Dlaczego zadania Databricks stają się nieprzewidywalne - i jak zespoły wcześnie wykrywać niestabilność
|
5
min. czyt.

Databricks środowiska są zbudowane z myślą o elastyczności. Klastry skalują się, obciążenia ewoluują, a wolumeny danych rosną nieustannie. Ta elastyczność jest potężna; jednak wprowadza również wyzwanie, z którym wiele przedsiębiorstw ostatecznie się boryka:
Zadania, które kiedyś działały przewidywalnie, zaczynają zmieniać się pod względem czasu wykonywania, użycia DBU i kosztów.
Rurociągi nadal są udane. Tablice są nadal aktualizowane. Nic nie wydaje się „zepsute”. Jednak przewidywalność operacyjna eroduje.
Zrozumienie, dlaczego tak się dzieje i jak to wykryć na wczesnym etapie, jest kluczowe dla zespołów używających Databricks jako produkcyjnej platformy danych i AI.
Niestałość w Databricks Dotyczy Zachowania, Nie Awarii
W tradycyjnych systemach niestałość często oznaczała przeciążenie systemu lub limity sprzętu. Niestałość Databricks jest inna.
Ponieważ klastry automatycznie się skalują, a obciążenia rozdzielają się dynamicznie, niestałość przejawia się jako:
Wzrost zużycia DBU dla tych samych zadań
Zwiększenie zmienności w czasie trwania wykonania
Nieprzewidywalna wydajność zadań
Częstsze zdarzenia zmiany rozmiaru klastrów
Zadania mogą być pomyślnie zakończone, ale ich zachowanie zmienia się z czasem. Te zmiany są często niewidoczne na tablicach skoncentrowanych wyłącznie na sukcesie/awarii.
Co Powoduje, że Zadania Databricks Stają się Nieprzewidywalne?
1. Wzrost Danych Zmienia Plany Wykonania
W miarę jak wolumeny danych rosną:
Zwiększa się ilość przetasowań
Połączenia stają się cięższe
Strategie partycjonowania pogarszają się
Efektywność buforowania zmienia się
Nawet bez zmian w kodzie, plany wykonania Spark przesuwają się. To prowadzi do większego zużycia DBU i dłuższych czasów działania.
Zadanie nadal „działa”, ale zużywa więcej zasobów obliczeniowych niż wcześniej.
2. Drift Logiki w Notatnikach i Rurociągach
Obciążenia Databricks ewoluują szybko.
Zespoły dodają:
Dodatkowe połączenia
Dodatkowe agregacje
Nowe obliczenia cech ML
Szersze filtry
Każda modyfikacja dodaje obciążenie. Indywidualnie, zmiany wyglądają na niewielkie. Z biegiem miesięcy zasadniczo zmieniają zachowanie obciążenia.
3. Automatyczne Skalowanie Maskuje Problemy z Zasobami
Automatyczne skalowanie to zarówno siła, jak i ślepy punkt.
Kiedy obciążenia wymagają więcej zasobów obliczeniowych:
Klastry rozszerzają się automatycznie
Zadania kończą się pomyślnie
Koszty rosną po cichu
Zamiast kończyć niepowodzeniem, system absorbuje nieefektywności — ukrywając regresje wydajności za elastyczną infrastrukturą.
Pierwszy sygnał często pojawia się jako wzrost zużycia DBU, nie jako błąd.
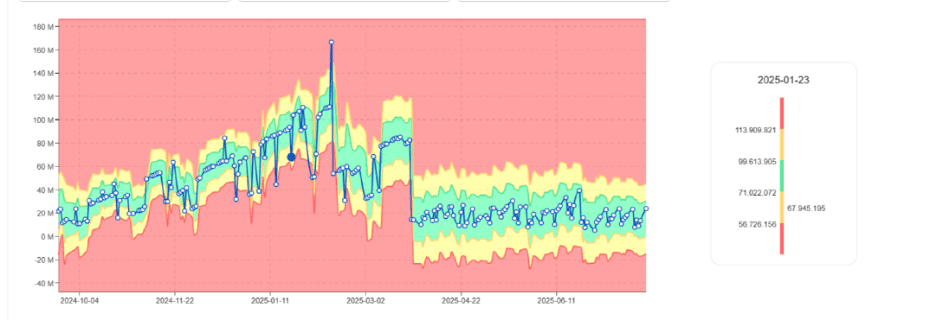
Tendencja wzrostu zużycia DBU stopniowo rośnie dla tego samego zadania
4. Nierównowaga Skewu i Przetasowania
Skew danych powoduje, że niektóre zadania przetwarzają nieproporcjonalne ilości danych.
W Databricks przejawia się to jako:
Długotrwałe zadania
Zwołania
Zwiększona zmienność czasu trwania etapu
Ponieważ Spark dynamicznie rozdziela zadania, skew prowadzi do niestabilnych czasów działania i nieprzewidywalnego zużycia DBU.
5. Zachowanie Retry i Ukryte Awaria
Powtórzenia zadań są powszechne w systemach rozproszonych.
Przejściowe problemy, nacisk na pamięć lub utrata wykonawcy mogą wywołać powtórzenia, które:
Zwiększają czas działania
Nadmiernie zwiększają zużycie DBU
Dodają zmienności
Zadania się udają, ale niestabilność się zwiększa.
6. Sezonowość w Obciążeniach
Databricks jako prace często odzwierciedlają cykle biznesowe:
Przetwarzanie na koniec miesiąca
Szczyty raportowania tygodniowego
Harmonogramy ponownego trenowania modeli
Bez modelowania tych wzorców, zespoły albo ignorują anomalie, albo są przytłoczone fałszywymi alarmami.
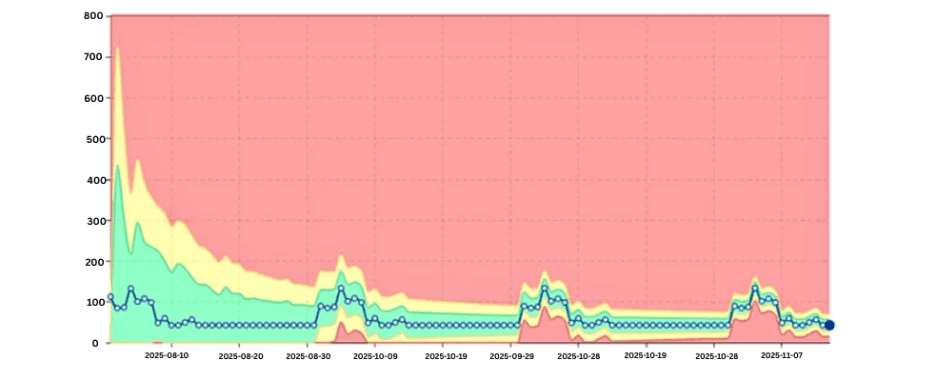
Sezonowy wzorzec DBU z oczekiwanymi szczytami
Dlaczego Tradycyjne Monitorowanie Omija Wczesne Sygnały
Większość zespołów polega na:
Miernikach sukcesu/niepowodzenia zadań
Tablice kosztów
Widoki wykorzystania klastrów
Te narzędzia pokazują wyniki, nie zmiany zachowań.
Nie ujawniają one:
Zadań stających się droższymi z czasem
Rosnącej zmienności w czasie realizacji
Strukturalnych zmian w sposobie wykonania obciążeń
Niestabilność zaczyna się na długo przed przekroczeniem progów.
Przechodzenie na Monitorowanie Zachowawcze
Wczesne wykrywanie niestabilności wymaga analizy jak obciążenia zachowują się w czasie, a nie tylko czy odnoszą sukces.
Kluczowe sygnały obejmują:
Trendy zużycia DBU
Ewolucję czasu wykonania
Zmienność w czasie trwania zadania
Częstotliwość skalowania klastrów
Przekształcając te metryki w dane sekwencji czasowych, zespoły mogą zidentyfikować dryf, zmienność i zmiany strukturalne.
Wczesne Wykrywanie Niestabilności
Poznaj Normalne Zachowanie Zadań
Zamiast sztywnych progów DBU, nowoczesne podejścia poznają:
Typowy zakres DBU dla zadania
Oczekiwane wzorce czasów trwania
Normalne zachowanie klastrów
W miarę jak obciążenia stabilizują się, akceptowalne zakresy zachowania się zawężają.
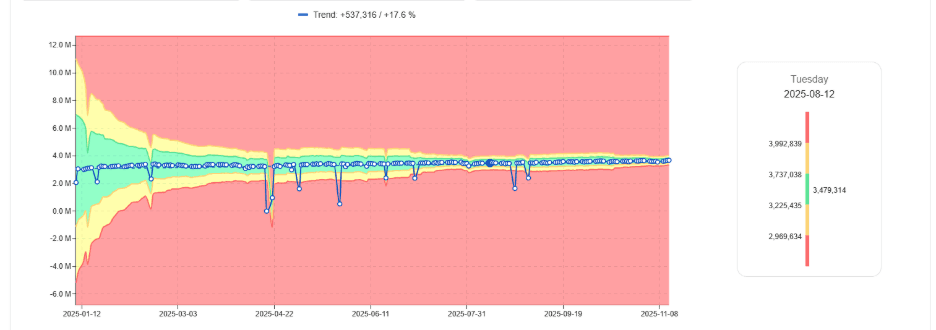
Poznany normalny pasmo DBU zawężający się z czasem
Wykrywanie Powolnego Driftingu DBU
Jednym z największych kosztowych czynników jest powolny wzrost DBU.
Porównując bieżące zużycie z podstawowymi poziomami historycznymi, zespoły mogą zidentyfikować, które zadania zużywają coraz więcej zasobów obliczeniowych.
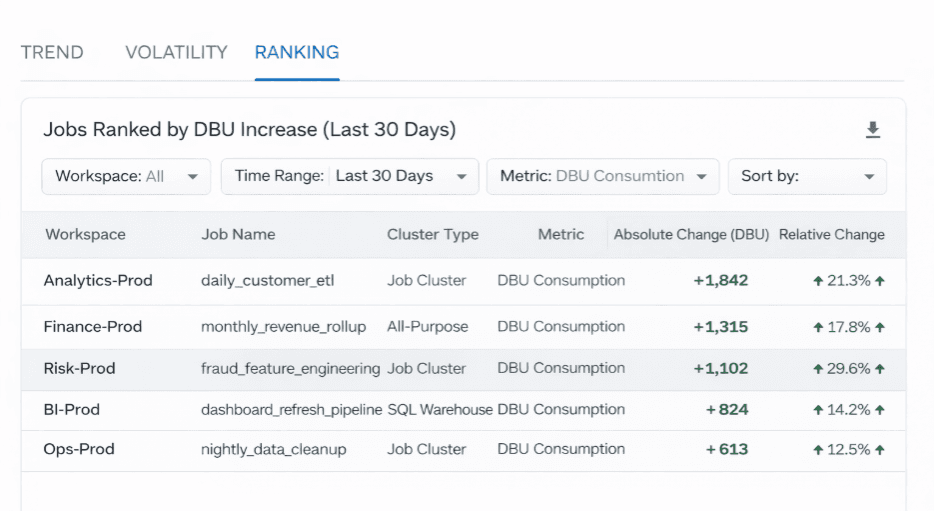
Zadania uporządkowane według miesięcznego wzrostu DBU
Mierzenie Zmienności Czasu Wykonania
Nawet jeśli średni czas wykonania pozostaje stały, wysoka zmienność sygnalizuje niestabilność.
Niestabilne zadania są trudniejsze do planowania i bardziej prawdopodobne, aby spowodować opóźnienia w łańcuchu.
Uwzględnianie Sezonowości
Systemy behawioralne odróżniają oczekiwane cykliczne szczyty od rzeczywistych anomalii, zmniejszając hałas alertów.
Gdzie Pasuje digna
digna analizuje metryki obciążeniowe Databricks, takie jak zużycie DBU, czas wykonywania i zachowanie wolumenu w czasie. Zamiast stałych ograniczeń, wykorzystuje AI do poznawania normalnych wzorców i wczesnego wykrywania niemożliwych odchyleń — zarówno nagłych skoków, jak i stopniowego dryftu.
Pozwala to zespołom na identyfikowanie problemów, zanim pojawią się w raportach kosztowych lub naruszeniach SLA.
Więcej na temat podejścia opartego na anomaliach można znaleźć:
digna Data Anomalies | Oglądaj Demo
Dlaczego Wczesne Wykrywanie ma Znaczenie
Kiedy niestabilność jest wykrywana wcześnie, organizacje mogą:
Optymalizować zapytania, zanim koszty się eskalują
Stabilizować rurociągi, zanim SLA zostaną naruszone
Zmniejszyć gaszenie pożarów
Poprawić przewidywalność dla zespołów FinOps
Końcowa Myśl
Databricks zadania rzadko zawodzą całkowicie. Stają się nieprzewidywalne.
Ta nieprzewidywalność jest widoczna w zmieniającym się zachowaniu DBU, zmienności czasów działania i ewoluujących wzorcach wykonania, sygnałach, które statyczne monitorowanie nie jest w stanie wychwycić.
Zespoły, które przyjmują monitorowanie zachowawcze, uzyskują wczesny wgląd w niestałość, utrzymując kontrolę, gdy ich środowiska Databricks się skalują.




Poznaj zespół tworzący platformę
Zespół z Wiednia, składający się z ekspertów od AI, danych i oprogramowania, wspierany rygorem akademickim i doświadczeniem korporacyjnym.