Data Lake vs. Data Mart: Treffen Sie die richtige Entscheidung für 2026
|
7
min. Lesezeit

Ihr Führungsteam wünscht sich schnellere Dashboards, sauberere KPIs und Raum für KI und maschinelles Lernen. Gleichzeitig hat es Ihr Datenteam mit Rohprotokollen, SaaS-Extraktion, operativen Datenbanken und Datei-Uploads zu tun, die nicht nach Zeitplan eintreffen. Genau an diesem Punkt wird die Entscheidung zwischen Data Lake und Data Mart meist stark vereinfacht dargestellt.
In der Praxis ist dies nicht nur eine Frage der Speicherung. Es ist eine Frage des Vertrauens. Ein Data Lake bietet Ihnen Flexibilität und Skalierbarkeit. Ein Data Mart bietet den Geschäftsteams Konsistenz und Schnelligkeit. Die Herausforderung liegt in dem, was dazwischen passiert. Wenn Sie Qualität, Lineage und die Erkennung von Änderungen nicht kontrollieren, wird der Lake zur Belastung und der Mart zu einer geschönten Ebene voller falscher Annahmen.
Für die meisten Organisationen, die eine Datenplattform der nächsten Generation planen, lautet die Schlüsselfrage nicht, welche Lösung universell besser ist. Sondern welche Rolle die jeweilige Lösung spielen soll und wie Sie den Weg von Rohdaten zu geschäftsbereiten Daten zuverlässig gestalten.
Inhaltsverzeichnis
Ein vertiefter Blick in die Architektur: Ein direkter Vergleich
Der kritische Pfad vom Lake zum Mart: Governance und Qualität
Was ist ein Data Lake und was ist ein Data Mart?
Ein Data Lake ist ein zentrales Repository für Rohdaten in vielen verschiedenen Formaten. Er kann strukturierte Tabellen, semistrukturierte Ereignisdaten, Anwendungsprotokolle, Dokumente und andere Quelldaten aufnehmen, bevor ein Team überhaupt endgültig entschieden hat, wie diese Daten modelliert oder abgefragt werden sollen. Der Leitgedanke ist Flexibilität. Sie speichern die Daten zuerst ab und formen sie erst später, wenn ein geschäftlicher oder analytischer Anwendungsfall klar erkennbar wird.
Ein Data Mart ist anders. Er ist eine kuratierte, zweckgerichtete Datenebene für einen bestimmten Bereich wie Finanzen, Vertrieb, Betrieb oder Kundensupport. Die Daten werden bereinigt, standardisiert, getestet und organisiert, bevor die Geschäftsteams sie nutzen. Der Leitgedanke ist Benutzerfreundlichkeit. Anwender sollten Quellsysteme nicht erst mühsam rekonstruieren müssen, um eine einfache Reporting-Frage zu beantworten.

Das einfachste mentale Modell
Stellen Sie sich den Data Lake wie ein Wasserreservoir vor. Es speichert große Mengen eingehenden Wassers in seinem ursprünglichen Zustand. Das ist dann wertvoll, wenn das Unternehmen Details bewahren, Data-Science-Arbeiten unterstützen oder Optionen für zukünftige Analysen offenhalten möchte.
Stellen Sie sich den Data Mart wie eine Abfüllanlage vor. Sie entnimmt ausgewähltes Wasser aus dem Reservoir, filtert es, prüft die Qualität, verpackt es und liefert es für einen bestimmten Zweck aus. Das ist dann wertvoll, wenn das Finanzwesen eine verbindliche Umsatzdefinition oder die Betriebsleitung ein zuverlässiges Service-Level-Dashboard benötigt.
Praktische Faustregel: Wenn Anwender die Freiheit brauchen, offene Fragen zu untersuchen, beginnen Sie näher am Lake. Wenn sie wiederholbare Antworten für einen definierten Prozess benötigen, beginnen Sie näher am Mart.
Warum die Unterscheidung für die Führungsebene wichtig ist
Führungskräfte hören oft, dass Lakes modern und Marts altmodisch seien, oder dass Marts starr und Lakes kostengünstig sind. Beide Darstellungen greifen zu kurz. Es zählt allein der geschäftliche Zweck, den die jeweilige Lösung erfüllt.
Ein Lake unterstützt die Breite. Hier bewahren die Entwicklerteams die Originalität der Quellen, binden neue Datenquellen schnell an und unterstützen explorative Analysen. Ein Mart unterstützt die Präzision. Hier definieren Governance-Teams die Geschäftslogik, stimmen Kennzahlen ab und reduzieren Hürden bei der Entscheidungsfindung.
Wenn Sie im Rahmen einer umfassenderen Plattform auch verwaltete relationale Dienste evaluieren, ist dieser RDS-Leitfaden für philippinische Unternehmen eine nützliche Referenz, um zu verstehen, wo operative Datenbanken neben analytischen Schichten ihren Platz finden. Transaktionssysteme, rohe Analysespeicher und kuratierte Analysemodelle lösen jeweils völlig unterschiedliche Probleme.
Wo Teams in Schwierigkeiten geraten
Der häufigste Fehler in der Diskussion um Data Lake vs. Data Mart ist die Annahme, der Lake sei nur eine Zwischenstation und der Mart lediglich für das Reporting da. Dabei wird die operative Last dazwischen übersehen. Rohe Flexibilität erfordert nachgelagerte Bereinigungsarbeit. Kuratierte Zugänglichkeit verlangt vorgelagerte Modellierungsdisziplin.
Teams, die einen Mittelweg suchen, werfen oft einen Blick auf den Lakehouse-Ansatz und Möglichkeiten zur Sicherung der Datenqualität, insbesondere wenn sie Redundanzen zwischen Rohdatenspeichern und analytischen Bereitstellungsebenen reduzieren wollen. Doch selbst dann gilt dieselbe architektonische Wahrheit: Rohdaten und vertrauenswürdige Geschäftsdaten sollten nicht mit demselben Qualitätsstandard behandelt werden.
Ein vertiefter Blick in die Architektur: Ein direkter Vergleich
Am klarsten lässt sich der Vergleich zwischen Data Lake und Data Mart anstellen, wenn man untersucht, wie sich beide unter realem operativem Druck verhalten.
Merkmal | Data Lake | Data Mart |
|---|---|---|
Datenstruktur | Roh, unterschiedliche Formate, oft minimal transformiert | Strukturiert, bereinigt, geschäftsbereit |
Schema-Ansatz | Schema-on-Read | Schema-on-Write |
Hauptzweck | Details bewahren und flexible Erkundung unterstützen | Konsistente Analysen für eine definierte Geschäftsfunktion liefern |
Typische Anwender | Data Engineers, Data Scientists, ML-Teams | Analysten, Finanzteams, BI-Anwender, geschäftliche Stakeholder |
Verarbeitungsstil | Oft ELT-orientiert | Oft ETL-orientiert vor der Nutzung |
Abfragemuster | Explorativ, batch-intensiv, unterschiedliche Workloads | Wiederkehrendes, wertvolles Reporting und Dashboard-Zugriffe |
Governance-Ansatz | Beim Ingest oft lockerer, bei entsprechender Reife später strenger | Vornherein strenger, da die Ergebnisse für Geschäftsentscheidungen gedacht sind |
Veränderungstoleranz | Höhere Toleranz gegenüber Abweichungen der Quelle | Geringere Toleranz, da Berichte stabil bleiben müssen |
Leistungserwartung | Gut für großvolumige Speicherung und Experimente | Besser geeignet für schnellen, fokussierten analytischen Konsum |
Kostenprofil | Speichereffizient, aber die operative Komplexität kann steigen | Höherer Aufwand für Transformation und Modellierung, aber klarerer Geschäftswert bei der Nutzung |
Flexibilität kontra Kontrolle
Ein Lake gewinnt, wenn das Unternehmen noch nicht jede zukünftige Frage kennt, die es stellen möchte. Produkttelemetrie, Clickstream-Ereignisse, Protokolle, Dokumente und Quellextrakte können alle einfließen, ohne dass sofortige Modellierungsentscheidungen erzwungen werden. Das ist nützlich, wenn Ihre Roadmap Experimente, Feature Engineering oder eine umfassende Archivierung der Quellhistorie vorsieht.
Ein Mart gewinnt, wenn das Unternehmen die Frage bereits kennt. Monatsabschlüsse, Margenberechnungen, Pipeline-Reviews, Schadenanalysen und regulatorische Dashboards hängen alle von stabilen Definitionen ab. Anwender erwarten verlässliche Zahlen, keinen Ausgangspunkt für Interpretationen.
Ein Lake speichert Möglichkeiten. Ein Mart liefert Verbindlichkeit.
Der versteckte architektonische Kompromiss
Viele Führungsteams vergleichen lediglich das Speicherformat und den Benutzertyp. Der grundlegende Kompromiss ist jedoch das Betriebsmodell.
Ein Lake verlagert den Aufwand nachgelagert. Entwickler können Daten schnell integrieren, aber irgendjemand muss immer noch Identifikatoren abgleichen, fehlende Werte behandeln, Daten standardisieren, Geschäftsregeln definieren und Quellkonflikte lösen. Wenn diese Disziplin ausbleibt, sammelt der Lake Daten an, ohne vertrauenswürdige Ergebnisse zu liefern.
Ein Mart verlagert den Aufwand vorgelagert. Teams müssen sich auf Definitionen einigen, bevor die Daten auf breiter Basis genutzt werden. Das kann sich langsamer anfühlen, reduziert aber wiederkehrende Missverständnisse. Die Kosten dafür sind nicht nur technischer Natur. Es ist eine Frage der organisatorischen Abstimmung.
Was funktioniert und was nicht
Einige Muster funktionieren erfahrungsgemäß immer:
Nutzen Sie den Lake zur Ablage und Konservierung: Bewahren Sie die Originaltreue der Quelle dort auf, wo rohe Details wichtig sind.
Nutzen Sie den Mart für entscheidungsrelevante Daten: Platzieren Sie gesteuerte KPIs und kuratierte Dimensionen dort, wo die Geschäftsbereiche arbeiten.
Trennen Sie die Geschwindigkeit der Datenerfassung von der Verlässlichkeit der Nutzung: Schnelle Erfassung und zuverlässiges Reporting sollten nicht in dieselbe Schicht gezwungen werden.
Andere Muster scheitern meist:
Jedem Team den direkten Zugriff auf den Lake erlauben: Dies führt oft zu inkonsistenten Kennzahlen und doppelter Logik.
Isolierte Marts direkt aus operativen Systemen bauen: Das geht anfangs schnell, ist im Unterhalt aber teuer.
Rohdaten als geschäftsbereit behandeln, nur weil sie vorhanden sind: Verfügbarkeit ist nicht gleichbedeutend mit Qualität.
Die Sicht der Führungsebene
Wenn Sie eine Plattform finanzieren, fragen Sie nicht nur, wo die Daten liegen werden. Fragen Sie, wo die Definitionen der Metriken leben, wer die Quellkonformität verantwortet und wie Fehler erkannt werden, bevor Führungskräfte sie sehen. Hier wird die Entscheidung zwischen Lake und Mart zu einer Plattformstrategie statt zu einer reinen Tool-Debatte.
Die passende Architektur für den jeweiligen Anwendungsfall
Die richtige Architektur erschließt sich von selbst, wenn man die Aufgaben betrachtet, die gelöst werden müssen.
Wann ein Data Lake die richtige Wahl ist
Ein Produkt- und ML-Team benötigt in der Regel rohe Verhaltensdetails. Sie wollen Sitzungsprotokolle, Event-Payloads, Support-Interaktionen, Gerätesignale und Trainingsdaten für Modelle, ohne dass diese beim Import stark gefiltert werden. Vielleicht wollen sie alte Daten mit einer neuen Hypothese erneut analysieren oder Quellen kombinieren, die ursprünglich nicht für dieselbe Fragestellung gedacht waren.
Das ist ein klassischer Anwendungsfall für einen Data Lake. Das Team braucht Freiraum zum Erkunden, Verknüpfen, Anreichern und Aufbereiten. All diese Daten zu früh in einen streng kuratierten Mart zu pressen, nimmt ihnen die Detailtiefe und führt zu ständiger Neumodellierung.
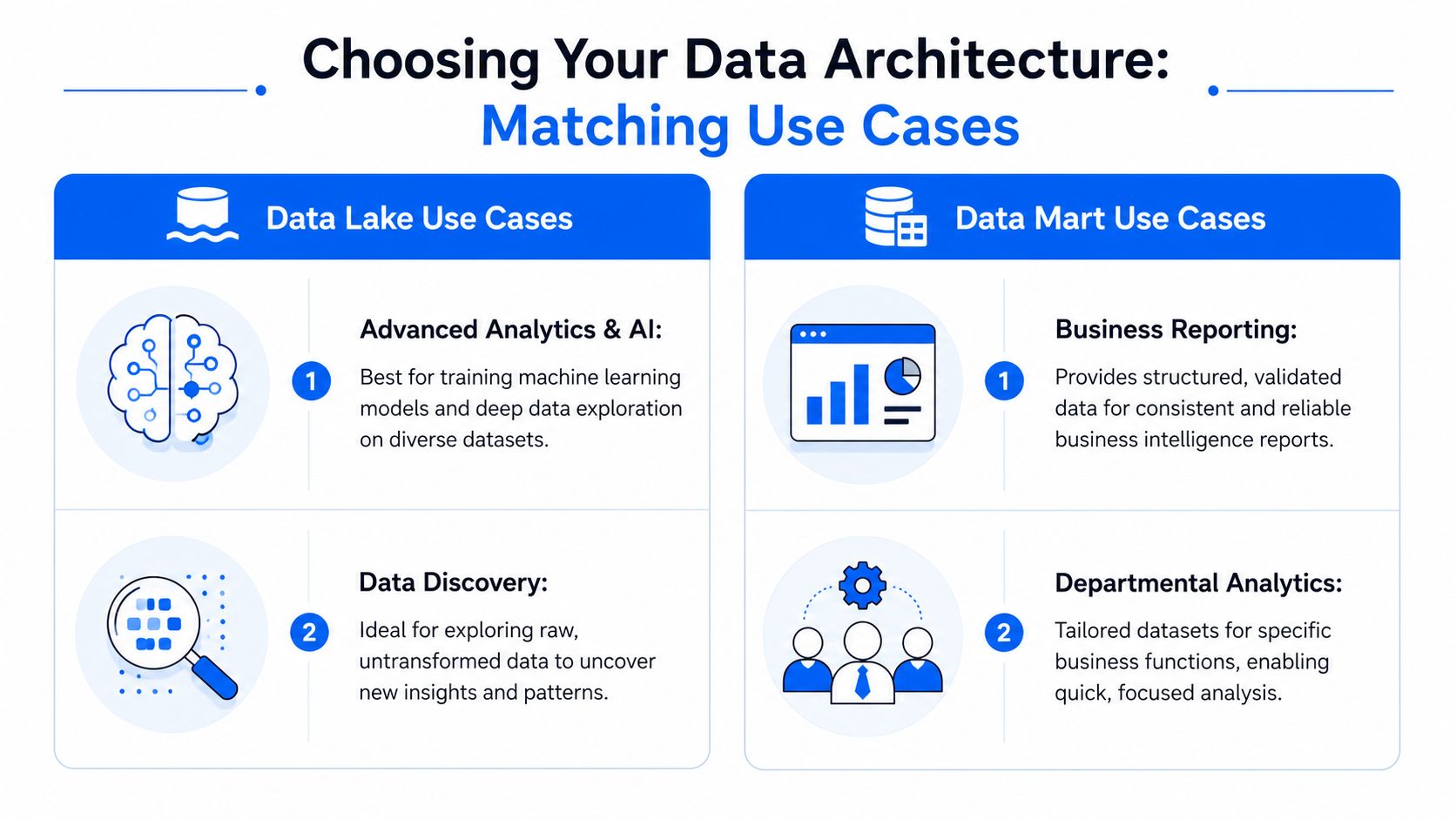
Wann ein Data Mart die bessere Lösung ist
Ein Finanzteam hat fast genau das gegenteilige Bedürfnis. Es möchte nicht jeden rohen Transaktionsstatus, jedes Zwischenereignis oder mehrere mögliche Umsatzinterpretationen sehen. Es wünscht sich ein einziges, kontrolliertes Set von Definitionen für Buchungen, realisierte Umsätze, Kostenallokation und Berichte zum Periodenabschluss.
Das ist ein Anwendungsfall für einen Data Mart. Der Mart schränkt den Spielraum bewusst ein. Er beseitigt Unklarheiten, damit die Quartalsberichterstattung nicht in eine Diskussion über die Semantik der Quellsysteme ausartet.
Zwei praktische Beispiele
Betrachten Sie diese typischen Muster:
Data-Science-Workflow: Entwickler legen Anwendungs-Events, API-Ausgaben und historische Snapshots in einem Lake ab. Data Scientists erstellen Features aus den Rohdaten und passen die Transformationen an, wenn sich die Anforderungen der Modelle ändern.
Abteilungsbezogener BI-Workflow: Analytics-Entwickler stellen einen Finanz-Mart mit abgestimmten Dimensionen, genehmigten Kennzahlen und geprüften Joins bereit, damit Controller und Führungskräfte dieselben Zahlen nutzen können.
Keines der beiden Muster ist moderner als das andere. Sie lösen lediglich unterschiedliche geschäftliche Probleme.
Wenn die Aufgabe in der Entdeckung liegt, optimieren Sie den Zugriff auf den rohen Kontext. Wenn die Aufgabe in der Rechenschaftspflicht liegt, optimieren Sie die Konsistenz.
Was die Führungsebene standardisieren sollte
Die stärksten Plattformen erzwingen nicht überall dieselbe Architektur. Sie standardisieren die Entscheidungskriterien:
Zielgruppe: Ist dieser Datensatz für Entwickler und Wissenschaftler oder für operative Geschäftseinheiten gedacht?
Fehlertoleranz bei Unklarheiten: Können die Anwender rohe Signale selbst interpretieren oder benötigen sie freigegebene Definitionen?
Änderungshäufigkeit: Wird sich die Transformationslogik häufig ändern oder muss sie aus Gründen der Governance stabil bleiben?
Konsequenzen von Fehlern: Handelt es sich um eine explorative Analyse oder um eine Zahl, die für das Budget, die Compliance oder externe Berichte herangezogen wird?
Diese Fragen lösen die Debatte über Data Lake vs. Data Mart meist schneller, als es ein langwieriger Tool-Vergleich je tun könnte.
Der kritische Pfad vom Lake zum Mart: Governance und Qualität
Die riskante Annahme bei vielen Architekturen ist, dass der Transfer von Daten aus einem Lake in einen Mart eine reine Pipeline-Routineaufgabe ist. Das ist es nicht. Hier werden unstrukturierte, inkonsistente Quellinformationen in eine geschäftliche Wahrheit verwandelt. Diese Umwandlung bringt Validierungen, Normalisierungen, Abgleiche, Deduplizierungen, Anreicherungen und Richtlinienentscheidungen mit sich, die viele Teams unterschätzen.

Warum die Übergabe scheitert
Rohdaten kommen selten in einem Zustand an, der für den Mart geeignet ist. Quellsysteme kodieren Stati unterschiedlich. Schlüssel passen nicht sauber zusammen. Optionale Felder werden im weiteren Verlauf zwingend erforderlich. Zeitstempel verschieben sich. Dateien treffen verspätet ein. Eine Schemaänderung in einer Quelle kann die Transformationslogik mehrere Schritte später unbemerkt ungültig machen.
Deshalb kann governance nicht erst nach dem Start hinzugefügt werden. Validierungsregeln, Verantwortlichkeiten, Datenherkunft und Abnahmekriterien müssen von Anfang an in den Prozess integriert werden.
Ein praktischer Leitfaden zu Datenverträgen und deren Implementierung ist hier sehr nützlich, da Verträge (Data Contracts) Teams zwingen zu definieren, was vorgelagerte Systeme liefern müssen, bevor nachgelagerte Marts von ihnen abhängen.
Qualitätsmängel, auf die Führungskräfte achten sollten
Eine Gesundheitsstudie aus dem Jahr 2024 zeigte, dass bis zu 40 % der Data-Lake-Exporte die Validierung der Geschäftsregeln verfehlen, bevor sie die Data Marts erreichen, wenn automatisierte Qualitätsprüfungen fehlen. Dies führt zu Pipeline-Abbrüchen und veralteten Berichten, wie in dieser Studie zur Datenqualität im Gesundheitswesen beschrieben. Das ist die operative Realität, die viele Architekturdiagramme aussparen.
Die geschäftliche Auswirkung ist direkt spürbar. Wenn Ihr Mart die Ebene ist, der die Geschäftsführung vertraut, dann ist der Weg vom Lake zum Mart nicht bloß IT-Infrastruktur. Es ist ein Kontrollpunkt.
Operativer Rat: Genehmigen Sie keinen neuen Mart, ohne dass die Verantwortlichkeiten für Validierung, Ausnahmebehandlung und Rollback-Regeln geklärt sind.
Was erfolgreiche Teams etablieren
Teams, die diesen Übergang erfolgreich managen, etablieren meist feste Kontrollmechanismen:
Eingangskriterien für Quelldaten: Definieren Sie, was vorhanden sein muss, bevor ein Datensatz weiterverarbeitet werden darf.
Kontrollpunkte bei der Transformation: Testen Sie Joins, den Umgang mit Nullwerten, Code-Maddings und die Einhaltung von Geschäftsregeln während der Verarbeitung.
Disziplinierte Releases: Versionieren Sie Ihre Transformationslogik und dokumentieren Sie Änderungen an Metrikdefinitionen vor der Veröffentlichung.
Eskalationspfade: Stellen Sie sicher, dass fehlerhafte Prüfungen direkt Maßnahmen auslösen, nicht nur Logeinträge.
Eine kurze Erläuterung zur Pipeline-Mentalität ist vor Tool-Diskussionen hilfreich:
Versteckte Kosten sind meist operativer Natur, nicht speicherbedingt
Führungskräfte planen oft Budgets für Speicherplatz ein und unterschätzen dabei die Kosten für Fehlerbehebungen. Der kostspielige Teil besteht nicht darin, Rohdaten in einem Lake zu speichern. Er liegt in den wiederkehrenden Aufwänden, die entstehen, wenn mangelhafte Daten nachgelagert durchrutschen und Teams anschließend Berichte korrigieren, Prozesse neu starten und widersprüchliche Zahlen erklären müssen.
Deshalb sollten Entscheidungen bezüglich Data Lake vs. Data Mart das Design der governance von Anfang an als Kernanliegen berücksichtigen. Ist die Verbindung dazwischen schwach, wirkt die Plattform auf dem Papier komplett, erweist sich in der Praxis jedoch als unzuverlässig.
Vertrauen sichern mit Data Observability
Die meisten Datenprobleme entstehen nicht dort, wo sie von den Anwendern bemerkt werden. Sie treten im Mart zutage, weil die Leute dort hinsehen, aber die eigentliche Ursache liegt oft weiter oben im Lake oder in den dorthin führenden Ingestions-Pipelines.
Warum die Überwachung des Marts allein nicht ausreicht
Ein Dashboard kann fehlerhaft sein, weil eine Quelldatei verspätet eintraf, sich ein Spaltentyp geändert hat, ein Ladevorgang unvollständig war oder eine zuvor stabile Verteilung so weit abgewichen ist, dass eine nachgelagerte Annahme nicht mehr stimmt. Wenn Sie nur die finale Tabelle oder die Dashboard-Abfrage überwachen, entdecken Sie das Problem erst, wenn das Unternehmen bereits damit arbeitet.
Untersuchungen aus dem Jahr 2024 zeigen, dass 65 % aller Datenqualitätsvorfälle in Data Marts auf unbemerkt gebliebene Probleme in vorgelagerten Data Lakes zurückzuführen sind, einschließlich Schemaänderungen und verzögerten Ladevorgängen, wie diese Studie zu den vorgelagerten Ursachen nachgelagerter Datenqualitätsprobleme belegt.

Was die Observability im Blick behalten muss
In einer modernen Plattform sollte Observability mindestens diese Fehlerquellen abdecken:
Aktualitätsprobleme: Erkennen Sie verspätete oder fehlende Datenlieferungen, bevor Berichtsfenster beeinträchtigt werden.
Schema Drift: Erkennen Sie hinzugefügte, entfernte oder im Typ geänderte Felder, bevor Transformationsprozesse unerwartet abbrechen.
Datenanomalien: Markieren Sie unerwartete Verteilungsänderungen, Volumenschwankungen oder ungewöhnliche Werte, die auf Probleme in den Quellen hindeuten können.
Validierungslücken: Verifizieren Sie, dass Datensätze weiterhin die von nachgelagerten Prozessen geforderten Regeln erfüllen.
Data Observability ist Teil der Architektur, nicht nur des reinen Betriebs. Wenn Ihr Lake so konzipiert ist, dass er flexibel bleibt, muss Ihre Überwachung so konzipiert sein, dass sie Disziplin sichert.
Ein praktisches Tooling-Muster
Teams kombinieren meist Orchestrierungsalarme, Transformationstests, Metadaten-Herkunft und Observability-Tools. Ein Beispiel dafür ist der Unterschied zwischen Data Observability und Data Quality, einfach erklärt. Dies verdeutlicht, dass die Überwachung des Pipeline-Verhaltens und die Validierung von Geschäftsregeln eng miteinander verwandt, aber nicht identisch sind.
In dieser Kategorie bietet sich digna als Option an, um Anomalien, Aktualität, Schemaänderungen und Validierungen auf Datensatzebene über Lakes, Warehouses und Pipelines hinweg zu überwachen und gleichzeitig Analysen direkt in der Kundenumgebung auszuführen. Das ist besonders in regulierten Branchen wichtig, in denen Teams operative Transparenz ohne umfassenden Datentransfer benötigen.
Ein verlässlicher Mart setzt einen überwachten Lake voraus. Vertrauen auf den nachgelagerten Ebenen beginnt auf den vorgelagerten Ebenen.
Was sich ändert, sobald Observability etabliert ist
Die größte Veränderung ist organisatorischer Natur. Datenteams sind nicht mehr darauf angewiesen, dass Anwender Probleme zuerst entdecken. Entwickler sehen verzögerte Lieferungen, bevor der CFO ein veraltetes Dashboard sieht. Analysten verstehen sofort, ob sich eine Kennzahl geändert hat, weil sich das Geschäft verändert hat oder weil ein Fehler in den Daten vorliegt. Governance-Teams erhalten einen klaren Audit-Trail darüber, warum ein veröffentlichter Datensatz für die Nutzung geeignet war oder nicht.
Das ist die fehlende Ebene in vielen Debatten über Data Lake vs. Data Mart. Architektonische Entscheidungen sind wichtig, aber Vertrauen entsteht dadurch, wie aktiv Sie den Pfad dazwischen überwachen.
Der Entscheidungsrahmen: Was benötigen Sie?
Der falsche Weg, die Frage nach Data Lake vs. Data Mart zu beantworten, ist eine pauschale Vorentscheidung. Der richtige Weg besteht darin, eine Reihe gezielter geschäftlicher und operativer Fragen zu stellen.
Die Checkliste für Führungskräfte
Müssen Sie rohe Daten in unterschiedlichen Formaten für spätere Analysen aufbewahren? Falls ja, benötigen Sie wahrscheinlich eine Lake-Komponente.
Benötigen Ihre Anwender gesteuerte Metriken für wiederkehrende Geschäftsentscheidungen? Falls ja, benötigen Sie einen oder mehrere Marts.
Sind Ihre primären Nutzer Data Scientists und Entwickler? Setzen Sie auf direkten Rohdatenzugriff und flexible Verarbeitung.
Sind Ihre primären Nutzer Analysten, Controller oder Führungskräfte? Bevorzugen Sie kuratierte Modelle und stabile Semantiken.
Kann Ihr Team Qualitätskontrollen zwischen den Schichten gewährleisten? Falls nicht, sollten Sie nicht davon ausgehen, dass ein Lake die Plattform vereinfacht.
Ist Konsistenz bei den Metriken für diesen Anwendungsfall wichtiger als die Vollständigkeit der Quellen? Falls ja, veröffentlichen Sie die Daten über einen Mart und nicht direkt aus dem Rohdatenspeicher.

Die Antwort lautet oft: Beides
In ausgereiften Plattformen lautet die Entscheidung meist und, nicht oder. Der Lake dient als Ablage- und Erkundungsebene. Der Mart wird zur Nutzungsebene für definierte Geschäftsbereiche. Die strategische Aufgabe besteht darin, festzulegen, wo die Qualitätsschranken liegen, wer die Transformationen verantwortet und wie Probleme erkannt werden, bevor sie sich auf Berichte auswirken.
Wenn das Management ein Prinzip für die Zukunft mitnehmen möchte, dann dieses: Speichern Sie breit, veröffentlichen Sie gezielt und überwachen Sie den Weg dazwischen. Dieser Ansatz gibt dem Unternehmen Raum für Weiterentwicklung, ohne das Vertrauen in die Zahlen zu gefährden, mit denen die Firma gesteuert wird.
Wenn Ihr Team eine Plattform aufbaut, auf der rohe Data Lakes geschäftskritische Marts speisen, lohnt es sich, digna als Teil der operativen Ebene zu evaluieren. Die Lösung konzentriert sich auf Datenqualität und Observability bei Anomalien, Schemaänderungen, Aktualität und Validierung, damit Teams Probleme früher erkennen und dafür sorgen können, dass kuratierte Daten verlässlich bleiben.



