Data Pipeline Software: Select for Scale & Reliability
|
0
min. Lesezeit

Your quarterly revenue dashboard looks wrong. The sales team insists bookings closed on time. Finance says the warehouse numbers don't reconcile. The pipeline jobs all show green, so the first instinct is to blame reporting logic. In large enterprises, that's often the trap. The dashboard isn't wrong because BI broke. It's wrong because bad data arrived on time, passed basic checks, and poisoned everything downstream.
That's why data pipeline software deserves more scrutiny than it usually gets. Most buying guides focus on connectors, batch versus streaming, and whether a tool can move rows from one place to another. Those matter. But at enterprise scale, the hard part is the last mile: proving the data is still trustworthy after it moved, transformed, merged, and landed in systems that executives and models depend on every day.
Table of Contents
What Is Data Pipeline Software Anyway
Data pipeline software is the machinery that moves data from source systems into places where people and applications can use it. That sounds simple until you map the complexities: CRM exports, ERP tables, event streams, SaaS APIs, warehouse models, data lake files, security telemetry, and model features all moving on different schedules with different quality profiles.
A better mental model is a factory line. Raw material enters from many suppliers. The line sorts it, cleans it, reshapes it, combines it with other inputs, and sends finished output to the right destination. If one station fails loudly, engineers can stop the line and fix it. If one station subtly mislabels material, the whole plant keeps running while defects spread.
That's why this software has become core infrastructure rather than middleware. The market reflects that shift. The global data pipeline market was valued at USD 12.26 billion in 2025 and is projected to reach USD 43.61 billion by 2032, growing at a CAGR of 19.9%, according to Fortune Business Insights on the data pipeline market. In practice, that growth tracks what platform teams already know. AI workloads, connected systems, and real-time decisioning have raised the cost of stale or corrupted data.
Practical rule: If a business calls a dashboard, model, or workflow “mission critical,” then the pipeline feeding it is mission critical too.
In enterprise environments, selecting data pipeline software isn't just about moving data. It's about deciding how much latency, fragility, operational toil, and business risk you're willing to accept.
Core Components and Common Architectures
The pipeline as an operating system for data movement
A production pipeline has a few core parts, regardless of vendor.
Sources are where data originates. That might be Salesforce, SAP, PostgreSQL, Kafka, S3, application logs, or a departmental spreadsheet that somehow became business critical.
Ingestion pulls data out of those systems. Some tools specialize in managed connectors. Others expect engineers to build extraction logic in Python, Spark, or SQL-centric workflows.
Transformation shapes the data. It standardizes formats, joins reference data, applies business logic, and prepares outputs for analytics, operations, or machine learning.
Orchestration handles order and dependency. It decides what runs, when it runs, and what happens when an upstream step finishes late or fails halfway through.
Destinations are where the data lands. Warehouses, lakes, lakehouses, feature stores, reverse ETL targets, and downstream applications all have different expectations around freshness and structure.

The mistake many teams make is treating these as isolated tool decisions. They're not. Each component affects the others. A connector strategy changes retry behavior. A transformation engine changes cost and debuggability. An orchestration layer changes how fast operators can identify blast radius.
Batch versus streaming and ETL versus ELT
The biggest architectural split is still batch versus streaming.
Batch is the bank statement model. Data arrives in chunks on a schedule. It's easier to reason about, often cheaper to operate, and usually enough for finance, compliance, and a lot of internal reporting.
Streaming is the fraud alert model. Data moves continuously, or close to it. You choose it when timing changes business value, such as operational telemetry, product analytics, or near-real-time user actions.
The demand side has already shifted. Real-time analytics is now the largest application category for data pipeline tools, surpassing traditional batch processing, according to Grand View Research on the data pipeline tools market. That doesn't mean batch is obsolete. It means more teams now need both.
A similar trade-off exists with ETL versus ELT:
ETL works well when you need tighter control before loading. It can reduce downstream clutter and help when governance rules are strict.
ELT fits modern warehouses and lakehouses well. Load first, transform later. It usually improves iteration speed because raw data lands quickly and analysts can evolve models without rebuilding extraction logic.
Hybrid patterns are common in large enterprises. Teams often pre-validate sensitive or high-risk data, then finish broader transformations in the warehouse.
If your organization is moving toward domain ownership, self-serve analytics, or federated platforms, it helps to understand how data mesh affects modern data architectures. The architecture decision isn't only technical. It changes who owns pipelines, who sets contracts, and who responds when data breaks.
A clean architecture diagram isn't proof of a healthy pipeline. Operational fit matters more than diagram symmetry.
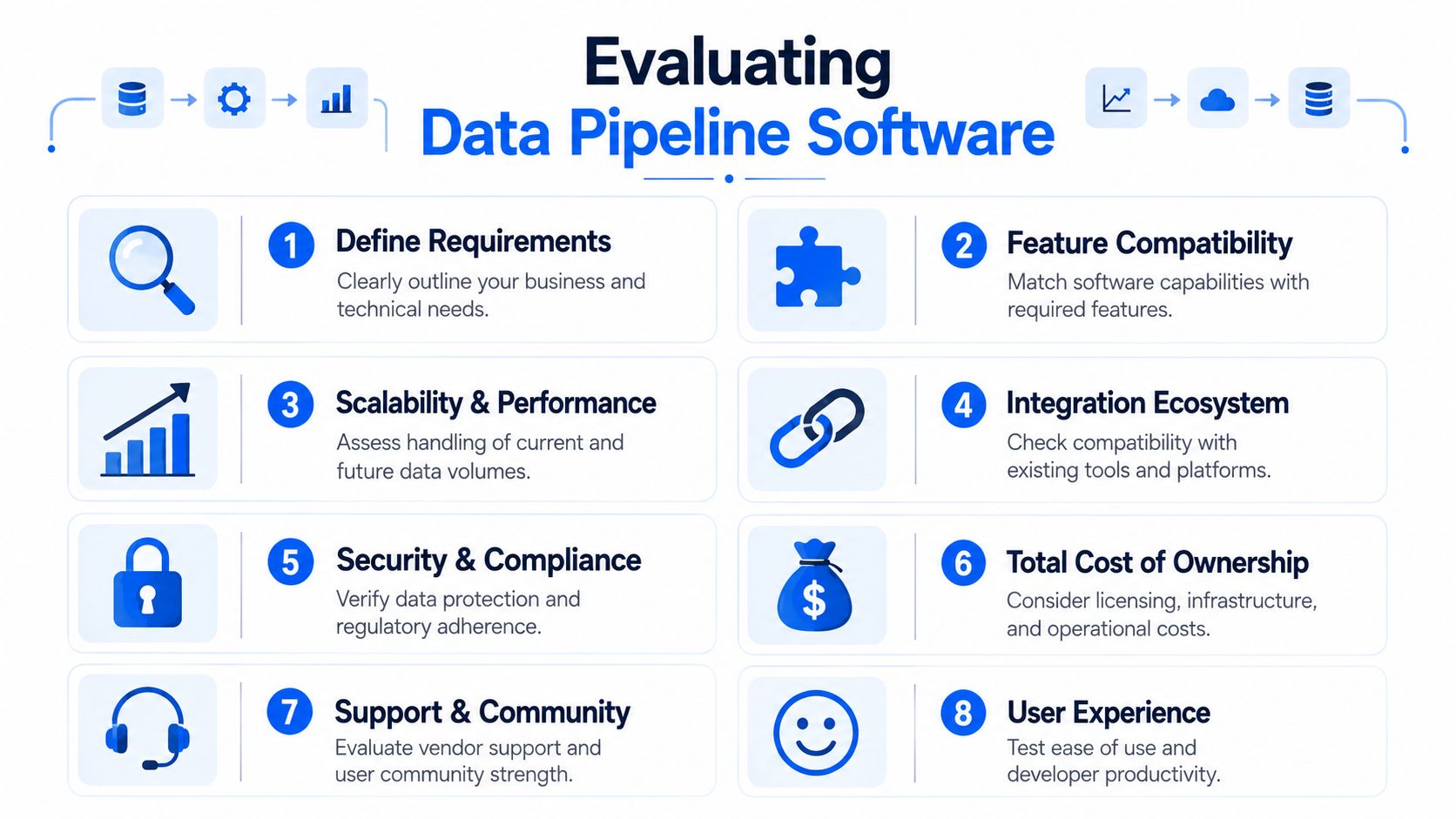
Essential Features of Modern Pipeline Software
Five capabilities that matter in production
When teams evaluate data pipeline software, they often over-weight connector counts and under-weight daily operability. A strong platform has to do more than ingest records.

Data ingestion
It needs to connect to the systems you already run, not the idealized stack in a vendor slide. Native support for databases, SaaS platforms, files, APIs, and event systems reduces custom maintenance.
Transformation
Good software lets teams express business logic clearly and test it close to where it runs. SQL-first flows work well for analytics-heavy teams. Code-first options matter when transformations get procedural or stateful.
Orchestration
Scheduling is the easy part. Dependency management, reruns, idempotency, backfills, and failure handling are what separate a demo from a platform.
Monitoring
Operators need to know whether jobs ran, how long stages took, what changed, and where a failure started. Runtime visibility saves hours during incidents.
Security and governance
Enterprises need role control, auditability, deployment flexibility, and alignment with internal data handling rules. If the software fights your security model, adoption stalls.
The best platforms make these capabilities feel connected. For example, orchestration should understand transformation dependencies. Monitoring should expose context from ingestion through destination. Governance should apply across environments rather than as an afterthought bolted onto the UI.
What strong platforms do beyond the feature list
Feature checklists often flatten meaningful differences. Two tools may both claim orchestration support, but one offers reliable restart behavior and dependency visibility while the other only triggers tasks on a timer.
Look for signs of production maturity:
Operational clarity: Can an engineer tell, quickly, what failed and what downstream assets are affected?
Controlled recovery: Can the team rerun a partition or date range without duplicating data?
Developer usability: Does the platform make testing and local iteration practical, or does every change require full environment deployment?
Platform fit: Can centralized platform teams and domain teams both use it without stepping on each other?
Short-term productivity often hides long-term drag. A tool that makes simple loads easy but complex incidents hard becomes expensive fast. In enterprise settings, the core value of data pipeline software is that it gives teams a repeatable operating model, not just a faster way to move tables.
Integrating Data Quality and Observability
Why green jobs still produce bad data
Traditional pipeline monitoring tells you whether compute ran. It usually doesn't tell you whether the output still makes sense. That's the gap many enterprise teams discover too late.
A pipeline can complete successfully while delivering incomplete joins, shifted schemas, delayed dimensions, or semantically broken fields. The dashboard refreshes. The model retrains. Nobody gets an alert because nothing “failed” in the narrow technical sense.
That blind spot is larger than many teams assume. Industry data shows pipelines fail undetected in up to 40% of cases due to issues like late-arriving dimensions or semantic drift that bypass standard volume and freshness checks, according to this discussion of silent failures and AI-powered anomaly detection.

Many teams confuse data quality with job health. Row count checks, task success states, and SLA timers matter, but they only cover obvious breakage. Silent failures slip through because the pipeline behaves mechanically as designed while the data itself deviates from business reality.
What observability adds that testing alone does not
Testing still matters. In fact, practical pipeline testing is more useful than many teams make it. Engineers often validate lift-and-shift loads with row counts and aggregates, compare snapshots before and after changes, sample date ranges or regional slices to control cost, and use differential queries such as A EXCEPT B and B EXCEPT A to isolate drift. Those patterns are grounded in working data engineering practices shared in this pipeline testing discussion.
But tests alone won't cover every behavioral change. They check for what you predicted. Observability helps detect what you didn't predict.
Use the two together:
Tests enforce known expectations. Required columns, valid IDs, accepted ranges, reconciliation logic.
Observability tracks changing behavior over time. Timeliness shifts, unusual distributions, schema drift, and anomalies in fields that no one wrote a rule for.
Operational response ties the signal back to ownership. Alerts need routing, context, and a clear responder path.
A useful way to think about it is this. Testing asks, “Did the pipeline satisfy the rules we already know?” Observability asks, “What changed that should worry us even if no explicit rule was written?”
Teams trying to separate these concepts usually end up with gaps. A stronger approach is to treat observability as the outer detection layer around your pipeline, quality rules, and downstream contracts. If you want a sharper distinction between the two disciplines, this breakdown of data observability versus data quality is a good reference point.
Silent failures are expensive because they preserve confidence while corrupting outputs.
For large enterprises, this is the last-mile requirement. Data pipeline software should not only move data at scale. It should help operators know whether the arriving data is still fit for decisions.
How to Evaluate and Select Enterprise Software
Start with operating constraints, not demos
Most enterprise evaluations go wrong before the first proof of concept. Teams start with vendor demos, feature pages, and connector matrices. The better sequence is operational. Define your hard constraints first, then eliminate anything that can't live inside them.
That usually starts with deployment model. Some organizations can use SaaS control planes comfortably. Others require private cloud or on-prem because of policy, data sovereignty, or sector-specific controls. If that's your reality, don't treat deployment as a procurement detail. It changes architecture, support responsibilities, access patterns, and incident workflows.
The next filter is scale behavior. Ask how the platform handles growing table counts, concurrency, reruns, and mixed workloads. A product may look fine on a narrow batch ingestion demo and still fall apart under real enterprise conditions such as cross-region schedules, warehouse contention, and overlapping backfills.
Then assess ecosystem fit. Data pipeline software rarely lives alone. It has to work with your warehouse, transformation layer, orchestration stack, alerting tools, ticketing flow, identity model, and governance processes. Integration quality often matters more than feature depth.
Selection rule: Buy for the incidents you'll have, not the happy-path demo you were shown.
A procurement process is stronger when platform engineering, security, data governance, analytics engineering, and operations all score the tool separately. The disagreements are useful. They expose where a product creates hidden costs outside the engineering team that requested it.
Data Pipeline Software Evaluation Checklist
Evaluation Criteria | Key Questions to Ask | Why It Matters |
|---|---|---|
Deployment model | Can it run in SaaS, private cloud, or on-prem as required? | Avoids security and compliance dead ends late in procurement. |
Scalability | How does it behave under larger volumes, more pipelines, and more concurrent runs? | Growth pressure shows up gradually, then all at once. |
Recovery model | Does it support retries, checkpointing, partition reruns, and safe backfills? | Incident response quality determines operator load. |
Integration ecosystem | Does it work cleanly with your warehouse, lake, orchestrator, IAM, and alerting stack? | Poor integration creates brittle glue code. |
Developer workflow | Can engineers test locally, promote safely, and understand pipeline lineage? | Faster iteration reduces change risk. |
Observability support | Can operators detect freshness issues, schema changes, and silent anomalies? | Green jobs don't guarantee trustworthy data. |
Governance and security | How are access, auditing, data residency, and policy enforcement handled? | Enterprise adoption depends on control, not just convenience. |
Total cost of ownership | What infrastructure, maintenance, training, and support overhead comes with the license? | Cheap software can be expensive to run. |
A practical evaluation usually includes three exercises:
Run a normal path test: Move representative data through a standard workflow.
Run a failure test: Break a schema, delay a dependency, and force a partial rerun.
Run an operator test: Hand the incident to someone who didn't build the pipeline and see how quickly they can diagnose it.
That third exercise is where weak tools usually get exposed.
Common Pitfalls and How to Avoid Them
The technical debt tangle shows up in production
Teams under delivery pressure often optimize for getting data through once. The debt appears later, when nobody can explain why the same job succeeds on Tuesday, fails on Wednesday, and corrupts a downstream table on Thursday.

One common failure pattern is designing only for the happy path. The source API returns malformed payloads. An upstream team adds a column. A load restarts mid-run. If the pipeline has no resilience built into those paths, operators end up doing manual repair work under business pressure.
Another pitfall is under-testing changes. Production-grade checks don't need to be exotic. Row counts, aggregate comparisons, snapshot regression tests, and targeted sampling catch a lot. So do differential queries around source boundaries and before critical joins, where bad records multiply downstream.
The debt also comes from over-centralization. Monolithic jobs with extraction, transformation, and loading glued together are hard to test and harder to rerun safely. Breaking pipelines into smaller stages usually improves both debuggability and recovery.
A useful mental contrast comes from lightweight automation worlds. Even teams automating social media with n8n templates learn quickly that visible workflow steps, retry behavior, and failure branching matter more than a clever one-shot script. Enterprise data systems need the same discipline, only with much higher blast radius.
What resilient teams do differently
Retry logic and checkpointing should be built into the pipeline itself, not left to operator improvisation. Retry logic embedded within Extract, Transform, and Load stages, plus checkpointing that stores state externally for automatic restarts, are core parts of resilient pipeline architecture, as described in this resilience-focused pipeline discussion.
That same guidance points to another often-missed control. Schema validation at the entry point prevents poor-quality or incomplete source data from entering the flow unchecked. This is one of the cheapest places to stop damage.
For a deeper treatment of production failure patterns, this article on why data pipelines fail in production and how to detect issues early is worth reading.
Use a simple resilience checklist:
Validate early: Check schema and essential record expectations before expensive downstream work starts.
Store state externally: Make restarts deterministic after crashes or container eviction.
Degrade gracefully: Skip or quarantine bad records when the business can tolerate it, instead of crashing the entire workflow.
Watch memory and joins: Resource pressure and bad joins often create failures that look random until you inspect execution behavior.
Keep old paths alive during major migrations: Parallel run periods reduce irreversible cutover mistakes.
This short video adds a useful operational lens on production reliability:
The goal isn't perfect prevention. It's survivability. Strong teams build pipelines that fail in bounded, recoverable ways.
Conclusion Your Next Steps Toward Reliable Data
Reliable analytics and AI don't start with better dashboards. They start with pipeline discipline. Data pipeline software has to do more than move records across systems. It has to support safe recovery, clear operations, and the last-mile controls that catch bad data before people trust it.
If you're leading a platform or data engineering team, take three concrete steps next.
First, audit your current pipelines for silent risk. Don't just review failed jobs. Review “successful” ones that feed critical dashboards, forecasts, and models. Look for weak spots around schema drift, late arrivals, partial joins, and manual reruns.
Second, add observability incrementally. Start with your highest-impact pipelines, not the whole estate. Combine deterministic tests with behavioral monitoring so you can catch both known violations and unexpected changes.
Third, build the business case in operational terms. Executives don't need another lecture on architecture patterns. They understand delayed reports, wrong decisions, broken trust, and teams spending too much time diagnosing preventable issues.
The teams that get this right don't chase perfect elegance. They design for clarity, resilience, and confidence. That's what makes enterprise data dependable.
If your team wants a practical way to monitor data anomalies, timeliness, validation, and schema changes in private cloud or on-prem environments, take a look at digna. It's built for enterprises that need modern data quality and observability without giving a vendor access to production data.



