Enterprise Data Platform: A 2026 Guide to Architecture
|
6
minute de lecture

Your dashboards look green, but the revenue table is six hours late. A model that worked last week starts returning poor results because one upstream column changed type overnight. The BI team blames ingestion, the data engineering team blames source systems, and leadership still expects a reliable number in the morning.
That's the current state of many enterprise environments. The problem usually isn't a lack of tools. It's that the platform was built to move and store data, not to continuously prove that the data is still correct, timely, and safe to use. In practice, a modern enterprise data platform only works when quality controls and observability are part of the platform itself, not bolted on after the first incident.
Table of Contents
What Is an Enterprise Data Platform
An enterprise data platform is not one product. It's the operating architecture that lets an organization ingest, store, transform, govern, monitor, and serve data across many systems without losing trust in what the data means.
The simplest way to think about it is as the central nervous system for business data. Source systems generate signals. Pipelines move them. Storage layers preserve them. Compute engines shape them. Governance defines who can use what. Quality and observability tell you whether the whole system is still behaving as expected.
That distinction matters because many teams still confuse a warehouse account, a lake bucket, or an orchestration tool with the platform itself. Those are components. The platform is the coordinated system that makes data usable at enterprise scale across BI, operations, analytics engineering, and AI workloads.
Practical rule: If your team can't answer “Is this data current, structurally valid, and safe to use?” without opening five different tools, you don't have a mature platform yet.
Most organizations reach for an enterprise data platform after the same set of failures. Metrics disagree between teams. Dashboards break after unnoticed schema changes. Data scientists train on inputs that drifted weeks ago. Security and governance teams discover too late that sensitive data crossed a boundary it shouldn't have crossed.
The strategic importance is no longer debatable. The big data platform market was valued at USD 101.55 billion in 2026 and is expected to reach USD 314.35 billion by 2035, expanding at a CAGR of 13.38%, and advanced platform users are 2.5x more likely to outperform competitors in revenue growth, according to Business Research Insights on the big data platform market.
That growth doesn't mean every platform is working well. It means enterprises now recognize they need a system that can support both classic reporting and newer AI-driven use cases. The hard part is that AI raises the standard. A stale dashboard is embarrassing. A model trained on subtly corrupted inputs can trigger bad decisions at scale.
A functional enterprise data platform creates one discipline out of many moving parts. It gives teams a way to integrate diverse sources, enforce policy, trace lineage, detect breakage early, and deliver trusted data products without relying on tribal knowledge.
The Core Components of a Modern EDP
A modern enterprise data platform has five working layers. If one is weak, the rest of the stack starts compensating for it.

Why the storage layer isn't the platform
Start with data ingestion. This layer pulls data from operational databases, SaaS applications, event streams, flat files, APIs, and partner systems. Good ingestion supports both batch and incremental movement. Bad ingestion creates hidden latency, duplicate loads, and inconsistent semantics before data even lands.
Next is data storage. That may be a warehouse, a lake, or a combination of both. Storage has to accommodate structured and unstructured data while preserving enough fidelity for downstream reprocessing. Teams often overspend here because they choose a storage pattern before they define consumption patterns.
Then comes processing and transformation. In this stage, raw data becomes usable data. Compute engines handle cleansing, enrichment, joins, conforming dimensions, business logic, and delivery-ready models. If transformations are undocumented or scattered across teams, the platform starts producing contradictory versions of the same metric.
A fourth layer is governance and security. This includes access control, data classification, policy enforcement, retention boundaries, and lineage visibility. In regulated environments, this layer often determines the deployment model more than cost does. The enterprise data management market is projected to reach USD 225.97 billion by 2031, and on-premises and private cloud deployments still hold a 55.00% revenue share, reflecting the preference for environments where customer data remains private and vendor access is restricted, especially in finance and healthcare, according to Mordor Intelligence on enterprise data management.
For teams designing this stack, practical implementation details matter more than vendor diagrams. A good reference point is this overview of data platform engineering, especially when you need to align ingestion, compute, governance, and operational controls instead of treating them as separate purchases.
The quality control layer most teams add too late
The fifth layer is where modern platforms either become reliable or stay brittle. It includes data validation, schema tracking, and observability.
These are not the same thing:
Validation checks whether records meet explicit business rules.
Schema tracking catches structural change, such as added columns, removed fields, or type changes.
Observability looks at behavior over time, including freshness, volume shifts, null spikes, drift, and anomalous patterns.
A practical way to map these layers is below.
Component | What it does | What breaks without it |
|---|---|---|
Ingestion | Moves data from source systems | Late loads, duplicates, hidden gaps |
Storage | Holds raw and curated data | Reprocessing pain, fragmented access |
Processing | Applies business logic | Metric inconsistency, brittle pipelines |
Governance | Enforces policy and access | Compliance risk, uncontrolled usage |
Quality and observability | Detects data issues in motion | Silent drift, stale reporting, broken AI inputs |
The platform isn't healthy because jobs finished. It's healthy when the data is correct, timely, and explainable after the jobs finish.
That's the shift many teams are still making. Monitoring infrastructure tells you whether a pipeline ran. Observability tells you whether the output can be trusted.
Key Architecture Patterns and Their Trade-Offs
Architecture choices shape operating pain for years. The mistake isn't choosing the wrong buzzword. It's choosing a pattern that doesn't match your team structure, governance model, and latency needs.
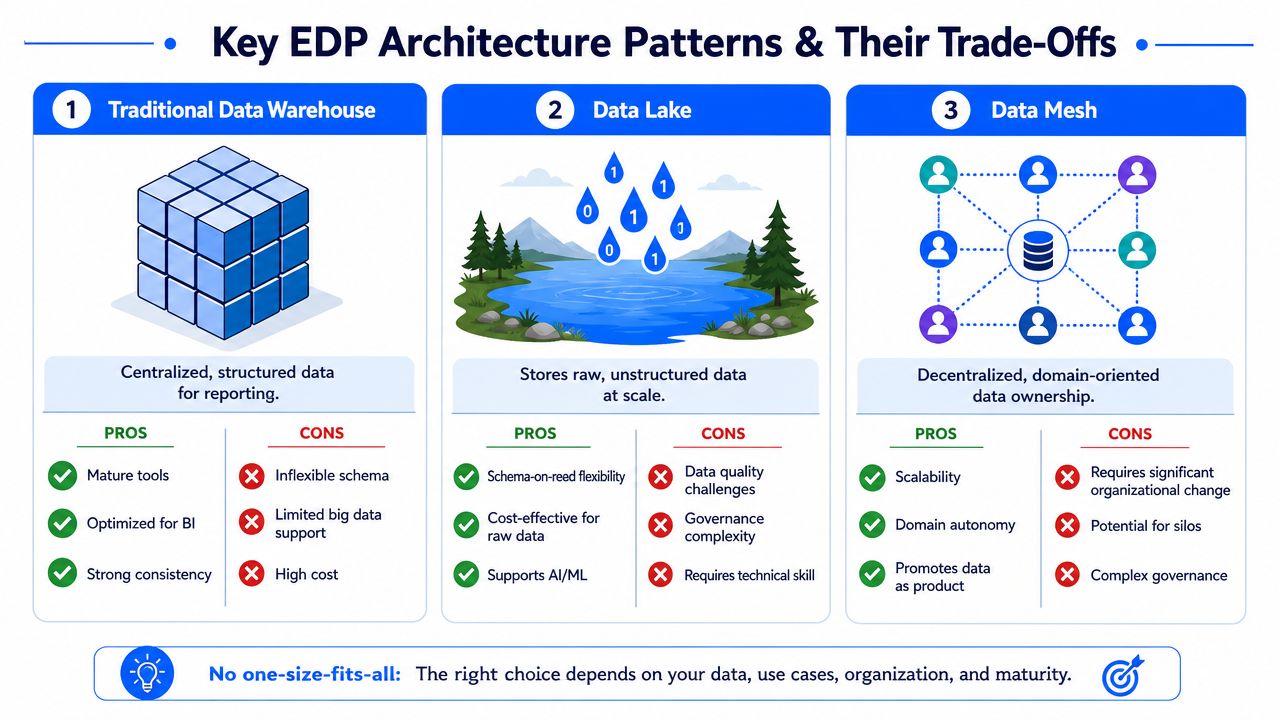
Where each pattern works
A traditional data warehouse still works well when reporting consistency matters more than flexibility. Finance, executive reporting, and governed KPI delivery often fit here. Warehouses give you mature BI integration and strong control, but they become restrictive when teams need to store raw, semi-structured, or rapidly changing data.
A data lake gives you cheaper raw storage and more freedom for AI and ML exploration. The trade-off is operational discipline. Without strong metadata, quality controls, and ownership, the lake fills with low-trust assets that nobody wants to use in production.
A lakehouse often lands in the middle. It tries to combine warehouse-style governance with lake-style flexibility. In practice, this is often the right fit for organizations that want one broad platform for analytics, data science, and shared domain datasets without fully decentralizing ownership.
A data mesh is not a storage technology. It's an organizational model. It can work when domains have real engineering maturity and can own data products end to end. It fails when central standards are weak or when “domain ownership” becomes an excuse for fragmented semantics.
If you're evaluating how structured modeling should work inside any of these patterns, PlotStudio AI's piece on data warehouse design principles is useful because it grounds architecture decisions in modeling discipline rather than platform marketing.
Here's the practical comparison teams usually need:
Pattern | Best fit | Main strength | Main risk |
|---|---|---|---|
Data warehouse | Standardized reporting | Consistency | Rigidity |
Data lake | Raw scale and experimentation | Flexibility | Weak trust |
Lakehouse | Mixed analytics and AI workloads | Balance | Tooling complexity |
Data mesh | Large federated organizations | Domain ownership | Governance fragmentation |
For complex platform planning, a clean data architecture diagram can save weeks of confusion because it forces teams to define movement paths, control points, and ownership boundaries before implementation starts.
Real-time patterns change the design
Batch-only thinking breaks down once the business expects current data. Fraud detection, operational monitoring, inventory updates, and customer-facing applications often need low-latency movement.
According to Gable's analysis of data platform architecture patterns, modern enterprise data platforms that combine batch and speed layers using event-driven architecture and stream processing frameworks like Apache Flink can ensure both data integrity and low-latency updates, which is exactly why more teams are building dual-path systems instead of replacing batch entirely.
That trade-off is worth being candid about:
Batch paths are easier to reason about, backfill, and audit.
Streaming paths reduce latency but increase operational complexity.
Dual-path designs often work best, but only if reconciliation rules are explicit.
If you add streaming, add stronger controls. Low latency exposes data problems faster. It doesn't remove them.
The architecture pattern should follow the operating model. Teams with a small platform group and heavy governance demands usually do better with central control. Large organizations with strong domain engineering capabilities can push more ownership outward, but only if they invest in shared standards, metadata, and quality enforcement.
Choosing Your Deployment Model
Most deployment debates get framed as cost conversations. In reality, they're usually about control, privacy, operating burden, and where your compliance team draws the line.

What on-prem gives you
On-premises deployment still makes sense when data residency, internal security posture, or vendor access restrictions are absolute requirements. Teams in finance, healthcare, and parts of the public sector often choose this route because they need hard boundaries around customer data and stronger internal control over infrastructure changes.
The trade-off is obvious. You own capacity planning, patching, hardware lifecycle, and more of the operational stack. If the internal platform team is thin, on-prem can become a queue of delayed upgrades and local workarounds.
That said, control has value when privacy matters more than convenience. Some organizations would rather accept slower procurement and infrastructure management than move critical datasets into a model they can't fully inspect.
Where cloud and hybrid make sense
Public cloud works well when demand is elastic, teams need fast provisioning, and the business can tolerate dependency on provider-native services. It's often the shortest path to experimentation, especially for analytics and AI teams that need storage and compute without waiting for central infrastructure cycles.
The catch is that easy provisioning can hide messy economics and governance drift. Data gets copied too many times. Teams choose managed services that are painful to unwind later. Security policies become inconsistent across accounts and regions.
Hybrid is often the practical answer, not the elegant one. Sensitive datasets stay in private environments. Less restricted workloads scale in cloud infrastructure. The design challenge is keeping governance and operational visibility consistent across both.
According to the State of Modern Data Architecture benchmark report summarized by Dataforest, enterprise data platforms must be architected to handle 10x current data volumes without performance degradation, and that requires cloud-native flexibility and auto-scaling features that let domain teams self-serve without creating central bottlenecks.
A simple comparison helps clarify the choice:
On-premises fits strong control requirements, stable workloads, and strict data boundary policies.
Public cloud fits elasticity, faster provisioning, and broad service access.
Hybrid fits mixed regulatory environments and phased modernization.
The deployment model should also match your observability design. A privacy-preserving platform that runs in customer-controlled infrastructure can be a better fit than a tool that requires broad data extraction just to monitor quality. That's especially relevant when security teams won't approve vendor access to production data.
Deployment decisions age badly when teams optimize only for this year's budget and ignore next year's governance burden.
The best deployment model is the one your team can operate consistently under real constraints, not the one that looks cleanest in a reference architecture.
Why Data Quality and Observability Are Non-Negotiable
A platform can have elegant storage, clean pipelines, and expensive compute, yet still fail the business because nobody knows when the data went stale, drifted, or changed shape. That's why quality and observability are now core platform functions.
Bad data fails quietly
Infrastructure alerts are noisy. Data failures are often quiet. A job succeeds but loads incomplete records. A source system keeps sending rows, but key fields shift distribution. A late file arrives after downstream reports have already refreshed.
That's why AI raises the stakes. Models don't complain when training inputs are subtly wrong. Retrieval pipelines don't announce that a document feed stopped updating. They just return lower-quality outputs and make root cause analysis harder.
The urgency is clear in one projection. While 87% of enterprises call data observability essential for AI, 99% of enterprise data remains untapped for AI training due to unverified quality gaps, according to SiliconANGLE on AI-native enterprise data resilience. That same analysis points to in-database anomaly detection and schema tracking as practical ways to protect model integrity.
The operational lesson is simple. If your enterprise data platform doesn't continuously test freshness, structure, and behavioral change, your AI stack inherits unknown risk.
A useful distinction many teams miss is the one covered in this guide to data observability vs data quality. Quality asks whether data meets expectations. Observability asks whether the system can detect when those expectations stop being true.
What integrated observability looks like
Modern observability should cover at least four failure modes.
Timeliness drift. Data arrives later than expected, even if the pipeline eventually completes.
Schema change. Columns appear, disappear, or shift type without a coordinated release.
Behavioral anomalies. Metrics deviate from learned baselines, including null rates, distribution changes, and unexpected volume shifts.
Business rule violations. Specific records fail known validation logic.
Platform design matters more than tool count. If anomaly detection requires analysts to hand-maintain hundreds of static rules, it won't scale. If every validation check requires exporting sensitive data into a vendor-managed environment, privacy teams will block adoption.
AI-based anomaly detection can reduce that manual overhead. According to digna's overview of AI anomaly detection techniques, platforms can use unsupervised methods such as Isolation Forests and autoencoders to learn normal behavior, including seasonality and trends, and then set adaptive thresholds without manual rule maintenance.
That approach is especially useful in enterprise settings where tables are numerous, patterns shift over time, and teams can't afford endless threshold tuning. One example is digna, which runs analyses inside customer databases and supports anomaly detection, timeliness monitoring, record-level validation, and schema tracking in private cloud or on-prem environments. That model is often a better fit for regulated teams because it reduces data movement and avoids vendor access to production datasets.
“A passed pipeline isn't the same thing as trustworthy data.”
Teams that treat observability as an add-on usually end up with fragmented incident response. Engineering checks orchestration logs. Analysts inspect dashboards. Governance reviews lineage after the fact. Integrated observability shortens that loop because freshness, structure, and data behavior are inspected where the platform already operates.
How to Select the Right Enterprise Data Platform
Buying an enterprise data platform is less about feature lists and more about what the platform forces your team to own. Some tools look complete in a demo because they hide the operational work behind polished screens. The hard questions are about integration boundaries, governance behavior, and how the system handles failure.

Questions that expose platform reality
Ask vendors and internal stakeholders questions that make architecture concrete.
Where does computation happen
If checks, transformations, or profiling require excessive data movement, cost and privacy risk go up quickly.How does the platform behave in hybrid environments
This matters more than many buyers expect. According to Forbes on AI and open source in enterprise data platforms, a key challenge is decentralized data governance in hybrid environments, and the market is projected to double to $243.5B by 2032. The same analysis argues that enterprises need ways to monitor timeliness and enforce policy across private cloud and on-prem systems without vendor data access.Can it monitor expected delivery times, not just job completion
A pipeline can succeed and still arrive too late for decision-making.
Before final selection, it helps to see one broad implementation perspective in motion:
What does governance look like outside the happy path
Ask how the platform handles lineage gaps, policy exceptions, and cross-domain ownership disputes.How much manual rule maintenance is required
If the answer is “your analysts define everything by hand,” expect operational drag.
A short buyer checklist helps separate useful platforms from expensive assemblies of partial tools:
Integration reality: Does it connect cleanly to your warehouse, lake, orchestration layer, and identity model?
Operational visibility: Can engineering and business teams see freshness, drift, and schema change in one place?
Privacy posture: Can the platform operate in customer-controlled environments if required?
Scalability path: Will the architecture still work after major volume growth and domain expansion?
Common buying mistakes
The most common mistake is buying for current architecture only. Enterprises rarely stay on one storage pattern, one cloud, or one governance model. The platform has to survive mergers, regional compliance demands, and changes in team structure.
Another mistake is underestimating the cost of fragmented tooling. One product for ingestion, one for quality, one for monitoring, one for lineage, and one for governance can work. But only if the team has the discipline to keep ownership and incident response coherent. Many don't.
Key takeaway: Don't ask whether a platform can ingest and query data. Ask whether your team can trust and govern the data six months after the initial rollout.
The right enterprise data platform is the one that fits your operating constraints, not the one with the longest product page.
Building a Future-Proof Data Foundation
A strong enterprise data platform doesn't just centralize data. It creates a controlled environment where data can be trusted under pressure. That means architecture choices matter, deployment choices matter, and platform ownership matters. But the systems that hold up over time all share one characteristic. They treat data quality and observability as built-in controls, not optional extras.
That shift changes how teams work. Data stops being a recurring source of debate and starts becoming a usable asset for reporting, operations, and AI. Privacy also becomes easier to manage when analysis stays in customer-controlled environments and governance isn't separated from execution.
The future-proof platform is not the most complex one. It's the one that can scale, adapt to hybrid reality, protect sensitive data, and surface problems before they damage trust. That's the foundation enterprises need if they want AI systems, dashboards, and operational decisions to run on data they can rely on.
If you're rethinking how quality and observability fit into your enterprise data platform, digna is worth evaluating. It focuses on anomaly detection, record validation, timeliness monitoring, and schema tracking inside customer-controlled environments, which makes it relevant for teams that need stronger data reliability without handing production data to a vendor.



