Analyse des charges de travail modernes sur Teradata Vantage avec digna : optimisation pilotée par l'IA pour l'efficacité du CPU, des E/S et des coûts
|
7
minute de lecture

Teradata Vantage reste l'une des plateformes les plus importantes pour l'analyse d'entreprise à grande échelle car elle est puissante, évolutive et éprouvée. Mais à mesure que les charges de travail se complexifient, les équipes font face à un défi constant:
Comment surveiller en continu les tendances CPU, IO, de skewness et de charge de travail sans vérifications manuelles, des dizaines de requêtes SQL, ou la lutte contre les incendies post-incidents ?
C'est là que digna fournit une amélioration significative.
En lisant les tables système DBC de Teradata, en les convertissant en métriques intelligentes de séries chronologiques, et en appliquant la détection d'anomalies basée sur l'IA, digna donne aux équipes d'ingénieurs une vue automatisée en temps réel du comportement de la charge de travail sans exporter de données et sans maintenir des règles manuellement.
Cet article explique comment digna améliore la gestion de la charge de travail Teradata en utilisant l'IA, comment il détecte les anomalies CPU/IO, et comment les organisations peuvent utiliser digna pour réduire les risques, améliorer la stabilité, et réduire les coûts.
Pourquoi digna est un complément naturel pour la surveillance de la charge de travail Teradata
Teradata demeure l'une des plateformes analytiques les plus stables et fiables. digna complète la fiabilité de Teradata en fournissant :
Apprentissage des tendances basé sur l'IA
Pas de seuils. Pas de règles. digna apprend automatiquement à quoi ressemblent les modèles de CPU, d'IO, d'utilisation de perm et de charge de travail « normaux ».
Détection d'anomalies en temps réel
Dès qu'un travail dévie des valeurs attendues, digna le signale—avant qu'il ne devienne un problème à l'échelle du système.
Visibilité de la charge de travail de bout en bout
Toutes les informations sont générées à l'intérieur de Teradata, en utilisant :
Tables DBC
AMPCPUTime
Histogrammes IO
Usage de perm
Métriques de skew
Données QryLog
Tables DBQL
Alertes là où les équipes travaillent
Email, Slack, Jira, et notifications basées sur des modules garantissent que les problèmes ne sont jamais manqués.
Zero mouvement de données
Tous les calculs sont effectués à l'intérieur de la base de données - seuls les métriques quittent le système.
Comment digna apprend le comportement de la charge de travail Teradata
digna commence par collecter des métriques opérationnelles directement à partir de Teradata via des requêtes SQL exécutées dans votre environnement. Rien ne quitte votre système à l'exception des métriques calculées elles-mêmes. Mais ceci n'est que le début — l'intelligence réelle se produit lorsque digna transforme ces signaux bruts en profils comportementaux évolutifs.
Au lieu d'apprendre dans la base de données, digna achemine ces métriques vers le moteur IA de digna, où les modèles s'adaptent en continu à la manière dont votre système Teradata se comporte au fil du temps. Cela permet à digna de comprendre non seulement les points de données individuels, mais aussi les modèles : comment le CPU augmente pendant la journée de travail, comment l'IO se comporte lors des lots nocturnes, et comment les charges de travail fluctuent sur des semaines ou des mois.
Contrairement aux outils de gestion de charge de travail traditionnels qui nécessitent la configuration de règles, la plateforme apprend automatiquement la saisonnalité quotidienne, hebdomadaire et mensuelle. Par exemple:
Augmentation de l'utilisation du CPU chaque lundi
Charge IO supplémentaire le 10ème jour de chaque mois
Pics de fin de mois qui sont normaux pour votre organisation
En reconnaissant vos rythmes opérationnels naturels, digna peut précisément séparer les cycles attendus des véritables anomalies. C'est ainsi que digna évite les fausses alertes, se concentre sur les déviations significatives, et vous donne une compréhension continuellement adaptative de la santé des charges de travail.
Apprentissage des tendances AMPCPUTime
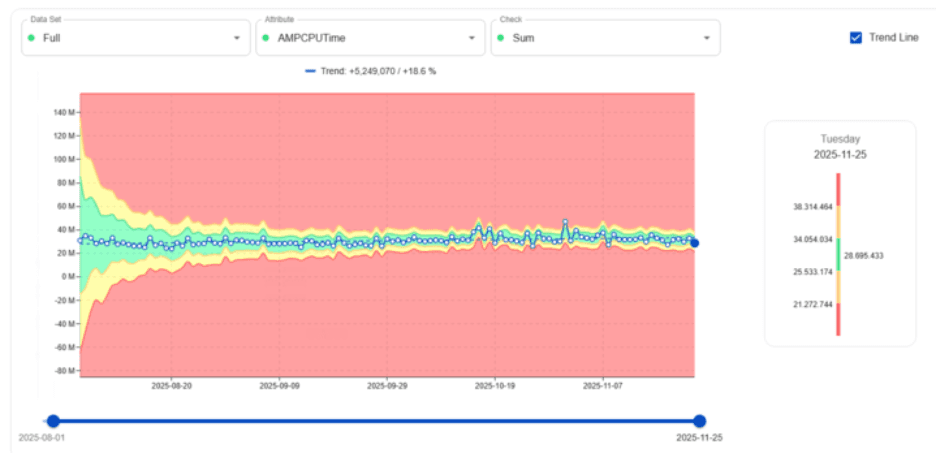
L'un des exemples les plus puissants est la façon dont digna apprend AMPCPUTime pour l'ensemble du système Teradata.
Au début, la plage acceptée (en vert) est large car digna observe encore la variabilité. Avec le temps, plus la consommation se stabilise, plus la zone verte se rétrécit. Cette bande plus étroite signifie que digna comprend exactement à quoi ressemble un CPU « sain » — afin qu'il puisse signaler les anomalies réelles avec une grande précision.
Valeur clé : digna réduit les escalades liées au CPU et aide les équipes à anticiper les charges de travail croissantes avant qu'elles ne causent des incidents.
Détection précoce des aberrations IO
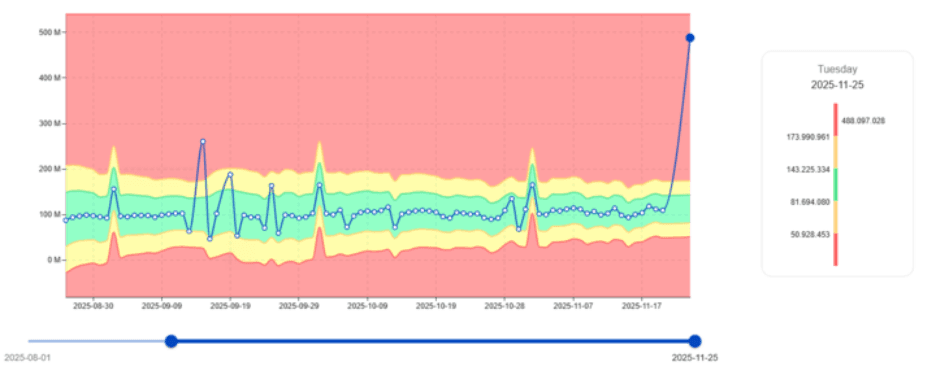
Les pics IO sont parmi les premiers indicateurs de charges de travail problématiques.
Dans l'exemple que vous ajouterez ici, digna identifie un travail qui montre soudainement un IO bien au-delà de son schéma normal - même si le CPU peut sembler normal.
Cette détection précoce permet aux équipes d'enquêter sur :
Changements de distribution des données
Scans de tables
Jonctions déséquilibrées
Croissance inattendue des données
Logique de charge de travail non optimisée
Valeur clé : digna aide les équipes à éviter les goulets d'étranglement IO qui ralentissent l'ensemble du système.
Identification des consommateurs de CPU instables
Certains travaux ne se comportent pas de manière cohérente. Certains montrent une volatilité inattendue de l'utilisation du CPU qui, avec le temps, conduit à une instabilité du cluster.
L'image ci-dessous montre comment digna met en évidence ces anomalies.
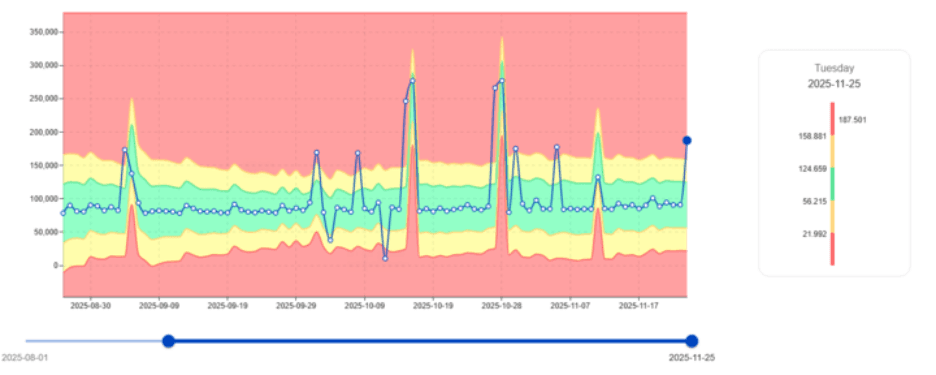
Les charges de travail CPU volatiles indiquent souvent :
Mauvais plans de requête
Changements de modèle de données
Optimisations sensibles aux paramètres
Dérive de la taille des tables
Déséquilibre dans les jonctions ou les agrégations
Avec digna, ces schémas sont détectés bien avant qu'ils ne deviennent un incident majeur.
Valeur clé : digna met à jour les charges de travail bruyantes tôt, permettant une optimisation du CPU qui réduit directement les coûts de licence et d'infrastructure.
Détection de l'instabilité soudaine du CPU dans les travaux critiques
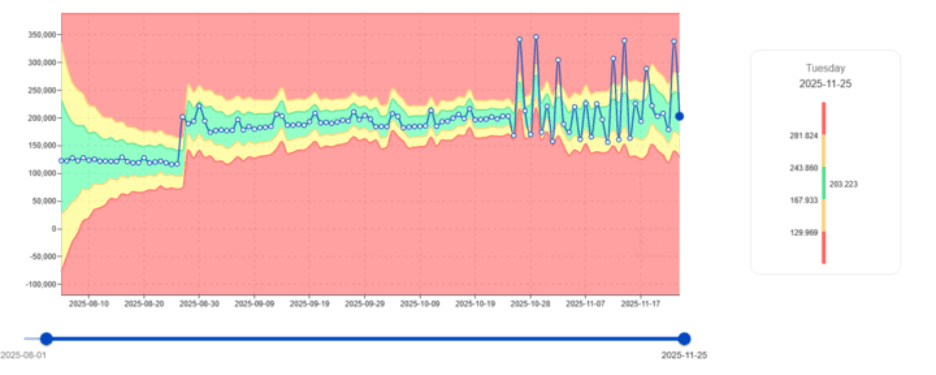
Parfois, la consommation de CPU est stable pendant des mois—et devient soudainement erratique.
C'est exactement le type de charge de travail que digna est construit pour détecter.
Ces changements résultent souvent de :
Migration de données
Nouvelles démographies ou distributions
Modifications de la logique ETL
Dérive du schéma
Mauvaise maintenance des index
digna signale immédiatement ces schémas, marquant ces charges de travail comme hautement prioritaires pour l'analyse.
Impact sur l'entreprise : La détection précoce empêche les pics de CPU qui peuvent dégrader les performances pour des centaines d'utilisateurs et de charges de travail.
Reconnaître et respecter les schémas saisonniers
Pas tous les pics ne sont des anomalies.
Certaines charges de travail changent naturellement :
Clôture de fin de mois
Cycles de facturation hebdomadaires
Rapports du lundi
Charges de données du début de trimestre
Agrégations de fin de journée
L'image ici montre comment digna apprend ces motifs saisonniers automatiquement.
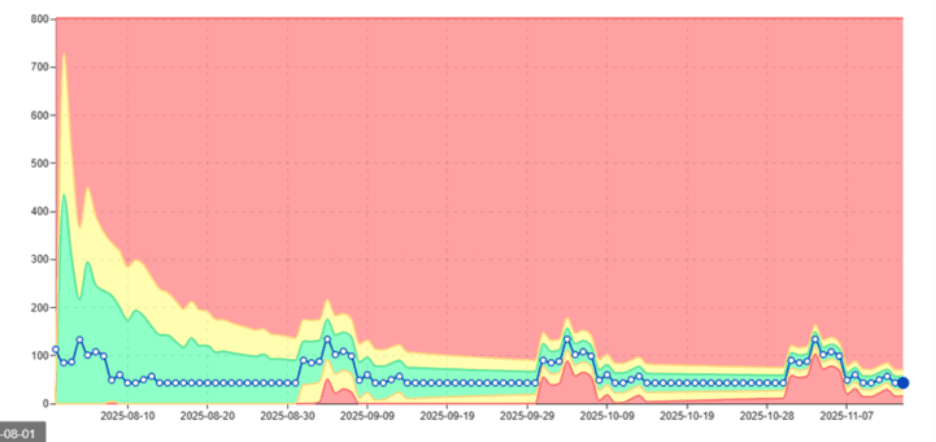
Plutôt que d'alerter incorrectement, digna comprend :
Quand certaines charges de travail doivent culminer
À quelle hauteur la pointe doit être
Quels motifs se répètent dans le temps
Valeur clé : digna élimine les faux positifs en distinguant les anomalies de la saisonnalité naturelle.
Surveiller la croissance de la base de données avec les tendances d'utilisation de perm
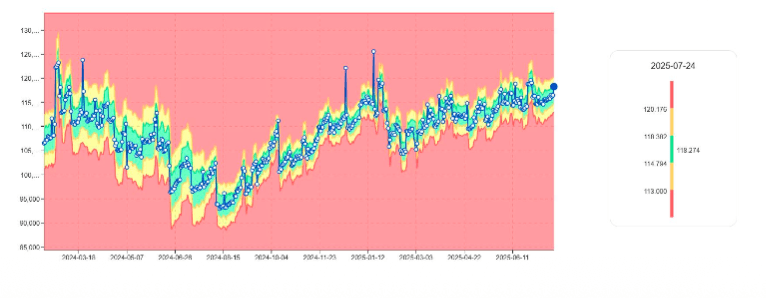
L'utilisation de perm est une métrique fondamentale pour la gestion de la capacité Teradata. digna :
Apprend la trajectoire normale de la taille
Signale les augmentations soudaines
Identifie la croissance anormale des tables
Détecte les pics de consommation de stockage
Ceci aide à prévenir :
Erreurs d'espace
Scans complets de tables inattendus
Charges de travail ELT incontrôlées
Valeur clé : digna donne aux équipes le temps de réagir avant que la consommation de stockage n'affecte les performances.
Détection des skew : Identifier la distribution inégale des données

Le skew est l'un des problèmes de performance les plus courants — et coûteux — dans Teradata.
Le skew survient lorsque les données ne sont pas réparties uniformément entre les AMPs, causant :
Goulets d'étranglement
Longs cycles CPU
Jonctions lentes
Inconsistances de performance
digna analyse automatiquement les tendances de skewness au fil du temps pour montrer :
Quand une table devient déséquilibrée
Si le skew s'aggrave
Quels AMPs sont affectés
Si des changements récents des données ont causé un nouveau déséquilibre
Valeur clé : digna localise la dégradation liée au skew avant qu'elle n'impacte les performances sur toute la plateforme.
digna convertit toutes les métriques DBC en données de séries chronologiques
C'est le moteur central de tout ce qui est décrit ci-dessus. En convertissant les métriques des tables DBC en séries chronologiques, digna peut :
Capacités IA
Apprendre les schémas CPU
Détecter les anomalies IO
Modéliser les fluctuations saisonnières
Suivre la volatilité au niveau des travaux
Détecter la dérive lente des données
Surveiller la capacité du système à long terme
Capacités d'observabilité
Comparer les charges de travail au fil des jours
Suivre les changements de performance des requêtes
Fournir des tendances historiques
Identifier les régressions
Surveiller les schémas de croissance
Système d'alertes et intégrations
Email
Slack
Jira
Webhooks
Notifications au niveau des modules
Valeur clé : le moteur de séries chronologiques de digna transforme les métadonnées brutes de Teradata en informations exploitables.
Impact réel : Plus de stabilité, des coûts réduits, moins d'escalades
Basé sur la manière dont les équipes utilisent digna aujourd'hui, la plateforme offre :
Moins de réunions d'escalade: Parce que les anomalies sont détectées avant que les problèmes ne s'aggravent.
Plus de prévisibilité: Charges de travail stables = utilisation des ressources prévisible = contrôle des coûts facilité.
Réduction de la consommation CPU et IO: Grâce à l'identification précoce des charges de travail inefficaces.
Collaboration renforcée avec les équipes métiers : Les problèmes sont résolus avant que les utilisateurs du métier ne remarquent quoi que ce soit.
Moins de lutte contre les incendies pour les équipes d'ingénierie : L'IA gère la surveillance afin que l'équipe puisse se concentrer sur des tâches à forte valeur ajoutée.
Conclusion
Teradata Vantage fournit la base pour les données et l'analyse d'entreprise. digna élève cette base en ajoutant une couche de surveillance automatisée par IA qui transforme les métriques système brutes en intelligence opérationnelle en temps réel.
En analysant en continu le CPU, l'IO, le skew, l'utilisation de perm et le comportement des travaux, digna permet aux équipes d'ingénieurs de :
Améliorer les performances
Prévenir les temps d'arrêt
Réduire les coûts cloud/sur site
Travailler de manière proactive plutôt que réactive
C'est la nouvelle génération de l'analyse de charges de travail Teradata — pilotée par l'IA, automatisée, et construite pour l'échelle d'entreprise.
Regardez notre démo et explorez l'optimisation pilotée par IA pour l'efficacité CPU, IO et coût sur votre environnement Teradata ou contactez-nous.



