Data Lake vs Data Mart: Which Is Right for You?
|
8
min read

A lot of teams hit the same wall at roughly the same stage of growth. Product events are pouring in. CRM data keeps multiplying. Finance wants a clean monthly view. Marketing wants attribution they can trust. Data science wants raw logs, not someone else's summary table. Everyone says they need “the right architecture,” but the actual decision usually gets flattened into a simplistic data lake vs data mart debate.
That framing causes problems. In practice, most modern teams don't choose one forever and ignore the other. They build both, or they build one and eventually depend on the other. The central question is how each one fits into the pipeline, what each is good at, and where the risks show up when raw data quality starts to slip. If you're evaluating a lakehouse pattern too, this guide on what a lakehouse is and how to maintain data quality is a useful companion because the same operational issues carry over.
Table of Contents
The Crossroads of Modern Data Architecture
The usual trigger isn't technical. It's organizational.
A company starts with a few dashboards and a reporting database. Then new products launch, teams add SaaS tools, customer interactions spread across web, app, support, and third-party platforms, and someone asks for machine learning on top of it all. Suddenly, the old stack can't absorb raw inputs fast enough, and the business still expects curated numbers by Monday morning.
At that point, leaders often hear two competing answers. One camp argues for a data lake because the business needs flexibility, raw history, and support for data science. The other pushes for a data mart because business teams need governed, reliable, fast answers for a specific function. Both are right, but only within the boundaries of the problems they're solving.
What teams usually get wrong
The mistake is treating the decision as if it were a product shootout. It isn't.
A data lake is an ingestion and exploration foundation. A data mart is a consumption layer for a focused business audience. They solve different problems, serve different users, and fail in different ways. When teams collapse them into a single choice, they usually overbuild one side and underinvest in the controls that connect them.
Teams rarely regret storing raw data they may need later. They often regret exposing business users to data that wasn't prepared for operational decisions.
The practical consequence
If you choose only for immediate reporting, you can limit future analytics and ML options. If you choose only for flexibility, you can create a platform that stores everything but answers very little cleanly.
That's why the better discussion isn't “Which one wins?” It's “Where should raw data live, where should business-ready data live, and how do we stop quality issues upstream from subtly poisoning downstream decisions?”
Defining the Core Concepts
These definitions matter because teams often use the terms loosely, then build the wrong layer for the job.

What a data lake is
A data lake is a centralized store for raw data in its native format. It can hold structured tables, semi-structured records such as JSON, and unstructured content such as images, audio, logs, and event streams. IBM's definition of a data lake aligns with how practitioners use the term in modern platforms. The lake is the place to land data before every business rule, join, and naming standard has been settled.
That flexibility is useful, but it shifts work downstream.
In practice, a lake supports ingestion first and interpretation later. Engineers can retain full-fidelity source data, preserve historical detail, and support use cases that are still evolving. Data scientists and advanced analytics teams benefit from that freedom because raw attributes, sparse fields, and source quirks often matter during feature development and root-cause analysis.
The trade-off is operational, not theoretical. A lake without clear standards for partitioning, metadata, ownership, and quality checks becomes a low-trust storage layer fast. When bad records, late-arriving updates, or broken schemas enter the lake unnoticed, the problem rarely stays there. Those defects often flow into downstream marts and show up later as incorrect KPIs that look legitimate.
What a data mart is
A data mart is a curated, structured data store built for a defined business domain such as sales, finance, support, or operations. It contains transformed data shaped for repeated analysis, usually with agreed definitions, controlled dimensions, and stable metrics.
A mart works like packaged output for a known audience. The goal is speed, consistency, and clarity, not raw flexibility.
According to Dataversity's comparison of data marts and data lakes, data marts typically pull from internal transactional systems, while data lakes can combine internal and external data sources. That same Dataversity analysis also notes that data lakes are commonly used by data scientists working with raw data, while data marts are more often used by business stakeholders tracking predefined KPIs.
That distinction has practical consequences. A mart reduces ambiguity for the people making recurring decisions. It gives finance one definition of revenue, sales one accepted pipeline view, and operations one version of service-level performance. But every simplification in the mart is also a filtering decision. If the upstream transformation is wrong, incomplete, or based on dirty lake data, the mart can deliver polished answers that are consistently incorrect.
The simplest way to separate them
A quick test usually clarifies the role of each layer:
If the question is still changing or the data may need multiple future interpretations, start with a data lake.
If the business question is stable and asked repeatedly by a defined team, build or feed a data mart.
If the platform has to support both exploration and standardized reporting, use both, and treat the pipeline between them as a controlled production system.
Aspect | Data Lake | Data Mart |
|---|---|---|
Primary purpose | Store source data for future analysis and reuse | Deliver curated data for a specific business function |
Data form | Raw or lightly processed, mixed formats | Structured, cleaned, business-ready |
Typical users | Data engineers, data scientists, platform teams | Analysts, managers, business users |
Source coverage | Internal and external data | Usually selected business data prepared for a domain |
Best fit | Exploration, machine learning, historical retention | Reporting, dashboards, KPI tracking |
Architectural Deep Dive A Side by Side Comparison
The architecture gap between a lake and a mart isn't cosmetic. It affects ingestion design, transformation strategy, user access, failure modes, and operating cost.
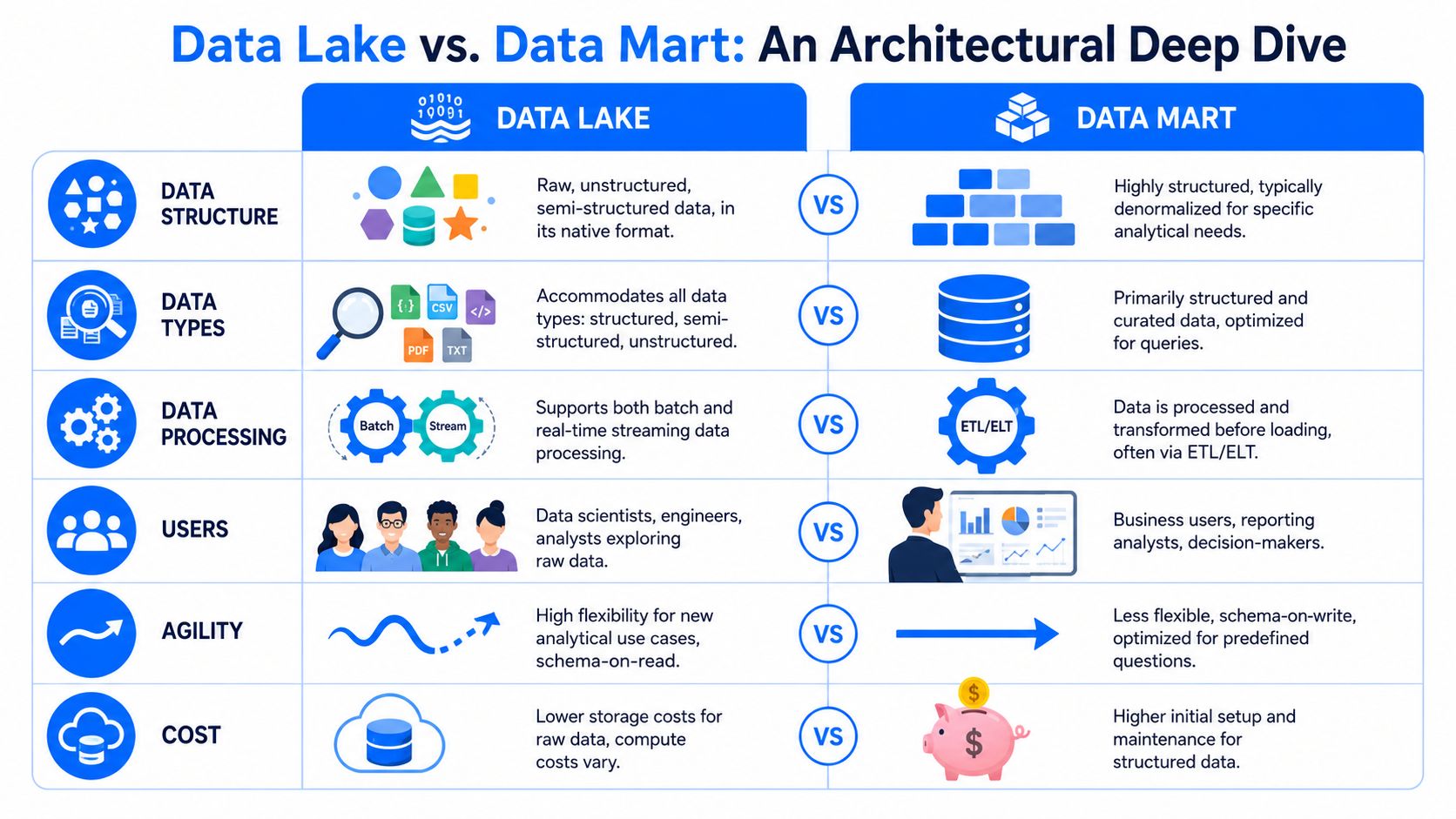
Schema and data modeling
The most important distinction is structural.
Data lake: schema-on-read
Data mart: schema-on-write
In a lake, the team stores data first and applies structure when it's accessed. In a mart, the team defines structure before or during loading so the stored result already matches the intended analytical model.
That difference matters more than most architecture diagrams admit. Schema-on-read gives you flexibility. You can ingest new event variants, additional fields, or mixed formats without redesigning the target every time. But that same flexibility pushes discipline downstream. Someone still has to define meaning, types, joins, and business logic later.
A mart does the opposite. It enforces order early. That makes downstream reporting easier because users query stable tables, often in dimensional models designed for a narrow subject area.
Processing style and transformation timing
Lakes usually support a load-first pattern. Raw data lands quickly, then engineers transform it later for specific analytical paths. Marts depend on prior curation. Data gets cleaned, typed, aligned with business definitions, and stored in a form that's ready for the questions the business already knows it will ask.
Teams often confuse “faster to ingest” with “faster to use.” A lake is faster to receive diverse data. A mart is faster to answer repeat business questions.
Scope and scale
A lake is broad by design. It can hold raw records from ERP, CRM, application logs, clickstream, third-party feeds, and machine-generated data in one place. It is built to scale across many formats and expanding volumes.
A mart is intentionally narrow. It's supposed to be smaller, focused, and aligned to one domain. Good marts say “no” to unnecessary detail.
User experience
This is one of the clearest dividing lines:
Lake users tend to be engineers, platform teams, and data scientists.
Mart users tend to be analysts, finance leads, operations managers, and dashboard consumers.
The interface may be SQL in both places, but the assumptions differ. In a lake, users often tolerate exploration, reconstruction, and ambiguity. In a mart, they expect stable semantics and consistent outputs.
Performance in practice
According to Yandex Cloud's comparison of data marts and data lakes, data lakes use schema-on-read while data marts enforce schema-on-write with dimensional models. The same source states that data marts can provide 2–5x faster read performance for BI because they restrict scope and optimize for pre-cleaned, predefined datasets.
That tracks with real platform behavior. A mart wins when many users ask familiar questions. A lake wins when teams need broad access to raw detail for varied analytics and machine learning workflows.
Practical rule: Optimize the lake for retention and flexibility. Optimize the mart for trust and speed.
Analyzing Performance Cost and Governance Tradeoffs
Most architecture debates become budget debates sooner than anyone expects. Storage looks cheap until transformation pipelines, BI performance tuning, data access controls, and support overhead start showing up in different teams' backlogs.
Cost isn't one line item
A lake usually makes financial sense when you need to retain lots of raw data and don't want to model every source before ingestion. You avoid forcing expensive structure onto data that may not even have a defined use case yet.
A mart shifts cost into design and maintenance. You're paying for curated models, controlled access patterns, and query performance that business users can rely on. That's usually the right trade when finance, sales, or operations teams need clean answers without rebuilding logic in every dashboard.
The mistake is comparing only storage. The complete cost picture includes:
Engineering effort: Who maintains ingestion, transformations, and metric definitions?
Query behavior: Are you paying for exploration or for repeated business access?
Rework: How often do teams rebuild logic because the original model was too rigid or too loose?
Performance depends on workload
If the workload is large-scale feature engineering, historical event reconstruction, or multi-format analysis, a lake is the natural fit. If the workload is recurring BI, a mart usually delivers a better user experience because fewer joins, tighter scope, and curated grain make queries easier to optimize.
That's also why many self-service BI initiatives stall. Business users do not want raw flexibility. They want governed data they can use safely. If your team is working on solving data team bottlenecks efficiently, the core lesson is the same: self-service works when the semantic layer and curated datasets are strong, not when everyone gets dropped into raw tables.
Governance changes shape with the architecture
Governance in a lake is harder because the data is broader, messier, and often less normalized. Security teams need to think about raw exposure, sensitive fields, unclear ownership, and metadata quality. You need strong cataloging, lineage, and access discipline or the lake becomes a dumping ground.
A mart has a different governance burden. It exposes business-ready numbers, so disputes become semantic instead of structural. Teams argue about definitions, refresh timing, and who owns the KPI logic.
Good governance in a lake prevents chaos. Good governance in a mart prevents political fights over whose number is “correct.”
Making the Right Choice for Your Use Case
A team usually reaches this decision under pressure. Product wants event-level history for future ML work. Finance wants fixed monthly numbers that will not move after close. The wrong choice does not just slow one project down. It creates rework in storage design, modeling, access control, and pipeline operations.

The practical answer starts with one question: are you optimizing for optionality or for repeatability?
Choose a data lake when future questions matter more than current convenience
A lake is the better starting point if the business is still learning what it needs from the data. That usually means multiple source types, changing schemas, long retention requirements, or analytical work that depends on fine-grained history.
Use a lake when:
You need to retain source-level detail from systems, event streams, APIs, logs, documents, or machine outputs.
Your ingestion model changes often and hardening every schema upfront would create delays and brittle pipelines.
You are supporting data science or ML and need raw history, not only curated aggregates.
You expect secondary use cases later such as audit reconstruction, anomaly analysis, or backfilling new models from old events.
This choice has an operational cost. Lakes preserve flexibility by accepting more ambiguity early. If metadata discipline is weak, teams pay for that later in debugging, lineage work, and data trust. That is why teams that adopt lakes also need clear standards for ownership, contracts, and data quality dimensions and how to measure them at scale.
Choose a data mart when the business needs stable answers on a schedule
A mart is the right fit when users are not asking open-ended analytical questions. They need a vetted slice of the business with agreed definitions, predictable refreshes, and query performance that holds up during heavy reporting windows.
Use a mart when:
A function needs governed metrics for recurring reporting, planning, or operational reviews.
Users need simple access paths instead of rebuilding joins and business logic on their own.
Semantic consistency matters more than raw breadth because decisions depend on one accepted version of the KPI.
The audience includes non-technical users who need confidence in the output more than modeling flexibility.
This is why finance, sales, and operations teams often ask for marts first. They are buying clarity and stability, not storage.
Do not treat a mart as the primary layer for machine learning
I see this mistake often. A team already has a clean mart, so it starts there for ML because the tables look easier to use. That convenience can subtly remove the raw signals that make models useful.
65% of enterprises attempt to use marts for ML, 20 to 25% of feature diversity is lost when marts pre-filter unstructured data, and 40% of AI models fail due to feature starvation when trained only on mart data, according to Atlan's analysis of data mart vs data lake for ML workloads.
Marts still have a role in ML. They are often a good serving layer for reporting on predictions, distributing scored outputs, or exposing stable features that have already been validated. They are a poor substitute for the raw training substrate when the model depends on behavioral detail, late-arriving signals, or new feature discovery.
In practice, mature teams use both and manage the dependency carefully
The strongest pattern is usually a lake upstream and marts downstream. The lake keeps the full record. The mart publishes a narrower, business-ready model for repeated use.
That relationship is useful, but it is also fragile. A mart can look polished while inheriting subtle defects from the raw data beneath it. If the lake accepts a type change, missing field, or delayed feed without detection, the mart may still refresh successfully and publish the wrong answer. Choosing both is often correct. Operating both well is the harder part.
The Hidden Risk Data Quality in Your Data Pipeline
Most “data lake vs data mart” articles make one major mistake. They describe the two as if they were isolated systems.
They aren't. In real deployments, the mart often depends on the lake. That means lake quality is not an upstream technical concern only. It is a business reliability concern.

Where the silent quality gap starts
A lake's schema-on-read flexibility is powerful, but it also creates a weak point. A source system adds a column. A type changes from integer to string. A timestamp starts arriving in a different format. A partner feed becomes late. The pipeline may still run, and the mart may still refresh, but the meaning of the resulting data has shifted.
That is the dangerous case. No obvious job failure. No crashed dashboard. Just wrong or incomplete numbers moving downstream with a green status indicator.
A broken pipeline gets attention. A successful pipeline with corrupted semantics is worse because people trust it.
This is not a theoretical edge case
Evidence from healthcare reuse pipelines makes the problem hard to ignore. According to JMIR Medical Informatics research on downstream failures caused by raw lake changes, unmonitored changes in raw lake data, such as added columns or type shifts, cause 30–40% of downstream data mart failures in those environments.
That matters beyond healthcare because the mechanism is universal. Raw ingestion changes. Transform logic makes assumptions. Downstream marts inherit the breakage, sometimes noisily, sometimes unnoticed.
What teams need to watch
The failure pattern usually shows up in a few areas:
Schema evolution: Added, removed, or retyped fields break transforms or alter joins.
Freshness drift: Late upstream arrivals produce stale marts that still look valid.
Value distribution shifts: Null rates, category balance, or outlier patterns change enough to distort business metrics.
Broken lineage assumptions: A supposedly stable upstream table no longer means what downstream logic expects.
If your team is building stronger controls around these issues, a practical reference on data quality dimensions and how to measure them at scale helps frame what should be monitored systematically rather than checked ad hoc.
Implementing Observability for Lakes and Marts
A team loads new source data into the lake on Monday, the nightly jobs stay green, and by Thursday the finance mart is reporting a margin drop that never happened. That is the operational problem observability has to solve. In a lake and mart architecture, job status is not enough. Teams need visibility into how raw changes propagate, where trust breaks, and whether the curated layer still reflects the business correctly.

What observability needs to cover in a lake
Lake monitoring has to work with messy inputs, incomplete metadata, and data that arrives before anyone has agreed on the final business meaning. That changes the control model. Static checks alone are rarely enough because the failure mode is often a shift in behavior, not a hard pipeline error.
In practice, the lake layer should watch for:
Ingestion anomalies so unexpected drops, spikes, or latency changes are caught early.
Schema drift so added fields, renamed columns, or type changes do not surprise downstream transforms.
Timeliness issues so delayed arrivals do not gradually age the marts that depend on them.
Distribution changes so null patterns, category balance, and outlier behavior are reviewed before they distort downstream outputs.
One practical lesson from operating lakes at scale is that alerting needs context. A column added to a raw event table may be harmless. A type change on a join key usually is not. Good observability separates noise from breakage by tying raw changes to downstream dependency and usage.
What observability needs to cover in a mart
Mart monitoring starts later in the pipeline but carries a different burden. Users trust marts because the data looks clean, labeled, and ready for decisions. That makes silent errors more dangerous here than in the raw layer.
Good mart monitoring usually includes:
Validation against business rules for field logic, valid ranges, and required constraints
Metric checks so KPI shifts are investigated before they reach planning meetings or executive reporting
Refresh monitoring to confirm each mart still meets its promised delivery window
Lineage-aware alerting so a bad number can be traced to the upstream table, transform, or assumption that caused it
Many implementations fall short. They verify that the mart refreshed, but they do not verify that the mart remained semantically correct after upstream change.
The operating model that actually works
The pattern that holds up in production is layered observability. Monitor ingestion in the lake. Monitor transformations between lake zones and serving models. Monitor the marts that decision-makers use. Each layer catches a different class of failure, and the gaps between layers are where bad data usually slips through.
Run those checks where the data already lives, especially in regulated or sensitive environments. Copying raw data into a separate monitoring stack creates extra exposure, extra cost, and another system to maintain. Teams comparing approaches should understand the difference between data observability and data quality practices, because one measures the health of the pipeline and the other defines what "good" data should mean in context.
Operating advice: If the lake feeds the mart, your alerts should follow the same path. Check the handoffs, dependency points, and semantic assumptions, not just the endpoints.
If your team needs a practical way to detect anomalies, validate records, track timeliness, and catch schema changes across both lakes and marts, digna is built for that job. It runs analyses inside your own environment, supports private cloud and on-prem deployment, and gives engineers and stakeholders one place to inspect the health of the data pipeline before bad data reaches dashboards, reports, or ML systems.



