichen Fehler sind leicht zu erkennen. Ein Task stürzt ab. Eine Datei kommt nie an. Bei einer Verbindung kommt es zu einem Timeout.
Die gefährlichen Fehler sind stiller Natur:
Aktualitätsdrift (Freshness Drift), bei dem tägliche Daten immer später eintreffen
Semantische Drift, bei der ein Feld zwar noch existiert, sich seine Bedeutung aber im Upstream geändert hat
Verteilungsdrift (Distribution Drift), bei dem Werte innerhalb der Typgrenzen bleiben, sich aber außerhalb des Normalverhaltens bewegen
Teilerfolge, bei denen eine Pipeline zwar Ausgabedaten schreibt, aber nur für einen Teil des erwarteten Umfangs
Praxistipp: Wenn Ihr einziges Statussignal der Erfolg eines Jobs ist, überwachen Sie nicht die Pipeline. Sie überwachen den Scheduler.
Zuverlässige Data-Science-Pipelines müssen jeden Tag zwei Fragen beantworten. Sind die Jobs gelaufen? Und haben sie Daten geliefert, die immer noch für das Training, das Scoring und die Entscheidungsfindung geeignet sind?
Das Konzept der Data-Science-Pipeline entschlüsseln
Das anschaulichste mentale Modell ist ein Fabrik-Fließband. Rohmaterialien treffen von verschiedenen Lieferanten ein. Jede Station reinigt, formt um, prüft, reichert an oder setzt etwas zusammen. Am Ende wollen Sie keinen Haufen Einzelteile. Sie wollen ein fertiges Produkt, dem Sie vertrauen können.
Eine Data-Science-Pipeline funktioniert genauso. Sie übernimmt Rohdaten aus Anwendungen, Logs, Dateien, APIs, Event-Sreams und Warehouse-Tabellen. Anschließend verwandelt sie diese Daten in Trainingssets, Features, Vorhersagen und überwachte Ausgaben, die von anderen Systemen genutzt werden können.
Mehr als ETL
Ein einfacher ETL-Job verschiebt und transformiert Daten. Das ist wichtig, aber es ist nur ein Teil des Ganzen. Data-Science-Pipelines fügen in der Regel Schritte hinzu, die Standard-Analytics-Pipelines nicht vollständig abdecken:
Feature-Erstellung für modellbereite Inputs
Erzeugung von Trainings- und Validierungsdatensätzen
Reproduzierbarkeit von Experimenten
Modell-Paketierung und -Deployment
Feedback-Schleifen nach dem Deployment
Dieser Unterschied ist im Betrieb von großer Bedeutung. Ein fehlerhafter BI-Bericht ist ärgerlich. Eine fehlerhafte Pipeline für Modelleingaben kann sich dagegen – je nach Branche – direkt auf Rankings, Betrugsprüfungen, Prognosen, Triage-Prozesse oder klinische Prüfungsabläufe auswirken.
Script versus Produktions-Pipeline
Data-Science-Projekte beginnen oft mit einem Notebook oder einem Python-Skript. Das ist völlig normal. Aber genau hier nehmen auch viele Zuverlässigkeitsprobleme ihren Anfang.
Ein einmaliges Skript kann für die reine Erkundung wunderbar sein. Als Produktionssystem taugt es jedoch meist wenig, da es oft von lokalen Voraussetzungen ausgeht:
Szenario | Was passiert |
|---|---|
Notebook-Workflow | Pfade, Anmeldedaten, Paketversionen und Stichprobenauswahlen existieren nur in der Umgebung einer einzelnen Person |
Produktions-Pipeline | Inputs, Outputs, Abhängigkeiten, Retries, Tests, Lineage und Zuständigkeiten sind explizit definiert |
Produktionstaugliche Data-Science-Pipelines erfordern Wiederholbarkeit. Wenn derselbe Input morgen wieder eintrifft, sollte das System dieselbe Logik mit kontrollierten Änderungen, bekannten Abhängigkeiten und beobachtbaren Ergebnissen ausführen. Das bedeutet in der Regel, dass Tools wie Airflow, Dagster, Prefect, Spark, dbt, Warehouse-natives SQL, CI-Pipelines und Modellbereitstellungs-Infrastruktur zusammenarbeiten, anstatt auf einen einzigen All-in-One-Infrastruktur-Stack zu setzen.
Eine Pipeline ist nicht ausgereift, nur weil sie automatisiert ist. Sie ist ausgereift, wenn ein anderer Ingenieur sie sicher anpassen kann und sofort erkennt, ob das Ergebnis noch vertrauenswürdig ist.
Das ist der Maßstab, den man anstreben sollte.
Die sieben Kernphasen einer Data-Science-Pipeline
Die meisten Produktionssysteme sehen im Detail chaotisch aus, aber der Lebenszyklus bleibt konsequent gleich. Wenn Teams ein gemeinsames Vokabular für die einzelnen Phasen teilen, wird das Debugging einfacher und die Zuständigkeiten werden klarer.
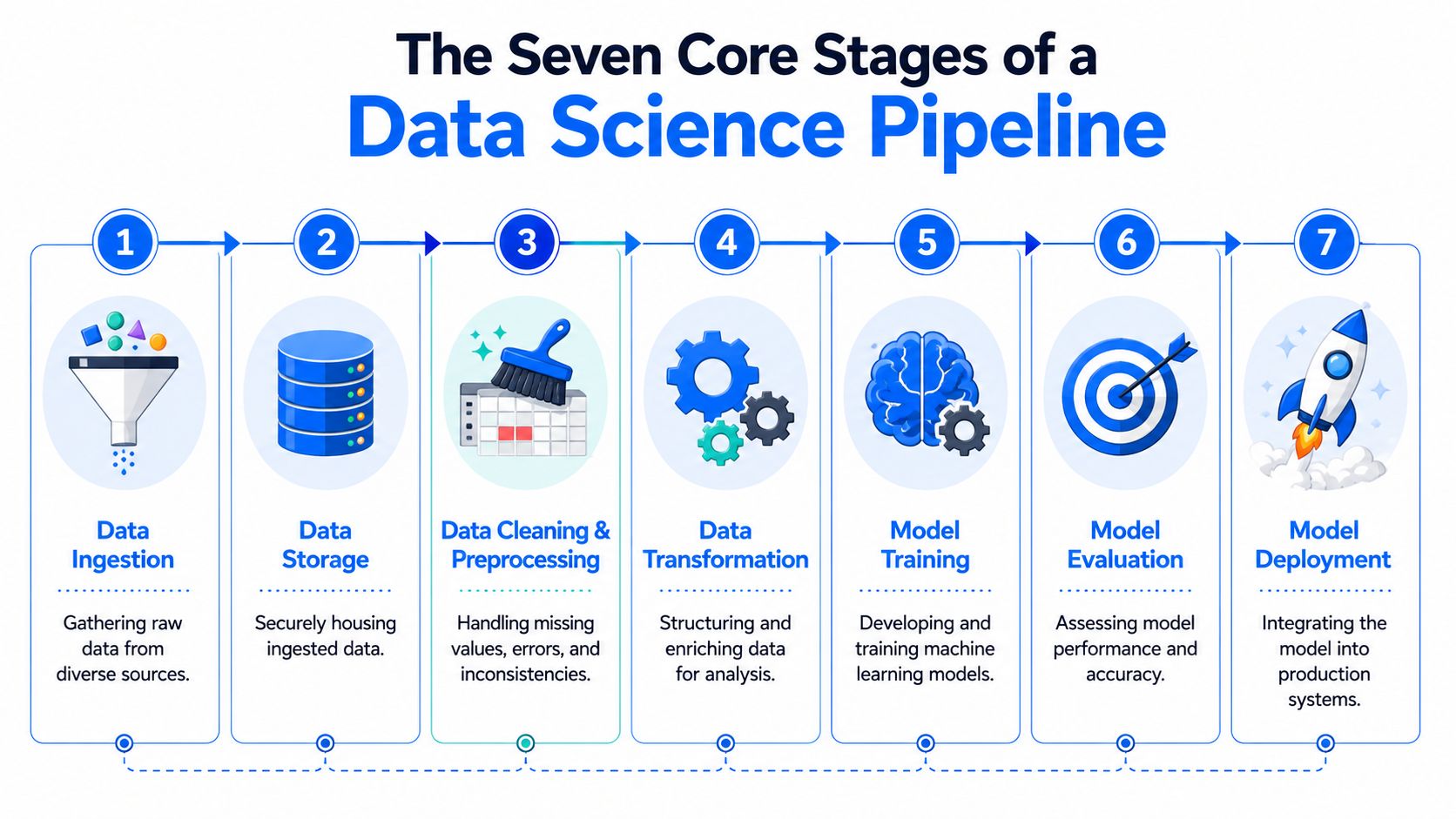
Daten-Ingestion
Die Pipeline trifft auf die Realität, sobald Daten eintreffen. Daten stammen aus OLTP-Datenbanken, SaaS-Tools, CDC-Streams, Objektspeichern, Applikations-Logs und APIs. Einige Quellen sind strukturiert und stabil. Andere wiederum nicht.
Die wichtigste Entscheidung an dieser Stelle lautet: Batch-Verarbeitung, Streaming oder beides. Die Batch-Verarbeitung ist einfacher zu begreifen und erleichtert das nachträgliche Befüllen (Backfill). Streaming unterstützt Anwendungsfälle mit geringer Latenzzeit, legt die Latte für Sortierung, Deduplizierung, spät eintreffende Events und das Handling von Checkpoints jedoch deutlich höher.
Zu den gängigen Tools gehören Kafka, Pub/Sub, Kinesis, Airbyte, Fivetran, benutzerdefinierte Konnektoren und direkte Warehouse-Ingestion-Jobs.
Datenspeicherung und -integration
Sobald die Daten eingegangen sind, benötigen sie einen dauerhaften Speicherort und eine Struktur, auf die sich nachgelagerte Konsumenten verlassen können. Teams treffen an dieser Stelle Entscheidungen bezüglich ETL oder ELT, definieren Roh- und kuratierte Datenschichten und legen fest, was an Transformationen in Spark-Jobs und was in SQL-Modellen geschehen soll.
Diese Phase liefert in der Regel Folgendes:
Rohdaten-Landezonen (Raw Landing Zones) für Replays und Audits
Konforme Datensätze (Conformed Datasets) zur gemeinsamen Nutzung
Integrierte Feature-Inputs über unterschiedliche Bereiche hinweg, wie Kunden-, Produkt-, Schadens- oder Gerätedaten
Eine gute Integrationsschicht bewahrt genügend Details der Rohdaten für eine erneute Verarbeitung auf und bietet nachgeschalteten Nutzern gleichzeitig stabile Schnittstellen.
Bevor wir uns mit den späteren Phasen beschäftigen, hilft es, eine praktische Kontrollinstanz einzuführen. Konsequente Datenvalidierungspraktiken für Produktions-Pipelines verhindern, dass offensichtliche Fehler ungehindert weiter nachgelagert übertragen werden.
Datenverarbeitung und Feature-Engineering
Viele Pipelines entwickeln sich domänenspezifisch, da Teams fehlende Werte behandeln, Kategorien kodieren, historische Zeitreihenmerkmale (Lagged Features) erstellen, Ereignisse in Zeitfenstern aggregieren, Kennzahlen berechnen und Verhaltensdaten mit Stammdaten zusammenführen.
Die Feature-Logik beginnt oft in Notebooks und wird später in SQL-, Spark- oder Python-Transformationen fest verankert. Das typische Fehlermuster ist vorhersehbar: Die Logik wird über Trainings- und Inferenzpfade hinweg kopiert und weicht dann voneinander ab. Die Lösung ist ebenso absehbar: Feature-Definitionen zentralisieren und versionieren.
Einige Best Practices haben sich bewährt:
Trennen Sie die Rohdaten-Bereinigung von der Geschäftslogik
Halten Sie Feature-Definitionen nah an den Tests
Konzipieren Sie Transformationen so, dass sie idempotent sind
Dokumentieren Sie die für jeden Trainingslauf verwendete Datenversion
Hier ist die Übersicht für den gesamten Lebenszyklus:
Modell-Training und -Tuning
Das Training nutzt die verarbeiteten Datensätze und macht daraus Modellkandidaten. Die technischen Details variieren je nach Technologie-Stack. Einige Teams nutzen scikit-learn auf Warehouse-Exporten. Andere setzen Spark ML, XGBoost, PyTorch, TensorFlow oder Plattformen für Managed ML ein.
Im operativen Alltag geht es nicht nur um Hyperparameter-Tuning. Es geht um Reproduzierbarkeit. Wenn ein Modell im nächsten Monat eine schlechtere Leistung zeigt, müssen Sie wissen, welche Codeversion, welches Feature-Set, welcher Trainingsausschnitt und welche Parameter es hervorgebracht haben.
Modell-Validierung und -Auswahl
In dieser Phase wird entschieden, welche Modelle für die Produktion infrage kommen. Teams vergleichen Modellkandidaten mit Holdout-Daten, geschäftlichen Einschränkungen, Anforderungen an die Erklärbarkeit und operativen Limits wie Inferenzlatenz oder Speichernutzung.
Die Validierung sollte über reine Modellmetriken hinausgehen. Es sollte auch geprüft werden, ob die zugrunde liegenden Daten den Zielprozess noch zutreffend abbilden. Ein hoch bewertetes Modell, das auf instabilen Inputs trainiert wurde, kann in der Produktion dennoch versagen.
Der beste Modellkandidat ist nicht unbedingt derjenige mit dem besten Offline-Score, sondern derjenige, den Ihre Plattform auch sicher und stabil unterstützen kann.
Modell-Deployment
Das Deployment verwandelt ein Artefakt in einen Service oder einen geplanten Scoring-Prozess. Typische Muster sind das Batch-Scoring in eine Warehouse-Tabelle, Real-Time-Inferenz hinter einer API oder hybride Setups, bei denen ein Echtzeit-Dienst vorberechnete Features abruft.
Diese Phase benötigt klare Vereinbarungen (Contracts):
Deployment-Szenario | Was zu definieren ist |
|---|---|
Inputs | Erforderliche Felder, Datentypen, Umgang mit Nullwerten und Aktualitätserwartungen |
Outputs | Vorhersageschema, Konfidenzintervalle und Speicherort |
Rollback | Vorherige Modellversion, Auslösebedingungen und Wiederherstellungspfad |
Monitoring und Retraining
Die Pipeline endet nicht mit dem Deployment. Das Produktionsmonitoring muss die Service-Stabilität, Aktualität der Features, Schemastabilität, Datenqualität und Retraining-Trigger abdecken.
Ein Retraining sollte auf konkreten Anlässen basieren und nicht einfach, weil es ein geplanter Cron-Job so vorgibt. In ausgereiften Systemen sind Retraining-Entscheidungen an beobachtete Abweichungen (Drift), geänderte Geschäftskontexte oder Feedback zur Modellleistung gekoppelt. Anderenfalls erzeugen die Teams nur unnötigen Berechnungsaufwand.
Integration von Pipelines mit Data Warehouses und Lakes
Data-Science-Pipelines entstehen meist nicht isoliert von anderen Systemen. Sie bauen auf Warehouse-Tabellen, Lake-Speichern oder einer Kombination aus beidem auf. Diese Architekturentscheidung beeinflusst Latenzzeiten, governance, die Geschwindigkeit beim Experimentieren sowie den Umfang der zu wartenden, duplizierten Logik.

Warehouse-First-Muster
Warehouses eignen sich am besten, wenn Ihre Inputs bereits weitgehend strukturiert sind und das Unternehmen kontrollierte, abfragbare Datensätze benötigt. Snowflake, BigQuery, Redshift und ähnliche Systeme sind immer dann eine gute Wahl, wenn sich Analytics Engineering und ML-Feature-Generierung dieselben kuratierten Tabellen teilen sollen.
Bei diesem Ansatz wird das Warehouse in der Regel zur einzigen Quelle der Wahrheit (Source of Truth) für:
Standardisierte Entitäten wie Kunden, Konten, Anbieter oder Händler
Kuratierte Features, die teamübergreifend wiederholt verwendet werden
Modellergebnisse (Outputs), die für BI-Nutzung und operative Berichte zurückgeschrieben werden
Ein Warehouse-First-Setup erleichtert die governance. Schemaverträge, SQL-basierte Transformationen, Zugriffskontrollen und Auditierbarkeit sind hier meist klarer geregelt als in Ad-hoc-Dateisystemen. Diese Struktur eignet sich auch hervorragend für Teams, die eine Migrationsstrategie vom Warehouse zum Data Lake für gemischte Workloads planen.
Lake-First-Muster
Lakes sind die bessere Wahl, wenn Teams Flexibilität im Umgang mit Rohdateien, semistrukturierten Daten, Protokollen, Dokumenten oder großen Datensätzen für Experimente benötigen. Sie ermöglichen es Data Scientists, Details direkt auf Quellebene zu untersuchen, ohne jedes Signal zu früh in ein starres Warehouse-Schema pressen zu müssen.
Dies eignet sich hervorragend für Anwendungsfälle wie:
Ereignisintensive Feature-Generierung
Modellentwicklung auf Basis von rohen Telemetriedaten
Pipelines für Text-, Bild- oder Dokumentendaten
Erneute Verarbeitung historischer Daten nach Änderungen an der Feature-Logik
Der Preis dafür ist die operative Disziplin. Lakes bieten zwar Freiheit, führen aber auch leichter zu uneinheitlichen Formaten, duplizierten Datenbeständen und unklaren Zuständigkeitsgrenzen.
Was in gemischten Umgebungen funktioniert
Die meisten Unternehmen landen schließlich bei einem Hybridmodell. Rohdaten und große Datenmengen landen in einem Lake. Kuratierte, kontrollierte und geschäftskritische Ausgaben liegen im Warehouse. Die Pipeline bewegt sich agil zwischen beiden Welten.
In der Praxis sieht diese Aufteilung oft so aus:
Schicht (Layer) | Optimaler Einsatz |
|---|---|
Lake | Rohdaten-Ingestion, Replay, Experimente und großflächige Zwischenverarbeitung |
Warehouse | Verlässliche Dimensionen, kuratierte Fakten, wiederverwendbare Features und nachgelagerte Berichterstattung |
Pipeline-Logik | Datentransfer, Transformation, Validierung und Bereitstellung zwischen den beiden Schichten |
Sorgen Sie für experimentelle Freiheit im Upstream-Bereich. Gewährleisten Sie verlässliche Datennutzung für das Business im Downstream-Bereich.
Diese Trennung beugt einem häufigen Fehler vor: Teams versuchen entweder zu früh, alles in das Warehouse zu zwingen, was das Experimentieren verlangsamt, oder sie belassen zu viel im Lake, was nachgelagerte Analysen und die Einhaltung von Compliance-Vorgaben unnötig erschwert.
Über die Orchestrierung hinaus: Datenqualität und Observability
Ein Scheduler kann Ihnen lediglich bestätigen, dass Tasks ausgeführt wurden. Er kann Ihnen jedoch nicht sagen, ob die Datensätze fehlerfrei waren, ob ein kritisches Feld plötzlich nahezu konstante Werte aufwies oder ob Upstream-Datenlieferanten die geschäftliche Bedeutung geändert haben, während das technische Schema unverändert blieb.
Genau aus diesem Grund reicht Orchestrierung allein nicht aus.

Wie lautlose Fehler aussehen
Der operative Aufwand ist oft größer, als viele Teams zugeben wollen. Daten-Pipelines kämpfen mit anhaltender Instabilität, wobei wöchentlich 30 % bis 40 % der Pipelines ausfallen. Diese Ausfälle führen im Durchschnitt zu 67 Datensicherheitsvorfällen pro Monat und Unternehmen, wobei die Behebung jedes einzelnen Vorfalls etwa 15 Stunden in Anspruch nimmt, so die Zusammenfassung von Folio3 zur Datentechnik-Statistik.
Diese Zahlen beschreiben nur die sichtbaren Störungen. In der Praxis handelt es sich bei einigen der schwerwiegendsten Ausfälle keineswegs um offensichtliche Systemabstürze. Es sind schleichende Qualitätsverluste:
Eine Quelle liefert plötzlich leere Zeichenfolgen statt Nullwerten
Ein Enum erhält eine neue Kategorie, die von der nachgelagerten Logik einfach ignoriert wird
Ein Zeitstempel kommt in einem unerwarteten Zeitzonenformat an
Eine Feature-Verteilung ändert sich so langsam, dass statische Schwellenwert-Regeln nicht anschlagen
Wenn dies in ML-Systemen passiert, liefert das Modell zwar weiterhin wie gewohnt Vorhersagen, aber das Vertrauen in die Ergebnisse schwindet unbemerkt.
Die vier entscheidenden Signale
Teams benötigen eine zentrale Betriebsansicht, die Qualität und Observability kombiniert, anstatt sie auf nicht miteinander verbundene Tools und Dashboards aufzuteilen. Ich stufe diese vier Signale als unverzichtbar ein.
Datenqualität
Hier geht es um die Korrektheit der Daten auf Datensatzebene. Sind Pflichtfelder ausgefüllt? Entsprechen die Werte den Geschäftsregeln? Sind Fremdschlüssel korrekt zugeordnet? Weisen berechnete Felder interne Konsistenz auf?
Explizite Validierungen sind hierbei am wichtigsten. Qualitätstests sollten sich nah an den Daten befinden, die sie schützen sollen, und nicht nur im Applikationscode oder in nachgelagerten Notebooks.
Aktualität (Timeliness)
Frische Daten, die zu spät eintreffen, stellen im Betrieb immer noch ein Problem dar. Die Überwachung der Aktualität sollte erwartete Eingangsmuster, verzögerte Partitionen, unvollständige Ladevorgänge und verspätete Upstream-Updates erfassen.
In Batch-Umgebungen bedeutet dies meist zeitgesteuerte Prüfungen. Bei Event-Pipelines bedeutet es die Überwachung von Ingestion-Lag und unstrukturierten Abläufen.
Schemastabilität (Schema Integrity)
Ein Schemabruch ist offensichtlich, wenn eine Spalte fehlt und ein Job abstürzt. Der schwierigere Fall ist eine additive oder typnahe Änderung, die nicht sofort zum Absturz führt, aber dennoch die Bedeutung verändert. Teams sollten auf hinzugefügte Spalten, gelöschte Spalten, Typänderungen und schleichende Veränderungen bei Datenvereinbarungen auf Feldebene achten.
Anomalieerkennung (Anomaly Detection)
Feste Regeln decken bekannte Probleme auf. Die Anomalieerkennung fängt unerwartete Veränderungen bei Volumen, Verteilung, Mustern und Trends ab. Man benötigt zwingend beides.
Ein sinnvoller Vergleich sieht folgendermaßen aus:
Signalart | Stärken bei | Schwächen bei |
|---|---|---|
Statische Regeln | Plötzliche Peaks bei Nullwerten, ungültige Wertebereiche, Formatverletzungen | Neue Driftmuster, die Sie nicht vorhergesagt haben |
Anomalieerkennung | Unerwartete Verhaltens- und Verteilungsänderungen | Explizite betriebliche Logikfehler, sofern nicht eigens kodiert |
Für Teams, die beide Ansätze vergleichen möchten, ist dieser Leitfaden über Data Observability versus Datenqualität in der Praxis ein hilfreicher Ratgeber, da er beide Konzepte als komplementäre Steuerungsmechanismen und nicht als konkurrierende Kategorien begreift.
Warum einheitliches Monitoring Werkzeug-Wildwuchs schlägt
Fragmentierte Setups verursachen oft ihre ganz eigenen Probleme. Ein Tool überwacht die Aktualität. Ein anderes prüft das Schema. Ein drittes führt Validierungen durch. Ein viertes verschickt Alerts. Ingenieure verbringen dann wertvolle Zeit damit, widersprüchliche Signale abzugleichen und Zuständigkeiten systemübergreifend zu klären.
Was deutlich besser funktioniert, ist ein einheitliches Betriebsmodell:
Ein zentraler Ort, um den Zustand über alle Pipeline-Schritte hinweg zu prüfen
Eine gemeinsame Incident-Ansicht, die Aktualität, Schema, Qualität und Anomalien verknüpft
Ein klares Zuständigkeitsmodell für Eskalation und Fehlerbehebung
Ein lückenloser Audit-Trail, aus dem hervorgeht, was sich wann geändert hat
Wenn ein Ingenieur vier Dashboards benötigt, um eine einzige fehlerhafte Vorhersage zu erklären, ist das Monitoring-Design selbst bereits Teil des Problems.
In Private-Cloud- und On-Premises-Umgebungen wiegt diese Konsolidierung umso schwerer, da sich Teams dort oft nicht auf voll verwaltete, Cloud-native Monitoring-Dienste verlassen können. Sie benötigen Tools, die sich in die Grenzen des Unternehmens einfügen, ohne zusätzlichen Datenfluss über Drittsysteme zu erzwingen.
Überlegungen zu On-Premises- und Private-Cloud-Pipelines
On-Premises- und Private-Cloud-Umgebungen verschieben die Design-Prioritäten. Die üblichen Ratschläge für die Public Cloud lassen sich nicht immer einfach übertragen, wenn die Daten das eigene Netzwerk nicht verlassen dürfen, Beschaffungszyklen länger sind und Sicherheitsprüfungen strenger ausfallen.
Das macht leistungsstarke Data-Science-Pipelines im Grunde nicht schwieriger. Es bedeutet lediglich, dass die Architektur von Anfang an die lokalen Einschränkungen berücksichtigen muss.

Sicherheits- und Architektur-Einschränkungen
In regulierten Märkten fordern Teams meist, dass Berechnungen dort stattfinden, wo die Daten bereits liegen. Das minimiert Sicherheitsrisiken, vermeidet unnötige Datenkopien und vereinfacht die governance-Prüfung. In der Praxis führt dies oft zu In-Database-Transformationen, lokaler Metrikberechnung, datenbanknaher Validierung und kontrollierten Servicegrenzen für das Modell-Training oder die Inferenz.
Die wesentlichen Architekturfragen sind pragmatischer Natur:
Kann diese Komponente laufen, ohne sensible Daten nach außen zu exportieren?
Können Sicherheits-Teams auditieren, wer worauf zugegriffen hat?
Können Plattform-Teams die Komponente mit den bestehenden Werkzeugen betreiben und patchen?
Kann die Pipeline sicher abgefangen werden, wenn eine Abhängigkeit wegbricht?
Offene Formate, explizite Rahmenverträge und minimaler Datenfluss erweisen sich hierbei als äußerst wertvoll.
Kapazitätsplanung und Gesamtkosten
On-Premises-Teams können Performance-Engpässe nicht einfach per Mausklick auf „Schnittstelle skalieren“ lösen. Die Kapazitätsplanung spielt frühzeitig eine Rolle und muss auf realistischen Arbeitslasten basieren. Die Empfehlungen von Google zum Benchmarking von Dataflow-Jobs mit Durchsatz pro vCPU-Kern sind hierbei hilfreich, da sie das Testen mit realistischen Datentypen, Datenmengen, Netzwerkverhalten sowie echten Quellen- und Zielbedingungen anstelle von idealisierten Labor-Benchmarks betonen.
Bei der Kostenbewertung muss auch das Verhalten im Fehlerfall berücksichtigt werden. Wie Databricks in seinem Leitfaden zur Bewertung des Pipeline-Kosten-Leistungs-Verhältnisses erklärt, gehören sowohl die gesamten Rechenkosten als auch die Fehlerquoten in diese Kalkulation, da häufige Job-Ausfälle eine erneute Datenverarbeitung erzwingen und die Wertschöpfung verzögern.
Was in Unternehmensumgebungen standhält
Die robustesten Muster, die ich in Enterprise-Umgebungen gesehen habe, überzeugen vor allem durch schlichte Zuverlässigkeit statt durch Experimente. Sie setzen auf Vorhersehbarkeit statt auf modische Trends.
Modulare Services: Halten Sie Ingestion, Transformation, Validierung und Bereitstellung lose gekoppelt, damit ein einziger Fehler nicht gleich das gesamte System lahmlegt.
Deterministische Backfills: Führen Sie die Logik für ein definiertes Zeitfenster mit demselben Code und einer klaren Zuordnung (Lineage) erneut aus.
Lokale Observability: Speichern Sie Statussignale dort, wo Ihre Ingenieure sie prüfen können, ohne Sicherheitsgrenzen zu verletzen.
Explizite Zuständigkeit: Jede Pipeline, jede Tabelle und jeder Feature-Input benötigt ein klar definiertes Team, das für Vorfälle zuständig ist.
Zuverlässigkeit im Enterprise-Bereich entsteht in der Regel durch disziplinierte Abgrenzung und nicht durch komplexe Architekturdiagramme.
Private-Cloud- und On-Premises-Systeme belohnen Designs, die leicht überprüfbar, dokumentiert und zurückhaltend beim Verschieben von Daten sind. Dies gilt insbesondere dann, wenn KI-Pipelines von gemeinsamer Warehouse- und Lake-Infrastruktur abhängen, die von vielen Teams gleichzeitig genutzt wird.
Fazit: Aufbau Ihrer resilienten Pipeline-Strategie
Zuverlässige Data-Science-Pipelines sind weit mehr als nur terminierte Arbeitsabläufe. Sie bilden das Betriebssystem dafür, wie aus Rohdaten vertrauenswürdige Trainingssets, produktive Features, Modellergebnisse und geschäftliche Entscheidungen werden.
Die Erstellungsphase zieht meist die meiste Aufmerksamkeit auf sich. Die Betriebsphase entscheidet jedoch darüber, ob die Pipeline auch dauerhaft Mehrwert liefert. Genau hier scheitern viele Teams. Sie automatisieren zwar den Datenfluss, aber nicht das Vertrauen darin. Sie überwachen laufende Tasks, aber nicht die Datenqualität. Sie fügen neue Tools hinzu, schaffen aber keine Klarheit.
Eine wirksamere Strategie ist in der Theorie einfacher formuliert als umgesetzt: Etablieren Sie klare Phasen. Richten Sie Speicher- und Serving-Konzepte an den tatsächlichen Workloads aus. Behandeln Sie Datenqualität, Aktualität, Schemastabilität und Anomalieerkennung als eine einheitliche operative Disziplin. Halten Sie Berechnungen in Private-Cloud-Umgebungen nah an den Daten und führen Sie Benchmarks unter realistischen Bedingungen durch.
Der beste nächste Schritt ist meist kein neues Plattformprojekt auf der grünen Wiese. Er besteht vielmehr darin, die geschäftskritischste Pipeline zu auditieren, die Sie bereits im Einsatz haben. Prüfen Sie, an welchen Stellen sie unbemerkt ausfallen kann. Analysieren Sie, wie schnell Ihr Team fehlerhafte Ausgaben erklären kann. Und prüfen Sie, ob Observability und Datenqualität derzeit noch auf zu viele unterschiedliche Systeme verteilt sind.
Wenn Sie nach einem praktischen Weg suchen, um Anomalieerkennung, Validierung auf Datensatzebene, Aktualitäts-Monitoring und Schema-Tracking in einer Ansicht zu bündeln, ohne Daten aus Ihrer geschützten Umgebung zu bewegen, werfen Sie einen Blick auf digna. Es wurde speziell für Teams entwickelt, die Modern Data Quality und Observability direkt in ihren eigenen Datenbanken, in einer Private Cloud oder in ihrer On-Premises-Infrastruktur betreiben möchten.



