Pipelines de data science robustes : construire, déployer, surveiller
|
6
minute de lecture

Vous êtes probablement confronté à l'une de ces deux situations en ce moment. Soit un modèle en production a commencé à se comporter de manière étrange et personne ne peut dire si le problème provient de la logique des features, des données sources ou d'un chargement tardif en amont. Soit votre équipe dispose d'un pipeline qui « fonctionne » la plupart du temps, mais chaque déploiement semble risqué car un seul changement de schéma, une seule partition manquante ou un seul fichier corrompu peut empoisonner les résultats en aval.
C'est le profil type des pipelines de data science en production. Le plus difficile n'est généralement pas d'entraîner un modèle. C'est de maintenir un flux de données digne de confiance tout au long de l'ingestion, de la transformation, de la création de features, du déploiement et de la surveillance continue. Les équipes qui se concentrent uniquement sur l'orchestration l'apprennent à leurs dépens. Un DAG vert ne garantit pas la validité des données, et une exécution réussie de tâche ne garantit pas des entrées de modèle utiles.
Table des matières
Pourquoi les pipelines de data science sont l'épine dorsale de l'IA moderne
Intégration des pipelines avec les Data Warehouses et les Data Lakes
Au-delà de l'orchestration : qualité des données et Observability
Considérations sur les pipelines sur site (On-Prem) et en Cloud privé
Pourquoi les pipelines de data science sont l'épine dorsale de l'IA moderne
Beaucoup d'échecs de projets d'IA ne commencent pas par une mauvaise modélisation. Ils commencent par un pipeline qui a fourni des features incomplètes, des enregistrements doublonnés, des agrégats obsolètes ou des données d'entraînement mal étiquetées. Le modèle est blâmé car il est visible. Le pipeline échappe à l'examen car il est enfoui sous des ordonnanceurs, des scripts, des connecteurs et des tâches de data warehouse.
C'est pourquoi je traite les pipelines de data science comme des infrastructures, et non comme du simple liant de projet. Ils alimentent les expérimentations, les tâches d'entraînement, le scoring par lots, les features d'inférence en ligne, les tableaux de bord et les boucles de réentraînement. Lorsqu'ils dérivent, chaque consommateur en aval en subit les dommages.

Le signal économique est clair. Le marché mondial des pipelines de données est évalué à 10,01 milliards USD en 2024 et devrait atteindre 43,61 milliards USD d'ici 2032, avec un taux de croissance annuel composé (CAGR) de 19,9 %, et 90 % des projets d'IA et de machine learning dépendent directement de ces pipelines selon Fortune Business Insights sur le marché des pipelines de données. Les équipes n'investissent pas dans l'infrastructure de pipeline par effet de mode. Elles le font parce que les systèmes d'IA ne survivent pas à des fondations de données fragiles.
Ce qui casse dans les environnements réels
Les pannes évidentes sont faciles à repérer. Une tâche plante. Un fichier n'arrive jamais. Un connecteur expire.
Les pannes dangereuses sont plus discrètes :
La dérive de fraîcheur où les données quotidiennes commencent à arriver de plus en plus tard
La dérive sémantique où un champ existe toujours mais sa signification a changé en amont
La dérive de distribution où les valeurs respectent les types de données mais s'écartent du comportement normal
La réussite partielle où un pipeline écrit son résultat, mais seulement pour une partie du périmètre attendu
Règle pratique : Si votre seul indicateur de santé est la réussite de la tâche, vous ne surveillez pas le pipeline. Vous surveillez l'ordonnanceur.
Tout pipeline de data science fiable doit répondre à deux questions chaque jour. Les tâches ont-elles tourné ? Et ont-elles produit des données toujours adaptées à l'entraînement, au scoring et à la prise de décision ?
Décoder le concept de pipeline de data science
Le modèle mental le plus simple est une ligne de production d'usine. Les matières premières proviennent de différents fournisseurs. Chaque station nettoie, remet en forme, vérifie, enrichit ou assemble quelque chose. À la fin, vous ne voulez pas un tas de pièces détachées. Vous voulez un produit fini digne de confiance.
Un pipeline de data science fonctionne de la même manière. Il extrait des données brutes des applications, des journaux, des fichiers, des API, des flux d'événements et des tables de warehouse. Ensuite, il transforme ces données en ensembles d'entraînement, en features, en prédictions et en résultats surveillés que d'autres systèmes peuvent exploiter.
Plus que de l'ETL
Une tâche ETL de base déplace et transforme des données. C'est important, mais ce n'est qu'une partie de l'histoire. Les pipelines de data science ajoutent généralement des étapes que les pipelines analytiques standards ne couvrent pas entièrement :
La création de features pour des entrées prêtes pour le modèle
La génération de jeux de données d'entraînement et de validation
La reproductibilité des expériences
Le packaging et le déploiement de modèles
Les boucles de rétroaction après déploiement
Cette différence est cruciale d'un point de vue opérationnel. Un rapport BI cassé est embêtant. Un pipeline d'entrée de modèle cassé peut affecter les algorithmes de recommandation, la détection des fraudes, les prévisions, le tri des demandes ou les flux d'examens médicaux selon le secteur d'activité.
Script vs pipeline de production
Les projets de data science commencent souvent par un notebook ou un script Python. C'est normal. C'est aussi là que commencent de nombreux problèmes de fiabilité.
Un script ponctuel peut convenir pour l'exploration. Mais il s'avère être un mauvais système de production car il dépend souvent d'hypothèses locales :
Scénario | Ce qui se passe |
|---|---|
Flux de travail via Notebook | Les chemins, les identifiants, les versions de packages et les choix d'échantillonnage vivent dans l'environnement d'une seule personne |
Pipeline de production | Les entrées, les sorties, les dépendances, les tentatives, les tests, le lignage et la propriété sont explicites |
Les pipelines de data science de niveau production nécessitent de la répétabilité. Si la même entrée arrive demain, le système doit exécuter la même logique avec des modifications contrôlées, des dépendances connues et des sorties observables. Cela implique généralement que des outils comme Airflow, Dagster, Prefect, Spark, dbt, le SQL natif du warehouse, les pipelines CI et l'infrastructure de serving de modèles collaborent au lieu d'utiliser une seule pile monolithique.
Un pipeline n'est pas mature parce qu'il est automatisé. Il est mature lorsqu'un autre ingénieur peut le modifier en toute sécurité et savoir si le résultat est toujours fiable.
C'est le standard qu'il convient de viser.
Les sept étapes clés d'un pipeline de data science
La plupart des systèmes de production semblent complexes dans leurs détails, mais le cycle de vie reste le même. Si les équipes partagent un vocabulaire commun pour ces étapes, le débogage devient plus simple et la répartition des responsabilités plus claire.
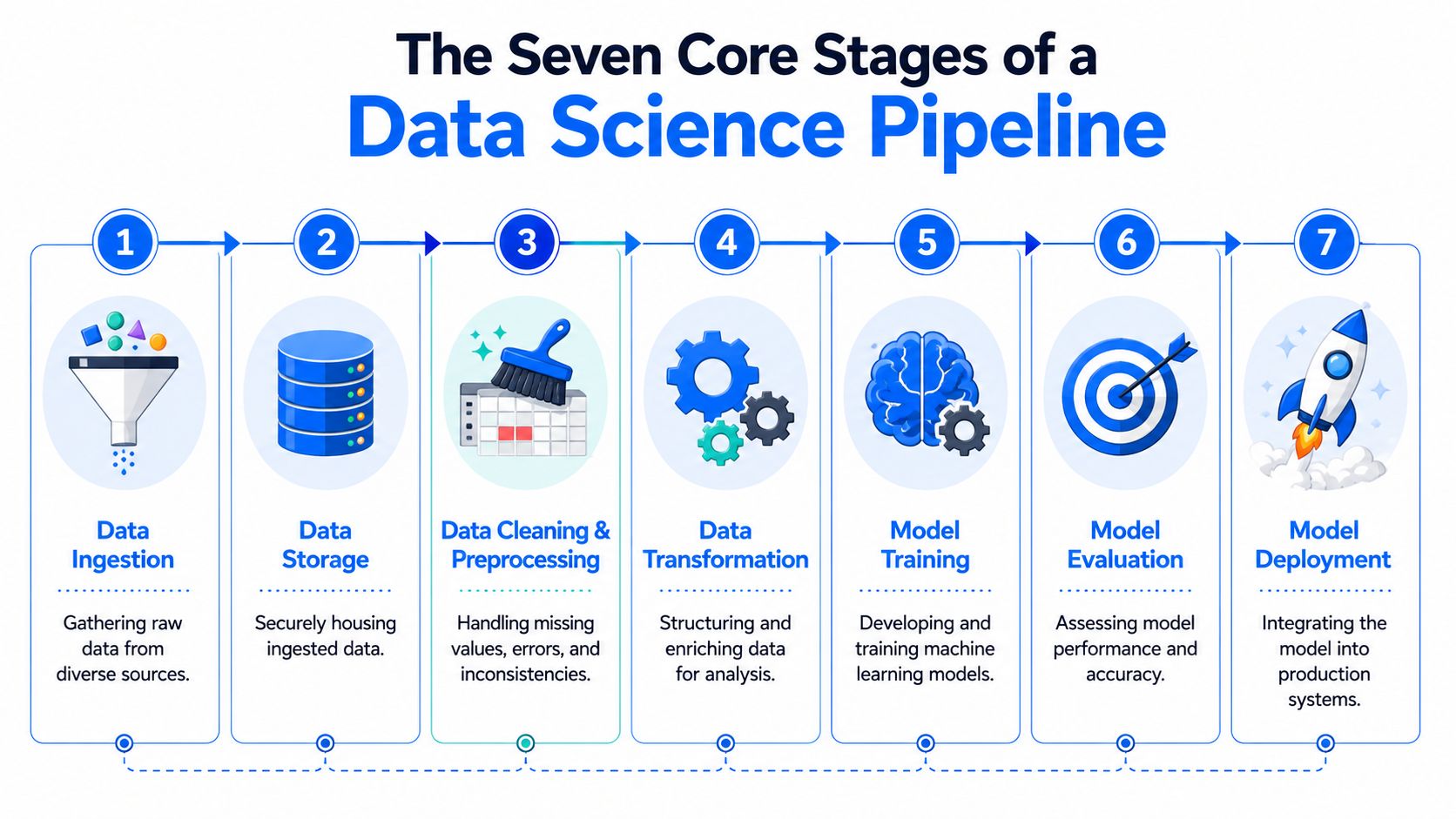
Ingestion de données
Le pipeline se confronte à la réalité lors de l'arrivée des données. Ces données proviennent de bases de données OLTP, d'outils SaaS, de flux CDC, de stockage d'objets, de logs d'applications et d'API. Certaines sources sont structurées et stables. D'autres non.
La décision principale ici concerne le choix entre le traitement par lots (batch), le streaming ou les deux. Le traitement par lots est plus simple à concevoir et plus facile à recalculer de manière rétroactive. Le streaming répond aux cas d'usage à faible latence, mais il place la barre plus haut pour la gestion de l'ordre, du dédoublonnement, des événements tardifs et des points de contrôle (checkpoints).
Les outils courants incluent Kafka, Pub/Sub, Kinesis, Airbyte, Fivetran, les connecteurs personnalisés et l'ingestion directe dans le warehouse.
Stockage et intégration des données
Une fois les données arrivées, elles ont besoin d'un espace de stockage durable et d'un format sur lequel les consommateurs en aval peuvent compter. Les équipes choisissent entre l'ETL et l'ELT, définissent des couches brutes par rapport aux couches nettoyées, et décident de la part de transformation à attribuer aux jobs Spark par rapport aux modèles SQL.
Cette étape produit généralement :
Des zones de stockage brutes (landing zones) pour le rejeu et l'audit
Des jeux de données standardisés pour un usage partagé
Des entrées de features intégrées à travers différents domaines comme les clients, les produits, les sinistres ou les données d'équipements
Une bonne couche d'intégration préserve suffisamment de détails bruts pour un traitement ultérieur tout en offrant aux utilisateurs finaux des interfaces stables.
Avant d'aller plus loin dans les étapes suivantes, il convient de poser une règle de contrôle pratique. Des pratiques rigoureuses de validation de données pour les pipelines de production empêchent les anomalies évidentes de se propager en aval sans contrôle.
Traitement des données et feature engineering
De nombreux pipelines se spécialisent métier par métier à mesure que les équipes traitent les valeurs manquantes, encodent les variables catégorielles, construisent des features temporelles glissantes, agrègent les événements sur des plages de temps, calculent des ratios et croisent les données comportementales avec des données de référence.
La logique des features commence souvent dans des notebooks pour être ensuite figée sous forme de transformations SQL, Spark ou Python. L'erreur classique est prévisible : la logique est copiée séparément sur les chemins d'entraînement et d'inférence, puis dérive. La solution l'est tout autant : centralisez les définitions de features et versionnez-les.
Quelques bonnes pratiques s'imposent :
Séparer le nettoyage brut de la logique métier
Garder les définitions de features proches des tests
Concevoir des transformations idempotentes
Enregistrer la version des données utilisée pour chaque session d'entraînement
Voici le aperçu intégré du cycle de vie global :
Entraînement et réglage des modèles
L'entraînement consomme les jeux de données traités et les transforme en modèles candidats. Les aspects techniques varient selon la pile technologique. Certaines équipes utilisent scikit-learn sur des extractions de warehouse. D'autres utilisent Spark ML, XGBoost, PyTorch, TensorFlow ou des plateformes ML managées.
La préoccupation opérationnelle ne se limite pas au réglage des hyperparamètres. C'est une question de reproductibilité. Si un modèle sous-performe le mois prochain, vous devez savoir quelle version de code, quel ensemble de features, quelle tranche d'entraînement et quels paramètres l'ont généré.
Validation et sélection des modèles
Cette étape détermine ce qui a le droit de passer à l'étape suivante. Les équipes comparent les modèles candidats à l'aide de données de test (holdout), de contraintes métier, d'exigences d'explicabilité et de limites opérationnelles telles que la latence d'inférence ou l'empreinte mémoire.
La validation doit aller plus loin que les simples métriques de modèles. Elle doit également questionner si les données sous-jacentes sont toujours représentatives du phénomène ciblé. Un modèle très performant sur le papier mais entraîné sur des entrées instables peut tout de même échouer en production.
Le meilleur modèle candidat est celui que votre plateforme peut supporter de manière stable, et pas seulement celui qui obtient la meilleure note hors ligne.
Déploiement des modèles
Le déploiement transforme un artefact en service ou en processus de scoring planifié. Les schémas de déploiement classiques incluent le calcul de scores par lots dans une table de warehouse, l'inférence en temps réel derrière une API, et des configurations hybrides où un service temps réel fait appel à des features pré-calculées.
Cette étape nécessite des contrats explicites :
Aspect du déploiement | Ce qu'il faut définir |
|---|---|
Entrées | Champs obligatoires, types, gestion des valeurs nulles et impératifs de fraîcheur |
Sorties | Schéma de prédiction, champs de confiance et emplacement d'écriture |
Retour en arrière (Rollback) | Version antérieure du modèle, conditions de déclenchement et méthode de restauration |
Surveillance et réentraînement
Le pipeline ne s'arrête pas au déploiement. La surveillance en production doit englober la santé du serveur, la fraîcheur des features, la stabilité du schéma, la qualité de la donnée et les critères de déclenchement d'un réentraînement.
Le réentraînement doit répondre à un besoin identifié, et non pas simplement parce qu'un planificateur cron le demande. Dans les systèmes matures, les décisions de réentraînement sont liées à une dérive constatée, un virement du contexte métier ou une baisse d'efficacité du modèle. Autrement, les équipes ne font qu'automatiser de l'agitation inutile.
Intégration des pipelines avec les Data Warehouses et les Data Lakes
Les pipelines de data science ne sont pas généralement construits de manière isolée. Ils reposent sur des tables de warehouse, du stockage en data lake, ou une combinaison des deux. Le choix de l'architecture influe sur la latence, la governance, la vitesse d'expérimentation et le niveau de logique redondante à maintenir.

Modèles axés sur le Warehouse
Les data warehouses conviennent le mieux lorsque vos données d'entrée sont déjà bien structurées et que l'entreprise requiert des jeux de données gouvernés et requêtables. Snowflake, BigQuery, Redshift et d'autres systèmes similaires s'imposent naturellement lorsque l'analytics engineering et la génération de features ML doivent partager des tables validées.
Dans ce modèle, le warehouse sert habituellement de source de vérité pour :
Les entités standardisées telles que le client, le compte, le fournisseur ou le commerçant
Les features validées partagées fréquemment entre les équipes
Les résultats de modèles réinjectés pour la BI et les rapports opérationnels
Une architecture axée d'abord sur le warehouse simplifie la governance. Les contrats de schéma, les transformations SQL, la gestion des accès et l'auditabilité y sont généralement plus limpides que dans des architectures basées sur des fichiers en réseau. Ce choix s'aligne également pour les équipes envisageant une stratégie de migration de warehouse vers data lake pour les charges de travail mixtes.
Modèles axés sur le Lake
Les data lakes sont préférables lorsque les équipes recherchent une grande flexibilité sur des fichiers bruts, des données semi-structurées, des logs, des documents ou de volumineux volumes de données expérimentales. Ils permettent aux data scientists d'analyser les détails de la source brute sans imposer préaturément un schéma de warehouse rigide.
Cette approche répond bien aux cas d'usage suivants :
La génération de features volumineuses basées sur des événements
La conception de modèles sur des flux de télémétrie bruts
Les pipelines de textes, d'images ou de documents
Le retraitement des données historiques après modification de la logique de calcul des features
La contrepartie est l'exigence de rigueur opérationnelle. Les data lakes offrent de la liberté, mais facilitent aussi l'accumulation de formats hétérogènes, le doublonnage des ressources et une définition floue des responsabilités.
Ce qui fonctionne dans les environnements mixtes
La plupart des grandes entreprises finissent par adopter un modèle hybride. Les données brutes et volumineuses atterrissent dans un data lake. Les données consolidées, gouvernées et destinées aux utilisateurs métiers résident quant à elles dans le warehouse. Le pipeline fait le lien entre les deux.
Une répartition logique se présente souvent ainsi :
Couche | Meilleure utilisation |
|---|---|
Lake | Ingestion brute, rejeu, expérimentation et traitements intermédiaires à grande échelle |
Warehouse | Dimensions certifiées, faits consolidés, features réutilisables et rapports en aval |
Logique du pipeline | Transfert, transformation, validation et mise à disposition entre les deux environnements |
Gardez la flexibilité expérimentale en amont. Assurez la confiance pour la consommation métier en aval.
Cette étanchéité évite un piège classique : celui de pousser trop tôt l'intégralité des flux vers le warehouse — ce qui ralentit l'expérimentation — ou de laisser trop de processus côté data lake, ce qui complique inutilement les analyses croisées et les exigences de Compliance qui en découlent.
Au-delà de l'orchestration : qualité des données et Observability
Un planificateur de tâches peut vous confirmer que les jobs se sont exécutés. Il ne peut pas vous dire si les valeurs enregistrées ont du sens, si un attribut critique a vu son contenu s'aplatir vers une valeur proche d'une constante, ou si les générateurs de données en amont ont modifié la logique métier tout en préservant la structure du schéma.
C'est pourquoi se limiter à la seule orchestration ne suffit plus.

À quoi ressemblent les pannes silencieuses
La charge opérationnelle s'avère plus importante que la plupart des équipes ne veulent l'admettre. Les pipelines de données subissent une instabilité chronique, avec 30 % à 40 % de pannes hebdomadaires. Ces dysfonctionnements entraînent en moyenne 67 incidents de données par mois et par organisation, chaque incident requérant environ 15 heures de résolution, d'après le récapitulatif des statistiques de data engineering de Folio3.
Ces chiffres ne font référence qu'aux incidents apparents. En pratique, certains des coûts les plus élevés découlent de pannes qui ne provoquent aucun plantage système, à savoir les dérives de qualité invisibles :
Une source commence à transmettre des chaînes vides à la place de valeurs nulles
Un champ d'énumération gagne une nouvelle catégorie ignorée par la logique en aval
Une horodate (timestamp) arrive dans un format de fuseau horaire différent
La distribution d'un paramètre varie assez lentement pour échapper aux règles de seuil fixes
Dans les environnements d'apprentissage automatique, le modèle continue de générer des prédictions alors que la fiabilité réelle de ses prévisions se dégrade continuellement.
Les quatre signaux essentiels
Les équipes ont besoin d'une interface unique qui unifie la qualité et l'Observability, plutôt que de devoir naviguer entre différents écrans et outils sans lien. Voici les quatre signaux indispensables.
Qualité des données
Il s'agit de la conformité des données au niveau de l'enregistrement. Les champs obligatoires sont-ils bien remplis ? Les valeurs respectent-elles les règles métier ? Les clés étrangères pointent-elles correctement ? Les calculs internes sont-ils cohérents d'une colonne à l'autre ?
Les validations explicites s'avèrent cruciales. Les contrôles de qualité doivent être placés au plus près des données qu'ils valident, et non masqués uniquement au sein du code de l'application ou des notebooks en aval.
Fraîcheur (Timeliness)
Des données valides arrivant en retard posent tout de même un problème en production. La surveillance de la ponctualité doit assurer le suivi des profils de livraison habituels, des partitions en attente, des chargements incomplets et des mises à jour tardives des sources.
Dans les environnements par lots, cela implique d'effectuer des vérifications adaptées aux fenêtres de traitement. Pour les flux d'événements, il s'agit de surveiller la latence d'ingestion et les messages désordonnés.
Intégrité du schéma
Un changement brutal de schéma est flagrant lorsqu'une colonne disparaît et bloque l'exécution d'une tâche. Le cas le plus sournois est le changement incrémental ou de type apparenté, qui n'interrompt pas immédiatement le flux mais en altère la signification. Les équipes doivent auditer l'ajout ou la suppression de colonnes, les conversions de formats et les écarts de contrats d'interfaces.
Détection d'anomalies
Les règles fixes ciblent les problèmes connus. La détection d'anomalies identifie les variations imprévues de volume, de distribution, de comportements ou d'évolutions de tendance. Vous devez vous appuyer sur ces deux approches.
Une comparaison utile se résume ainsi :
Type de signal | Efficace pour identifier | Moins efficace pour identifier |
|---|---|---|
Règles statiques | Pics de valeurs nulles, plages interdites, erreurs de format | Nouveaux types de dérives non anticipés |
Détection d'anomalies | Changements inattendus de tendances et de distributions | Erreurs de logique métier pure non définies explicitement |
Pour les équipes évaluant ces deux pratiques, ce guide sur le face-à-face pratique entre l'observabilité et la qualité des données propose une analyse pertinente qui les positionne comme des leviers complémentaires et non concurrents.
Pourquoi une surveillance unifiée l'emporte sur la multiplication des outils
Une architecture fragmentée génère ses propres incidents. Un composant surveille la ponctualité, un second vérifie le schéma, un troisième exécute des règles de cohérence tandis qu'un quatrième distribue des alertes. Les ingénieurs perdent un temps précieux à croiser des notifications discordantes et à rechercher les périmètres de chacun.
Il est bien plus efficace de mettre en place un modèle d'exploitation centralisé :
Une interface commune pour suivre l'état de santé à chaque étape du pipeline
Un espace d'incidents partagé reliant la ponctualité, le schéma, la qualité et les anomalies
Une matrice claire des rôles pour la remontée d'alertes et la résolution
Un historique de modifications permettant d'identifier quoi a changé et quand
Si un ingénieur doit ouvrir quatre écrans de contrôle pour autopsier une seule mauvaise estimation d'un modèle, le système de supervision fait alors partie du problème.
Sur les architectures privées et sur site (on-premise), cette consolidation est indispensable car les équipes ne disposent pas toujours d'outils cloud-native managés de surveillance. Elles requièrent des solutions adaptées de contrôle qui respectent l'isolation réseau sans exiger de transferts de données sortants.
Considérations sur les pipelines sur site (On-Prem) et en Cloud privé
Les environnements sur site et de Cloud privé redéfinissent les critères de conception d'une infrastructure. Les bonnes pratiques du cloud public ne s'appliquent pas immédiatement si les flux d'informations ne peuvent pas franchir les frontières du réseau interne, si les processus d'achats s'avèrent longs et si les règles d'homologations de sécurité s'avèrent strictes.
Cela ne signifie pas qu'il soit plus difficile d'y concevoir de bons pipelines de data science. L'architecture doit simplement intégrer ces contraintes d'infrastructure dès sa conception.

Contraintes de sécurité et d'architecture
Dans les secteurs d'activité réglementés, les équipes préfèrent généralement exécuter les opérations de calcul là où résident déjà les données. Cela limite les failles de sécurité, supprime les duplications de données superflues et simplifie les validations de conformité administrative. En pratique, cela se traduit par des transformations au cœur des bases de données, le calcul local d'indicateurs, des validations directement au sein du warehouse et des ponts contrôlés pour l'entraînement ou l'inférence des modèles.
Les questions d'architecture essentielles sont simples :
Ce composant peut-il s'exécuter sans exporter de données sensibles hors du réseau ?
La sécurité interne peut-elle tracer l'historique complet des accès et des actions ?
Les administrateurs systèmes peuvent-ils déployer les mises à jour et le gérer avec leurs procédures habituelles ?
Le pipeline se met-il en sécurité de manière maîtrisée en cas de défaillance d'une ressource tierce ?
Les formats standardisés, les définitions d'interfaces explicites et la limitation stricte des transferts de données prouvent ici toute leur utilité.
Planification de la capacité et coût total
Sur site, les équipes ne résolvent pas un problème de charge réseau en ajoutant simplement des serveurs d'un clic. La planification des architectures s'impose en amont du projet et doit s'appuyer sur des profils d'utilisation réalistes. Les guides de Google sur la mesure de performance (benchmarking) de flux Dataflow par puissance vCPU s'avèrent de précieux outils méthodologiques dans ce cas : ils recommandent de valider les performances avec des structures de données, des volumes réels et des conditions de réseaux concrètes, plutôt que de se fier à des benchmarks génériques hors contexte.
Le calcul des coûts matériels doit aussi prendre en compte les processus de reprise sur panne. Comme l'indique Databricks dans son guide d'évaluation du ratio coût-performance des pipelines, le coût global des ressources de calcul ainsi que les taux d'échecs constatés s'inscrivent conjointement dans le calcul total du retour sur investissement, car les reprises successives imposent de recalculer d'importants volumes de données et retardent la mise à disposition des indicateurs.
Ce qui tient la route dans les environnements d'entreprise
Les architectures les plus robustes constatées au sein des organisations d'envergure s'avèrent souvent être les plus conventionnelles. Elles privilégient ainsi la stabilité aux innovations technologiques de dernière minute.
Une approche par composants modulaires : séparez les couches d'ingestion, de transformation, de validation et de mise à disposition afin qu'une défaillance ciblée ne paralyse pas l'ensemble des flux.
Des reprises de données déterministes (backfills) : soyez en mesure de traiter à nouveau une plage temporelle de données définie à l'aide d'un code identique et d'un historique de provenance clair.
Une observabilité locale : stockez vos indicateurs de bon fonctionnement à des emplacements accessibles aux équipes d'exploitation tout en respectant l'isolation de votre réseau.
Une affectation claire des responsabilités : chaque pipeline de données, table de restitution ou feature de modèle doit être associé à une équipe désignée responsable de la résolution des incidents.
La fiabilité des infrastructures d'envergure repose avant tout sur une délimitation stricte des responsabilités plutôt que sur la complexité des documentations d'architectures.
Les architectures Cloud privé et sur site récompensent les structures auditables, validées par des tests de performance rigoureux, et ménageant les flux réseaux superflus. C'est d'autant plus vrai lorsque les flux d'IA partagent des ressources de tables ou de stockage avec une multitude d'autres applications de l'entreprise.
Conclusion : Bâtir votre stratégie de pipeline résiliente
Un pipeline de data science performant va bien au-delà de la simple automatisation de tâches planifiées. Il constitue le système d'exploitation qui transforme la donnée brute en jeux de données d'entraînement fiables, en features opérationnelles, en exploitations de modèles et en indicateurs d'aide à la décision.
La phase initiale de déploiement concentre souvent toutes les attentions. C'est pourtant lors de la phase de maintenance ultérieure que l'on détermine si l'infrastructure continue à apporter la valeur attendue. C'est à ce stade que beaucoup d'organisations échouent. Elles automatisent le transport sans valider la conformité. Elles managent l'exécution de tâches techniques sans auditer la qualité des flux. Elles empilent les solutions logicielles sans pour autant clarifier l'information finale.
La conception d'une bonne stratégie est plus facile à théoriser qu'à mettre en œuvre sur le terrain. Découpez vos flux en étapes logiques étanches. Dimensionnez vos architectures de stockage et d'évaluation selon vos charges réelles constatées. Traitez d'un même bloc la qualité, la ponctualité, la conformité de schéma et le dépistage de comportements anormaux. Dans les architectures hébergées en interne, exécutez vos calculs au plus près de vos données et validez vos flux de travail avec des volumes d'activités concrets.
L'étape suivante la plus pertinente ne consiste pas à initier la refonte complète de votre outil de gestion de données. Elle se résume à auditer le pipeline le plus stratégique de l'entreprise. Repérez à quel emplacement il peut faillir de manière invisible. Évaluez le délai nécessaire à vos ingénieurs pour corriger un mauvais résultat d'analyse. Déterminez si les outils de contrôle et de qualité des données s'avèrent toujours trop éparpillés entre vos différentes équipes.
Si vous recherchez une solution simple pour unifier la détection d'anomalies, la validation d'enregistrements, le contrôle des délais et l'analyse de dérive des schémas de données sans transférer d'informations en dehors de votre réseau privé, découvrez digna. La solution a été conçue pour les organisations désireuses de déployer une démarche de qualité de données moderne et de supervision directement au cœur de leurs bases de données, de leur Cloud privé ou de leurs serveurs sur site.



