Por qué las cargas de trabajo de Teradata se vuelven inestables y cómo los equipos lo detectan a tiempo
|
6
minuto de lectura

Los sistemas Teradata están diseñados para ofrecer estabilidad. Durante décadas, las empresas han confiado en Teradata para proporcionar analítica predecible y de alto rendimiento a escala. En sectores regulados como la banca, los seguros, las telecomunicaciones y el sector público, Teradata sigue siendo un componente crítico para la toma de decisiones.
Sin embargo, incluso en estos entornos maduros, los equipos de datos se encuentran con un problema familiar: las cargas de trabajo que antes eran estables se vuelven gradualmente impredecibles.
El consumo de CPU fluctúa. El uso de E/S aumenta. Los trabajos de larga duración consumen más recursos mes tras mes. Los costes aumentan, no porque algo esté roto, sino porque algo ha cambiado silenciosamente.
Comprender por qué las cargas de trabajo de Teradata se vuelven inestables, y cómo detectar esa inestabilidad a tiempo, es esencial para mantener el rendimiento, la eficiencia de costes y la confianza operativa.
La inestabilidad en Teradata rara vez aparece de la noche a la mañana
A diferencia de las plataformas cloud modernas, los entornos Teradata tienden a evolucionar lentamente. Los cambios son deliberados, controlados y están bien documentados. Como resultado, la inestabilidad rara vez se manifiesta como un fallo repentino.
En cambio, aparece como deriva del comportamiento:
Los trabajos siguen completándose correctamente
Los SLA se cumplen técnicamente
Los paneles no muestran señales de alarma obvias
Sin embargo, bajo la superficie, el comportamiento de la carga de trabajo cambia. El uso de CPU aumenta ligeramente. Los patrones de E/S se vuelven más erráticos. Las ventanas de procesamiento se reducen. Con el tiempo, estas pequeñas desviaciones se acumulan hasta convertirse en un riesgo operativo.
Cuando la inestabilidad se vuelve visible, la remediación suele ser costosa y disruptiva.
Causas comunes de la inestabilidad de las cargas de trabajo en Teradata
1. El crecimiento de los datos que altera los planes de ejecución
El crecimiento de los datos es inevitable, pero su impacto rara vez es lineal.
A medida que crecen las tablas:
Cambian las estrategias de join
Aumenta el uso de spool
Aumentan los costes de redistribución
Cambia el equilibrio de la carga de trabajo de AMP2
Las consultas que antes eran eficientes comienzan a consumir más CPU y E/S, aunque el SQL en sí no haya cambiado. Como el crecimiento es gradual, las alertas tradicionales basadas en umbrales rara vez se activan a tiempo.
2. La lógica SQL que evoluciona lentamente
Las cargas de trabajo de Teradata no son estáticas.
Con el tiempo:
Se introducen joins adicionales
Se seleccionan nuevos atributos
Se relajan los filtros
Se amplían los requisitos de informes
Cada ajuste parece menor, pero en conjunto altera las características de la carga de trabajo. Los trabajos se ejecutan durante más tiempo, consumen más recursos y se vuelven menos predecibles.
Sin análisis histórico, estos cambios suelen descubrirse solo después de que los usuarios se quejan o aumentan los costes.
3. Cambios de sesgo y distribución
La distribución sesgada de los datos es un desafío bien conocido en muchos sistemas MPP como Teradata.
El sesgo puede surgir debido a:
Migraciones de datos
Cambios demográficos
Crecimiento empresarial concentrado en segmentos específicos
Cambios en las suposiciones de modelado de datos
A medida que aumenta el sesgo, la distribución de la carga de trabajo entre los AMP se vuelve desigual. Determinados AMP consumen una cantidad desproporcionada de CPU y E/S, degradando el rendimiento general del sistema.
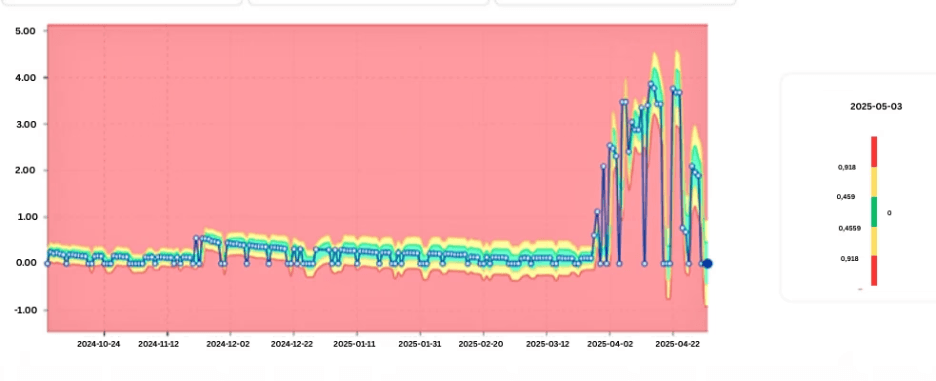
Visualización de datos que muestra cómo aumenta con el tiempo el sesgo de CPU a nivel de AMP.
4. Ajustes de infraestructura y configuración
Incluso los sistemas Teradata bien gestionados evolucionan.
Cambios como:
Actualizaciones de hardware
Reconfiguración de la plataforma
Ajuste del sistema
Priorización de cargas de trabajo mixtas
pueden influir sutilmente en el comportamiento de la carga de trabajo. Un trabajo que se ejecutó de forma constante durante años puede mostrar de repente una mayor variabilidad — no debido a problemas de datos, sino porque cambió el entorno de ejecución.
5. Procesamiento cíclico y estacional
Muchas cargas de trabajo de Teradata siguen ciclos predecibles:
Cierre de fin de mes
Informes regulatorios
Conciliaciones periódicas
Sin modelar explícitamente la estacionalidad, el comportamiento cíclico normal puede ocultar anomalías reales o generar alertas innecesarias.
Distinguir la variación esperada de la verdadera inestabilidad requiere contexto histórico.
Por qué la supervisión tradicional de Teradata pasa por alto las señales tempranas
Los entornos Teradata suelen supervisarse con:
Alertas de CPU y E/S basadas en umbrales
Límites de tiempo de ejecución de las consultas
Paneles de utilización del sistema
Estas herramientas son eficaces para identificar fallos agudos, pero tienen dificultades con el cambio gradual.
Responden a preguntas como:
¿La CPU superó un límite?
¿Falló un trabajo?
No responden a:
¿Este trabajo se está volviendo más costoso con el tiempo?
¿Su comportamiento se está volviendo menos estable?
¿Es plausible la carga de trabajo de hoy en comparación con los patrones históricos?
La inestabilidad vive en estas preguntas sin respuesta.
El papel del análisis de series temporales en las operaciones de Teradata
La detección temprana requiere tratar las métricas de la carga de trabajo como señales de series temporales, no como valores estáticos.
Las métricas clave de Teradata incluyen:
Tiempo de CPU
Recuento de E/S
Uso de spool
Tiempo de ejecución de la consulta
Crecimiento de tablas
Cuando se analizan a lo largo del tiempo, estas métricas revelan:
Tendencias a largo plazo
Mayor volatilidad
Cambios estructurales tras implementaciones o migraciones
Desviaciones respecto a los patrones estacionales
Esta perspectiva transforma la supervisión de la carga de trabajo de la resolución reactiva de problemas al control proactivo.
Detectar la inestabilidad antes de que se convierta en un problema
Aprender el comportamiento normal de la carga de trabajo
En lugar de definir umbrales estáticos, los enfoques modernos observan el comportamiento histórico de la carga de trabajo y aprenden cómo se ve lo “normal” para cada trabajo, clase de consulta o componente del sistema.
A medida que los patrones se estabilizan, los rangos aceptables se vuelven más claros. Las desviaciones de estos patrones aprendidos señalan posibles problemas, incluso si los valores absolutos siguen dentro de los límites nominales.
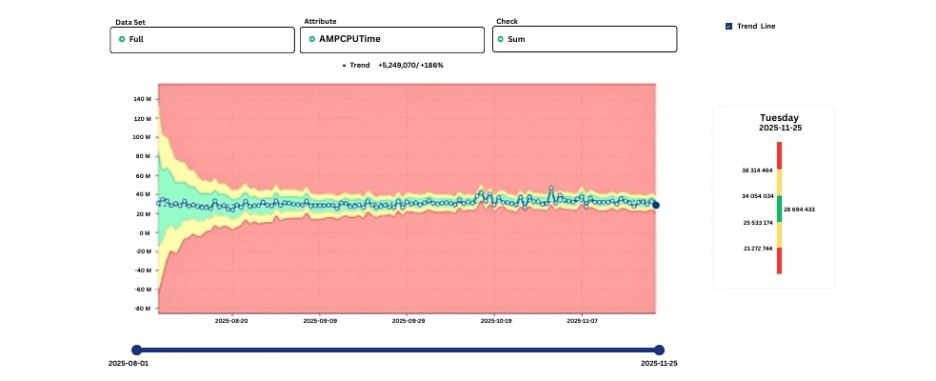
Gráfico que muestra bandas aprendidas de comportamiento normal con una desviación emergente.
Identificar la deriva gradual
La deriva gradual es una de las formas de inestabilidad más costosas.
Clasificando los trabajos según:
Aumento absoluto de CPU
Cambio relativo a lo largo del tiempo
los equipos pueden identificar rápidamente qué cargas de trabajo contribuyen más al aumento de la carga del sistema.
Esto permite una optimización dirigida en lugar de ejercicios de ajuste generalizados.
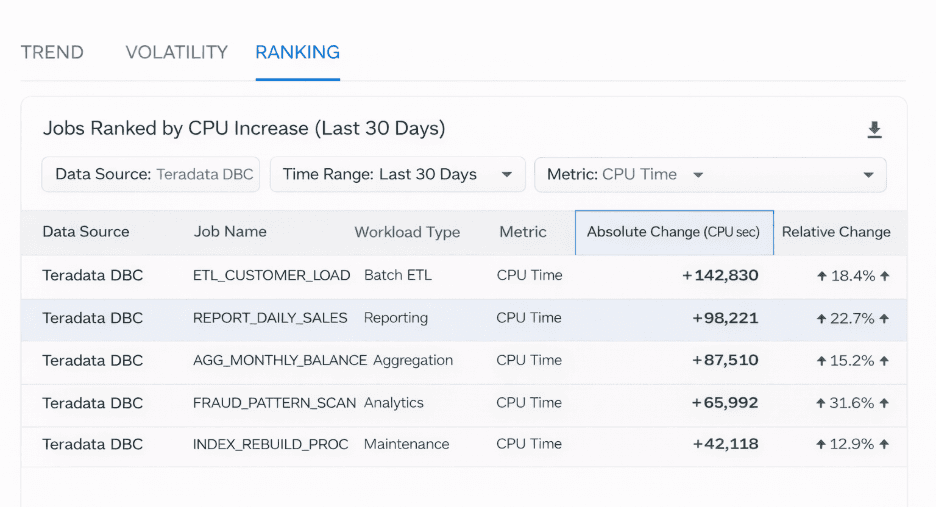
Lista de trabajos clasificados por aumento de CPU mes a mes.
Medir la volatilidad
La estabilidad no solo tiene que ver con los promedios.
Los trabajos con un consumo de CPU o E/S muy variable son más difíciles de planificar y tienen más probabilidades de causar problemas posteriores. Medir la volatilidad pone de relieve las cargas de trabajo que se comportan de forma impredecible, incluso cuando su uso medio parece aceptable.
Tener en cuenta la estacionalidad
La detección eficaz tiene en cuenta los ciclos conocidos.
Al aprender patrones semanales y mensuales, los sistemas evitan falsos positivos y, al mismo tiempo, siguen siendo sensibles a las desviaciones que rompen el comportamiento establecido.
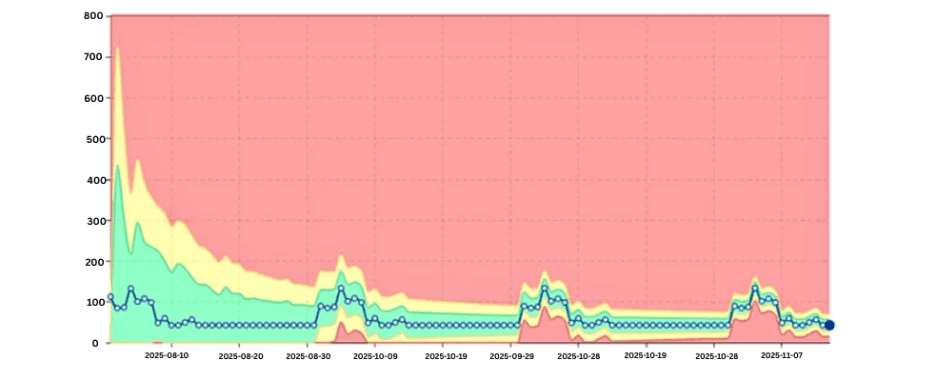
Tendencia de CPU con conocimiento de la estacionalidad que muestra los picos esperados de fin de mes.
Dónde encaja digna en el análisis de cargas de trabajo de Teradata
Algunos enfoques de supervisión se basan en exportar métricas a sistemas externos para su análisis. Otros operan directamente dentro del entorno de la base de datos.
digna lee las tablas del sistema de Teradata (DBC) y permite a los clientes definir cómo accede a estas fuentes de metadatos; después, las métricas de la carga de trabajo se convierten en datos de series temporales. Mediante modelos basados en IA, aprende el comportamiento normal y detecta desviaciones estadísticamente improbables, ya sean picos repentinos o una deriva lenta.
Como digna se centra en el comportamiento y no en umbrales estáticos, ayuda a los equipos a detectar la inestabilidad a tiempo, antes de que escale hasta convertirse en problemas de rendimiento o de costes.
Una visión general de este enfoque basado en anomalías está disponible aquí o también puede reservar una demostración con ellos.
Beneficios operativos de la detección temprana
Las organizaciones que detectan a tiempo la inestabilidad de las cargas de trabajo de Teradata obtienen beneficios medibles:
Menor consumo de CPU y E/S gracias a una optimización oportuna
Mayor previsibilidad de costes
Menos reuniones de escalado
Mejor colaboración entre los equipos de plataforma y de negocio
Mayor confianza en los resultados analíticos
Y lo más importante, la estabilidad pasa a ser gestionable en lugar de reactiva.
De cara al futuro: la estabilidad como disciplina operativa
A medida que Teradata sigue dando soporte a cargas de trabajo de analítica e IA de misión crítica, la estabilidad se convierte en una preocupación estratégica.
La deriva silenciosa de la carga de trabajo socava la confianza, aumenta los costes y eleva el riesgo operativo. Detectar la inestabilidad a tiempo requiere:
Análisis de series temporales
Aprendizaje del comportamiento
Alertas con conocimiento del contexto
Un esfuerzo operativo mínimo
En este sentido, la estabilidad de la carga de trabajo ya no es solo una métrica de rendimiento, sino un elemento central de la fiabilidad de los datos empresariales.
Reflexión final
Las cargas de trabajo de Teradata no se vuelven inestables de la noche a la mañana. La inestabilidad aparece gradualmente, impulsada por el crecimiento de los datos, los cambios en la lógica y las condiciones cambiantes del sistema.
Los equipos que dependen únicamente de la supervisión estática detectan los problemas demasiado tarde. Quienes analizan el comportamiento de la carga de trabajo a lo largo del tiempo pueden intervenir antes, preservando tanto el rendimiento como la previsibilidad.
A medida que los entornos Teradata siguen evolucionando, la detección temprana de la inestabilidad de la carga de trabajo definirá la madurez operativa.



