Data Platform Engineering: Build Resilient Systems
|
6
min read

Your dashboards look healthy until the Monday revenue report is off, the customer success team is arguing with finance over whose number is correct, and an ML feature pipeline starts feeding stale values into a model. Nothing is technically “down.” Jobs ran. Tables exist. BI still loads. But the organization has lost trust in data.
That's the operating reality that pushed many teams from ad hoc data engineering toward data platform engineering. The problem usually isn't a lack of pipelines. It's a lack of a system that delivers reliable data, consistently, across many teams and changing workloads.
The strongest platforms don't treat reliability as a side project owned by a handful of senior engineers. They package it as a service. In practice, that means ingestion patterns, schema controls, freshness checks, access policies, and observability are built into the platform itself. Observability isn't bolted on after the fact. It acts as the central nervous system that tells you what changed, what's late, what drifted, and what will break next if you ignore the signal.
Table of Contents
The Rise of Data Platform Engineering
Data teams didn't arrive here because “platform” became fashionable. They arrived here because one-off pipeline delivery stopped scaling. Each new dashboard, ML feature, reverse ETL sync, or compliance request added another fragile path through the stack. The local fix worked, then the dependencies multiplied.
The investment trend reflects that shift. The Big Data Engineering Services Market is projected at USD 105.38 billion in 2026 and is projected to reach USD 213.07 billion by 2031 at a 15.12% CAGR, with Data Integration and ETL services holding a 39.22% share in 2025, according to Mordor Intelligence's big data engineering services market analysis. That mix matters. Teams still spend heavily on the fundamentals because reliable movement and shaping of data remains the base layer of every modern platform.
Why the old model breaks
Traditional delivery often looks efficient at first:
A team requests a dataset
An engineer builds a pipeline
A dashboard goes live
A downstream dependency appears
The original assumptions change
Then things drift. Source owners rename fields. Business logic forks between teams. Freshness expectations differ. Every pipeline starts carrying hidden operational policy.
Practical rule: If reliability depends on tribal knowledge in one engineer's head, you don't have a platform. You have a rescue service.
Data platform engineering emerged as the response to that failure mode. It treats the data estate as a shared operational system, not a collection of project outputs. The central question changes from “How do we ship this pipeline?” to “How do we make trustworthy data delivery repeatable?”
Reliability becomes the product
This is the useful framing. A modern data platform doesn't just provide storage and compute. It provides data reliability as a service. Teams should inherit sensible defaults for ingestion, quality checks, freshness monitoring, schema awareness, and governed access.
That's why observability belongs at the center. Without it, teams discover data failures through broken dashboards, executive escalations, or model degradation. By then, the platform is already failing its users.
What Is Data Platform Engineering
Data platform engineering is easier to understand if you compare it to city infrastructure. Traditional data engineering often builds the equivalent of a private generator for each house. It solves an immediate need, but every new consumer needs another custom setup, more maintenance, and another person who understands the quirks.
A data platform is the grid. It gives many teams a reliable way to ingest, transform, serve, and monitor data through shared capabilities.
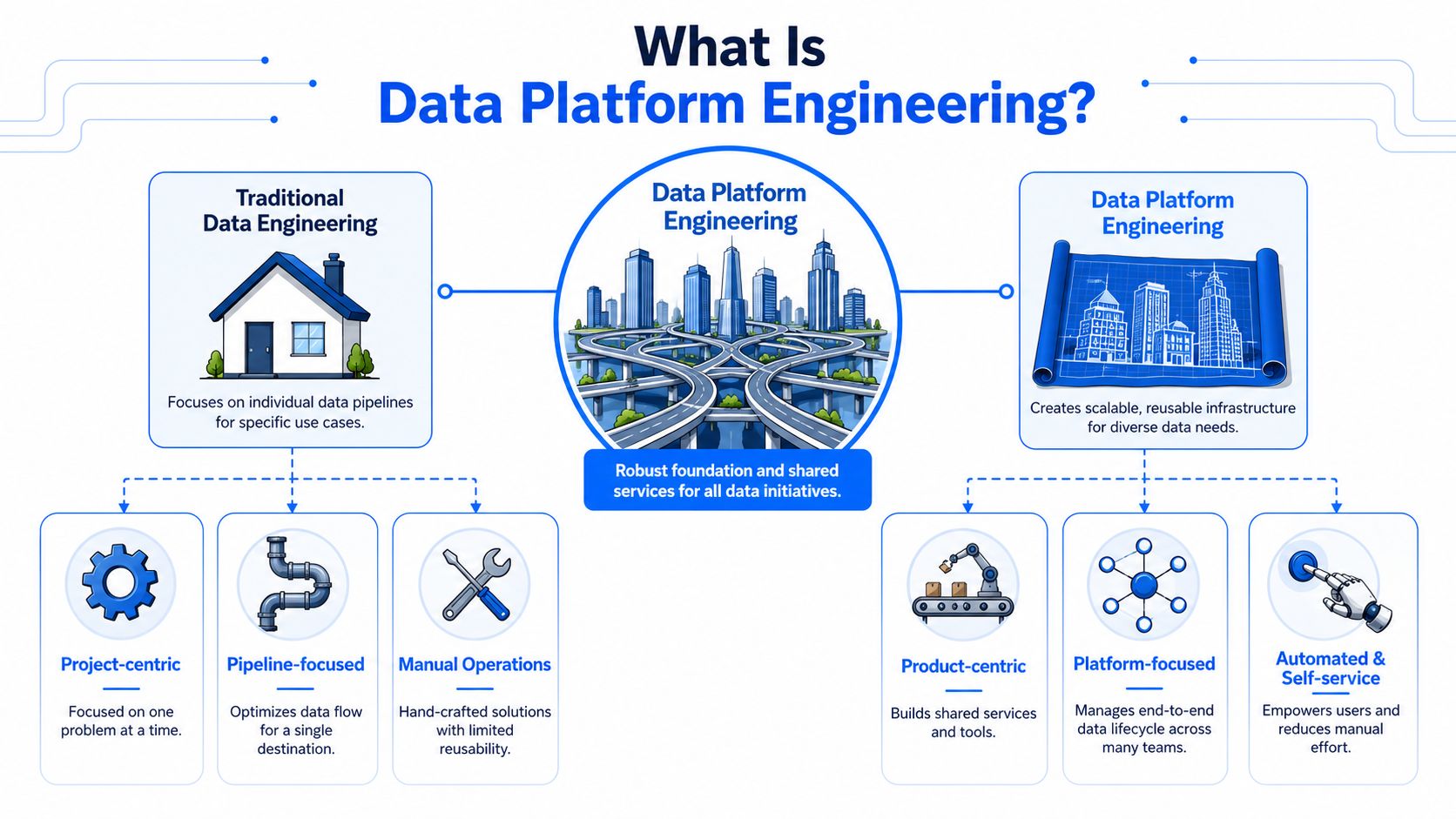
From custom pipelines to shared infrastructure
In practice, data platform engineers build reusable internal systems rather than isolated deliveries. The platform typically exposes standard paths for:
Ingestion: Teams can bring in batch or streaming data without designing everything from scratch.
Transformation: Analysts and engineers work from governed models and shared runtime patterns.
Access: Consumers get controlled ways to query, publish, and share data products.
Operations: Monitoring, alerting, lineage context, and quality checks are part of the path, not optional extras.
The organizational shift behind this is already well underway. 55% of organizations worldwide have implemented platform engineering practices, and 90% of those plan to expand it, according to Google Cloud's platform engineering research report. The same report says over 61% of practitioners reported significant or slight improvements in data initiatives after adopting this model.
That result makes sense. Self-service doesn't mean no standards. It means the standards are encoded into the platform so users don't need to negotiate every action with a central team.
A useful visual helps here:
Why the product mindset matters
The phrase platform as a product gets overused, but the idea is sound. If your internal platform has users, then it needs product thinking:
Concern | Weak approach | Strong approach |
|---|---|---|
Onboarding | Documentation dump | Golden paths and templates |
Reliability | Team-specific scripts | Standardized monitoring and controls |
Access | Ticket queue | Governed self-service |
Change management | Break and repair | Versioned interfaces and clear ownership |
What works is boring in the best way. Standard contracts. Repeatable deployment patterns. Opinionated defaults. A small number of supported ways to do common work.
What doesn't work is calling a pile of tools a platform. If every new data product still requires bespoke Terraform, one-off orchestration logic, hand-written quality checks, and direct intervention from senior engineers, the platform hasn't abstracted enough.
Build for the median use case first. Platforms fail when teams optimize for edge cases before they provide a reliable default path.
Modern Data Platform Architecture Patterns
A modern platform is a stack of deliberate layers. The goal isn't to collect tools. The goal is to create an internal developer platform that hides infrastructure complexity while preserving control where it matters.

The layers that matter
The cleanest architectures usually separate concerns into a few stable layers.
Ingestion layer. This handles movement from source systems into the platform. Some sources arrive in scheduled batches. Others arrive continuously. The key design choice isn't batch versus stream as an ideology. It's whether the platform exposes both patterns through standard interfaces with consistent metadata, ownership, and retry behavior.
Storage layer. This is commonly a lake, warehouse, lakehouse, or a combination. The wrong move is arguing theology. The right move is deciding where raw data lands, where curated models live, and where analytical serving should happen. Teams need clarity more than novelty.
Transformation and processing layer. Raw data becomes usable in this layer. Good platforms standardize execution patterns so teams aren't reinventing runtime behavior. They also keep processing close to where data lives when possible, because data movement is often the hidden source of latency, cost, and operational complexity.
Serving layer. BI tools, APIs, feature generation, and downstream applications all consume data differently. The platform should expose these paths intentionally, with contracts and expectations around freshness, access, and support.
Patterns that age well
The strongest pattern is the one that reduces repeated friction. That's why the Internal Developer Platform model is so practical. According to PlatformEngineering.org's explanation of the data platform engineer role, data platform engineering standardizes ingestion, access, and metadata as shared capabilities, which reduces duplicated quality work and onboarding delays.
That principle is more important than any single architecture label. Whether you adopt warehouse-first modeling, a lakehouse approach, or a domain-oriented structure influenced by modern data mesh architectures, the same question applies: can teams consume and publish data without rebuilding platform concerns every time?
A few trade-offs show up repeatedly:
ETL versus ELT: ETL gives tighter control before loading. ELT simplifies ingestion and pushes transformation into the analytical engine. Teams often choose based on source variability, governance needs, and where they want complexity to live.
Centralized versus federated ownership: Centralization improves consistency. Federation improves domain responsiveness. Most mature environments land somewhere in between, with central platform capabilities and domain-owned data products.
Warehouse processing versus external compute: In-database processing reduces movement and governance sprawl. External engines can help for specialized workloads. The wrong choice is letting every team decide independently.
A healthy architecture is one where consumers can ignore most of the infrastructure, but operators can still see everything that matters.
Core Operational Concerns for Data Platforms
Architecture gets attention because it's visible. Operations decide whether the platform earns trust. A platform can have elegant layers and still fail the company if users can't tell whether data is fresh, complete, structurally stable, cost-efficient, and accessible under policy.

Observability as the control plane for reliability
Observability is often discussed too narrowly, focusing on dashboards for pipeline runtime, maybe some row-count checks, then an alert channel. That's monitoring. It's necessary, but it's not enough.
In a well-run data platform, observability is the system that joins five realities:
What data arrived
When it arrived
Whether the structure changed
Whether the content still behaves normally
Who and what downstream depends on it
That's why I describe observability as the central nervous system. It senses state changes across the platform and turns them into actionable operational context. Without that layer, reliability work becomes manual interpretation.
When teams skip this, they usually compensate with more meetings, more runbooks, and more brittle checks. The platform appears cheaper to build, then becomes expensive to operate.
The operational pillars that decide trust
These concerns aren't independent. A weakness in one usually leaks into the others.
Data quality: This includes validity, completeness, distribution shifts, and business-rule conformance. Manual rule sprawl is a common trap. Teams write many checks, then stop maintaining them. Good platforms separate broad anomaly detection from targeted validation so operators can detect unknown changes and still enforce specific business rules.
Timeliness: Freshness is part of correctness. Data that arrives late can be as harmful as wrong data. The platform needs expected arrival patterns, delay detection, and a way to distinguish “job still running” from “upstream stopped sending.”
Schema management: Many incidents start with a harmless-looking source change. Added columns, removed fields, and data type changes shouldn't be discovered by downstream users. Structural awareness must sit close to ingestion and transformation paths.
A concise decision table helps:
Operational concern | What usually fails | What good teams do |
|---|---|---|
Quality | Static checks miss new failure modes | Combine anomaly detection with explicit validations |
Timeliness | Teams only monitor job completion | Monitor data arrival expectations |
Schema | Changes are found downstream | Track structural changes near the source |
Cost | Compute grows without ownership | Tie spend to workloads and platform usage patterns |
Access control | Policy lives outside workflows | Bake access decisions into the default path |
The platform also needs cost governance and access control, but both work better when observability feeds them. If you can't see workload behavior, cost optimization becomes guesswork. If access changes happen without context, governance becomes a ticketing burden instead of a design property.
For teams dealing with recurring production instability, disciplined detection proves its worth. A practical reference on why data pipelines fail in production and how to detect issues early maps closely to what experienced platform teams learn the hard way: incidents rarely begin at the dashboard layer. They begin upstream, then spread unnoticed.
The most expensive data incident is the one that looks normal long enough for people to make decisions with it.
The Data Platform Engineering Toolkit
Tool selection gets noisy because teams compare vendor categories before they agree on platform jobs. Start with the jobs. Then choose products that fit your operating model, team skill set, and existing estate.
According to MotherDuck's overview of the modern data engineering toolkit, a common stack combines Kubernetes and Docker for containerization, Terraform for infrastructure as code, orchestrators like Airflow or Dagster, plus SQL engines and Python frameworks for processing. That combination works because each layer solves a distinct operational problem.
Choose categories before products
Here's the mental model I use:
Category | Role in the platform | Common examples |
|---|---|---|
Containerization | Standard runtime packaging and deployment | Docker, Kubernetes |
Infrastructure as code | Repeatable environments and policy | Terraform, Pulumi |
Orchestration | Scheduling, dependency management, retries | Airflow, Dagster, Prefect |
Processing | Transforming and querying data | Snowflake, DuckDB, Python frameworks |
Observability | Detecting drift, delays, failures, and schema changes | Platform-specific observability tools |
This structure avoids a common mistake. Teams often over-invest in orchestration and under-invest in observability. They can schedule everything, but they can't tell if the output is trustworthy.
Another mistake is selecting tools that optimize for engineer preference rather than platform consistency. One team loves Python-first workflows, another wants SQL-first transformation, a third wraps everything in custom services. That freedom feels productive until on-call starts.
What works and what usually does not
What works:
Opinionated combinations: A supported orchestration engine, one primary IaC pattern, and clear processing paths.
Runtime standardization: Containers and declarative environments reduce “works on my machine” problems.
Observability attached to delivery: Checks and monitoring travel with the data product lifecycle.
What usually doesn't:
Excessive optionality: Five supported orchestrators is not flexibility. It's fragmented operations.
DIY everything: Custom frameworks age fast unless you have a real platform team to own them.
Late evaluation of pipeline tooling: Teams should compare data pipeline solutions against platform requirements like governance, observability hooks, and operating model, not just connector counts.
The best toolkit is the one your team can operate predictably at 2 a.m., not the one that wins architecture debates.
Example A Modern Observability-Driven Platform
A realistic failure starts small. An application team adds a new column to a source table and changes the type of an existing field during a release. The upstream change is reasonable from their point of view. Nobody intends to break downstream analytics.

A schema change enters the system
In a weak platform, the sequence is familiar. The ingestion job still runs because the connector doesn't hard-fail. A transformation step casts values incorrectly or drops records. A dashboard owner notices strange numbers hours later. The data team starts tracing logs, comparing table definitions, and asking source owners what changed.
An observability-driven platform behaves differently because it treats structural and behavioral signals as first-class events.
The platform's schema tracker flags the added column and the type modification as soon as the change lands. That matters because structure is often the earliest indicator of downstream risk. At the same time, anomaly detection watches the affected business metrics for shifts that no one explicitly encoded as rules.
A freshness monitor adds one more piece of truth: the data arrived on time. That narrows the search immediately. The incident is no longer “pipeline might be broken.” It becomes “delivery is timely, but structure changed and content behavior moved.”
How the platform responds without drama
Integrated observability yields operational benefits.
The schema event is detected The platform surfaces which field changed and where that field appears downstream.
Metric behavior is evaluated If a key metric moves outside its learned normal pattern, the team gets a second signal tied to impact, not just infrastructure.
Timeliness is confirmed Engineers avoid wasting time on scheduler and ingestion investigation when freshness isn't the issue.
Owners can act by priority If only a low-risk downstream model uses the changed column, the fix path differs from a finance dashboard dependency.
That combination shortens diagnosis because each signal removes uncertainty. The system isn't just alerting. It's shaping the incident.
Teams evaluating data observability versus data quality approaches often frame them as alternatives. In practice, they solve different parts of the same operational problem. Observability detects unexpected change across the system. Data quality enforces expected rules. Mature platforms need both.
Reliable platforms don't eliminate incidents. They make incidents legible before they become business failures.
The Future of Data Platform Engineering
The next step for data platform engineering sits at the boundary with AI platform engineering. Many organizations already ship AI-infused applications, but the platform maturity underneath those workloads often lags far behind the ambition.
That gap is visible in the numbers. 25% of organizations already use AI-infused applications, while only 10% have mature platforms for AI workloads, according to Luca Galante's discussion of platform engineering and AI. The same source identifies the integration of data and AI platforms as the biggest trend, while also highlighting how underserved it remains in practice.
The reason is straightforward. AI systems inherit every reliability problem from the data platform, then amplify them. Late data becomes stale features. Silent drift becomes degraded model behavior. Weak schema controls become training-serving inconsistency. If observability is optional, teams won't catch these failures early enough.
The future platform won't just provision notebooks, vector stores, or model endpoints. It will carry forward the hard lessons of data platform engineering: standard interfaces, governed self-service, structural awareness, freshness monitoring, anomaly detection, and operational context attached to every critical data path.
That's the maturity curve. First, build platforms that make analytics trustworthy. Then extend the same reliability discipline into AI workloads, where the cost of bad inputs is often harder to see and more expensive to unwind.
If your team wants to make data reliability a built-in service instead of a manual rescue process, digna is worth a look. It helps data teams detect anomalies, monitor timeliness, validate records, and track schema changes inside their own environment, which makes it a practical fit for modern platforms that need observability without moving sensitive data outside customer-controlled infrastructure.



