Data Lake vs Data Mart : faites le bon choix pour 2026
|
7
minute de lecture

Votre équipe de direction souhaite des tableaux de bord plus rapides, des KPI plus clairs et de l'espace pour l'IA et le machine learning. Dans le même temps, votre équipe de données doit composer avec des logs bruts, des extraits SaaS, des bases de données opérationnelles et des dépôts de fichiers qui n'arrivent pas à l'heure. C'est là que le choix entre le data lake et le data mart est généralement présenté de manière trop simpliste.
En pratique, il ne s'agit pas seulement d'un choix de stockage. C'est un choix de confiance. Un data lake vous offre de la flexibilité et de l'évolutivité. Un data mart apporte de la cohérence et de la rapidité aux équipes métiers. La partie difficile réside dans ce qui se passe entre les deux. Si vous ne contrôlez pas la qualité, le lignage et la détection des changements, le lac devient un handicap et le mart se transforme en une couche polie de mauvaises suppositions.
Pour la plupart des organisations qui planifient une plateforme de données de nouvelle génération, la question clé n'est pas de savoir lequel est universellement meilleur. Il s'agit plutôt de déterminer quel rôle chacun doit jouer et comment vous assurerez la fiabilité du parcours reliant les données brutes aux données prêtes pour le métier.
Table des matières
Qu'est-ce qu'un Data Lake et qu'est-ce qu'un Data Mart ?
Un data lake est un référentiel central destiné au stockage de données brutes sous de multiples formes. Il peut héberger des tables structurées, des données d'événements semi-structurées, des logs d'application, des documents et d'autres données sources avant même qu'une équipe ait pleinement décidé de la manière dont ces données seront modélisées ou interrogées. Le principe moteur est la flexibilité. Vous stockez d'abord les données, puis vous les façonnez plus tard lorsqu'un cas d'usage analytique ou métier se précise.
Un data mart est différent. Il s'agit d'une couche de données structurée et conçue spécifiquement pour un domaine d'activité particulier, comme la finance, les ventes, les opérations ou le support client. Les données y sont nettoyées, standardisées, testées et organisées avant d'être consommées par les utilisateurs métiers. Le principe directeur est la facilité d'utilisation. Les utilisateurs ne devraient pas avoir à reconstruire des systèmes sources bruts compliqués juste pour répondre à une question de reporting.

Le modèle mental le plus simple
Pensez au data lake comme à un réservoir. Il stocke de grands volumes de données entrantes dans leur état d'origine. Cela le rend précieux lorsque l'entreprise souhaite préserver les détails, soutenir les travaux de science des données ou garder toutes les options ouvertes pour des analyses futures.
Pensez au data mart comme à une usine d'embouteillage. Il prélève de l'eau sélectionnée dans le réservoir, la filtre, en vérifie la qualité, la conditionne et la distribue pour un usage bien précis. Cela le rend indispensable lorsque la finance a besoin d'une définition contrôlée du chiffre d'affaires ou lorsque les opérations requièrent un tableau de bord fiable pour suivre un niveau de service.
Règle pratique : Si les utilisateurs ont besoin de liberté pour explorer des questions inconnues, commencez plutôt avec un lac. S'ils ont besoin de réponses répétables pour un processus défini, commencez plutôt avec un mart.
Pourquoi la distinction importe pour la direction
Les dirigeants s’entendent souvent dire que les data lakes représentent la modernité et les data marts l'ancien temps, ou encore que les marts sont rigides et les lacs économiques. Aucun de ces cadres n'est utile. Ce qui compte, c'est la mission opérationnelle que chacun remplit.
Un lac favorise la largeur d'analyse. C'est l'espace où les équipes d'ingénierie préservent la fidélité des sources, intègrent rapidement de nouvelles données et réalisent des analyses exploratoires. Un mart favorise la précision. C'est là que les équipes de governance définissent les règles métier, alignent les indicateurs clés et réduisent les frictions décisionnelles.
Si vous évaluez également des services relationnels managés dans le cadre d'une architecture globale, ce guide RDS pour les entreprises philippines est une référence utile pour comprendre la place des bases de données opérationnelles aux côtés des couches décisionnelles. Les systèmes transactionnels, le stockage analytique brut et les modèles analytiques structurés résolvent chacun des problématiques distinctes.
Où les équipes rencontrent des difficultés
L'erreur la plus fréquente dans les discussions sur l'arbitrage entre data lake et data mart consiste à supposer que le lac n'est qu'une zone de transit et le mart un simple outil de reporting. C'est oublier la charge opérationnelle intermédiaire. La flexibilité brute génère un travail de nettoyage en aval. L'accessibilité structurée exige une discipline de modélisation en amont.
Les équipes qui recherchent une voie intermédiaire se tournent souvent vers l’approche lakehouse et les moyens de maintenir la qualité des données, en particulier lorsqu'elles souhaitent réduire les doublons entre l'espace de stockage brut et les couches de mise à disposition des analyses. Même dans ce cas, la même vérité architecturale s'applique : les données brutes et les données métiers de confiance ne doivent pas être traitées comme si elles obéissaient aux mêmes exigences de qualité.
Plongée architecturale : Une comparaison côte à côte
La façon la plus claire de comparer le data lake et le data mart est d'observer leur comportement respectif sous l'effet de contraintes opérationnelles réelles.
Caractéristique | Data Lake | Data Mart |
|---|---|---|
Structure des données | Brutes, formats mixtes, souvent transformées de manière minimale | Structurées, nettoyées, prêtes pour le métier |
Type de schéma | Schéma à la lecture (Schema-on-read) | Schéma à l'écriture (Schema-on-write) |
Objectif principal | Préserver les détails et permettre une exploration flexible | Fournir des analyses cohérentes pour une fonction métier définie |
Utilisateurs types | Ingénieurs de données, data scientists, équipes de ML | Analystes, équipes financières, utilisateurs de BI, parties prenantes métiers |
Type de traitement | Souvent orienté ELT | Souvent orienté ETL avant consommation |
Modèle de requête | Exploratoire, axé sur les batchs, charges de travail variées | Répétitif, accès à des rapports et tableaux de bord de grande valeur |
Postured de gouvernance | Souvent plus souple à l'ingestion, renforcée plus tard si la maturité le permet | Plus stricte dès le départ car les livrables sont destinés aux décisions stratégiques |
Tolérance au changement | Tolérance plus élevée vis-à-vis des variations des sources | Tolérance plus faible car les rapports doivent demeurer stables |
Attentes de performance | Idéal pour le stockage à grande échelle et l'expérimentation | Mieux adapté à une consommation analytique rapide et ciblée |
Profil de coût | Efficace en termes de stockage, mais la complexité opérationnelle peut croître | Effort de transformation et de modélisation plus important, mais valeur métier plus claire au moment de la consommation |
Flexibilité versus contrôle
Un lac s'impose lorsque l'organisation ne connaît pas encore toutes les questions futures qu'elle voudra se poser. La télémétrie des produits, les clics d'utilisation (clickstream), les logs, les documents et les extractions de sources peuvent tous être hébergés sans exiger de choix de modélisation immédiats. C'est particulièrement utile si votre feuille de route intègre de l'expérimentation, de la création de variables (feature engineering) ou la conservation exhaustive de l'historique des sources.
Un mart s'impose lorsque l'organisation connaît déjà la question. La clôture mensuelle, le suivi des marges, les revues d'opportunités de vente, l'analyse des sinistres et les rapports de Compliance réglementaires dépendent tous de définitions stables. Les utilisateurs attendent un chiffre fiable, et non un point de départ sujet à interprétation.
Le lac stocke le potentiel. Le mart concrétisera l'engagement.
Le compromis architectural caché
Beaucoup d'équipes de direction comparent uniquement le format de stockage et le profil d'utilisateur. Le compromis fondamental réside pourtant dans le modèle opérationnel.
Un lac délègue l'effort en aval. Les ingénieurs peuvent ingérer rapidement, mais il faudra tout de même que quelqu'un réconcilie les identifiants, traite les valeurs manquantes, standardise les dates, définisse les règles de gestion et résolve les conflits de sources. Si cette rigueur fait défaut, le lac accumulera des données sans jamais produire d'indicateurs de confiance.
Un mart déplace l’effort en amont. Les équipes doivent s'accorder sur les définitions avant que les données ne soient largement diffusées. Cela peut donner une impression de lenteur initiale, mais évite des confusions récurrentes. Le coût n’est pas uniquement technique : il s'agit d'alignement organisationnel.
Ce qui fonctionne et ce qui ne fonctionne pas
Certains schémas d'architecture font constamment leurs preuves :
Utiliser le lac pour la réception et la préservation : Conservez la fidélité de la source là où les détails bruts importent.
Utiliser le mart pour les données de confiance décisionnelle : Placez les KPI gouvernés et les dimensions structurées là où opèrent les équipes métiers.
Séparer la vitesse d'ingestion de la sécurité de consommation : L'intégration rapide d'un côté et les rapports fiables de l'autre ne doivent pas être contraints dans la même couche.
D'autres approches se soldent généralement par des échecs :
Laisser chaque équipe requêter directement le lac de données : Cela engendre généralement des variables incohérentes et une logique métier dupliquée.
Construire des marts isolés à partir de systèmes opérationnels directs : Facile au début, cela devient très coûteux à maintenir par la suite.
Traiter les données brutes comme prêtes pour le métier simplement parce qu'elles sont disponibles : Disponibilité ne rime pas avec qualité.
La vision de la direction
Si vous financez une plateforme, ne vous demandez pas seulement où les données vont résider. Demandez-vous où seront logées les définitions des métriques, qui est responsable de la conformité des sources, et comment les anomalies seront détectées avant que les dirigeants n'en prennent connaissance. C'est à ce moment précis que la décision entre lac et mart devient une véritable stratégie de plateforme, plutôt qu'un énième débat technique sur les outils.
Associer l'architecture au cas d'usage
La bonne architecture s’impose d'elle-même lorsque l’on analyse les besoins opérationnels concrets.
Quand un data lake est la solution idéale
Une équipe produit et d'apprentissage automatique a généralement besoin de détails comportementaux bruts. Elle recherche des logs de session, des charges utiles d'événements, des interactions de support, des signaux d'appareils et des entrées d'entraînement de modèles sans filtrage excessif à l'ingestion. Elle peut réanalyser des données anciennes à l'aide d'une nouvelle hypothèse, ou combiner des sources qui n'avaient pas été pensées à l'origine pour répondre à la même problématique.
C’est un cas d’usage par excellence pour un data lake. L'équipe a besoin d'espaces pour explorer, croiser, enrichir et recalculer. Imposer d'intégrer trop tôt l'ensemble de ces flux dans un mart figé supprimerait des détails essentiels et multiplierait les travaux de remodélisation systématiques.
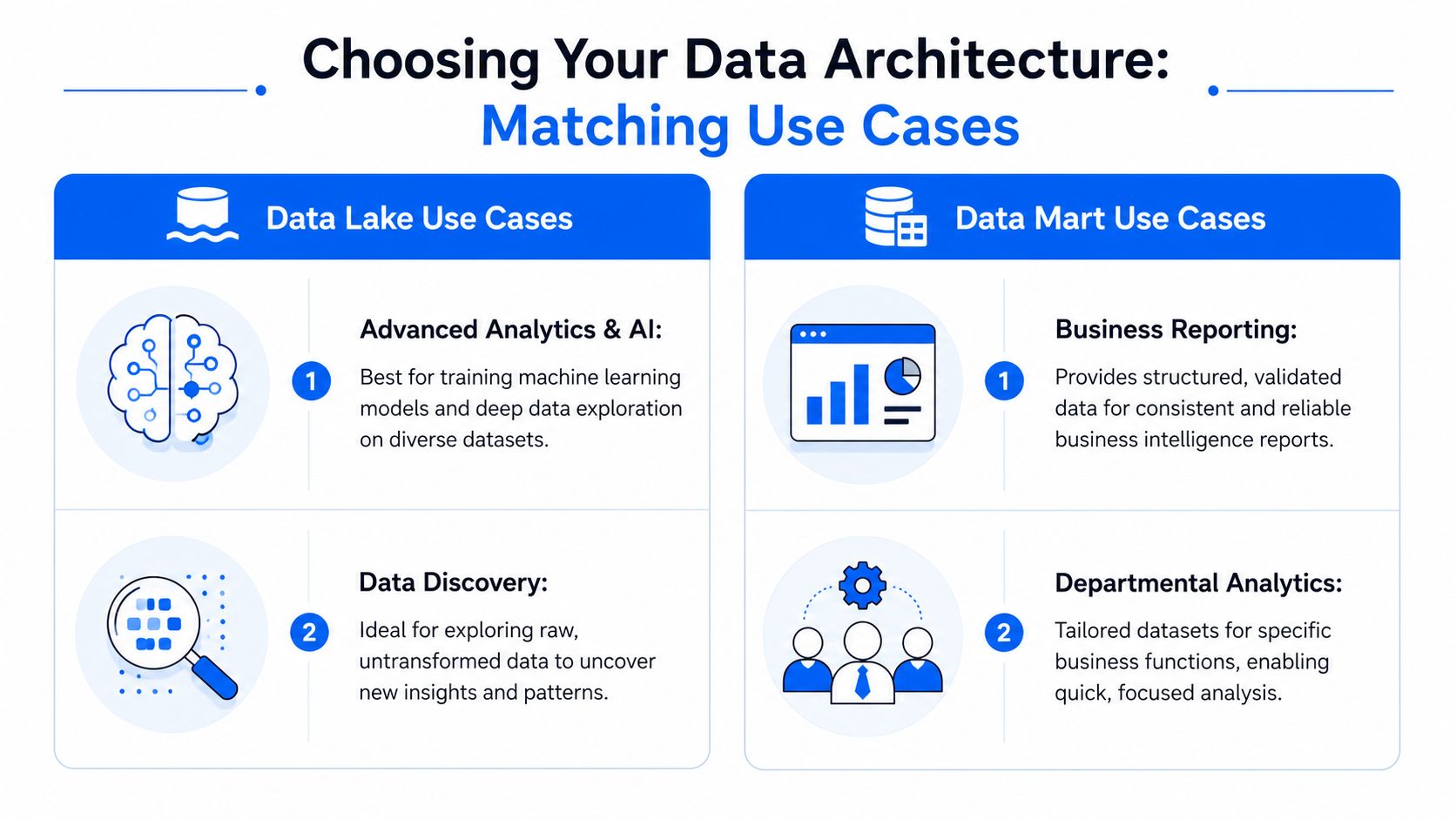
Quand un data mart est la meilleure réponse
Une équipe financière a un besoin diamétralement opposé. Elle ne souhaite pas voir défiler chaque état de transaction brute, chaque événement intermédiaire, ou faire face à de multiples interprétations possibles du chiffre d'affaires. Elle exige un ensemble unique et gouverné de définitions pour les réservations, les revenus comptabilisés, la répartition des coûts et les rapports de clôture de période.
C'est le cas d’usage type pour un data mart. Le mart restreint délibérément le périmètre. Il lève toute ambiguïté pour éviter que le reporting trimestriel ne se transforme en un débat sémantique autour des systèmes sources.
Deux exemples pratiques
Considérez ces deux modèles classiques :
Flux de travail de data science : Les ingénieurs déversent les événements d'application, les retours d'API et les instantanés historiques dans un lac. Les data scientists conçoivent des variables (features) à partir de séquences brutes et adaptent les transformations en fonction des exigences changeantes des modèles.
Flux de travail de BI par département : Les ingénieurs analytiques publient un mart financier doté de dimensions harmonisées, d'indicateurs approuvés et de jointures testées afin que les contrôleurs et la direction exploitent précisément les mêmes données.
Aucun de ces modèles n’est plus moderne que l’autre. Ils répondent simplement à des problématiques métiers différentes.
Si l'objectif est la découverte, optimisez l'accès au contexte brut. Si l'objectif est la responsabilité et la précision, optimisez la cohérence.
Ce que la direction devrait standardiser
Les plateformes les plus robustes n'imposent pas une architecture unique à tout le monde. Elles standardisent les critères de décision :
Le type d'utilisateur final : Ce jeu de données s’adresse-t-il à des ingénieurs et des scientifiques, ou à des utilisateurs métiers ?
La tolérance à l'ambiguïté : Les utilisateurs peuvent-ils interpréter des signaux bruts, ou ont-ils besoin de définitions validées ?
La fréquence des changements : La logique de transformation va-t-elle évoluer souvent, ou doit-elle rester stable pour garantir une bonne gouvernance ?
Les conséquences d'une erreur : S'agit-il d'une analyse exploratoire sans gravité ou d’un indicateur utilisé pour un budget, pour la Compliance ou d'autres publications externes ?
Ces questions résolvent généralement le débat opposant le data lake au data mart bien plus rapidement que ne le ferait une interminable comparaison d'outils techniques.
Le chemin critique du lac au mart : Gouvernance et qualité
L'hypothèse risquée au sein de nombreuses architectures consiste à croire que le transfert de données d'un lac vers un mart relève d'une banale routine de pipeline. Ce n’est pas le cas. C’est l'étape cruciale où une information brute, incohérente et calquée sur le système source se métamorphose en une vérité métier. Cette conversion introduit des étapes de validation, de normalisation, de rapprochement, de déduplication, d'enrichissement et des arbitrages de politiques que beaucoup d'équipes ont tendance à sous-estimer.

Pourquoi le passage de relais échoue
Les données brutes se présentent rarement dans un état adapté à un usage direct pour un mart. Les systèmes sources codent les statuts différemment. Les clés ne s'alignent pas proprement. Des champs optionnels deviennent obligatoires en aval. Les horodatages dérivent. Des fichiers arrivent en retard. Une modification de schéma dans une source peut invalider discrètement la logique de transformation plusieurs étapes plus loin.
C'est pourquoi la gouvernance ne peut pas être intégrée à la hâte après le déploiement. Les règles de validation, la propriété des données, le lignage et les processus d'acceptation doivent être intégrés au flux dès le commencement.
Un guide pratique des contrats de données et de leur mise en œuvre est particulièrement utile ici, car les contrats imposent aux équipes de définir ce que les systèmes en amont doivent livrer avant que les marts en aval n'en dépendent.
La défaillance de qualité qui devrait préoccuper la direction
Une étude menée en 2024 dans le domaine de la santé a révélé que jusqu'à 40 % des exports de data lakes échouent à la validation des règles de gestion avant d'atteindre les data marts lorsque des contrôles de qualité automatisés sont absents, ce qui entraîne des ruptures de pipelines et des rapports obsolètes, comme décrit dans cette étude sur la qualité des données de santé. C'est la réalité opérationnelle que de nombreux diagrammes d'architecture omettent.
L'impact sur l'entreprise est immédiat. Si votre mart est la couche de référence pour votre direction, la transition reliant le lac au mart n'est pas qu'un simple raccord d'ingénierie. C'est un point de contrôle capital.
Conseil opérationnel : N'approuvez pas un nouveau mart sans avoir préalablement validé la responsabilité des contrôles, la gestion des exceptions et les règles de rollback.
Ce que les équipes performantes mettent en place
Les équipes qui gèrent efficacement cette transition formalisent généralement plusieurs jalons de contrôle :
Critères d'entrée pour les données sources : Définissez les éléments obligatoires avant qu'un ensemble de données ne puisse progresser.
Points de contrôle des transformations : Testez les jointures, la gestion des valeurs nulles, le mapping des codes et la conformité aux directives métiers lors du traitement.
Discipline de gestion des versions : Versionnez les logiques de transformation et documentez les modifications apportées aux définitions des métriques avant de les publier.
Circuits de remontée d'alertes : Assurez-vous que les contrôles en échec déclenchent des actions concrètes, et pas seulement de simples logs.
Une brève explication sur l'importance de l'état d'esprit pipeline s'avère pertinente avant d'aborder les outils :
Le coût caché est généralement opérationnel, pas lié au stockage
Les décideurs prévoient souvent un budget pour le stockage tout en sous-estimant les coûts induits par la correction des anomalies. La partie la plus onéreuse ne réside pas dans la conservation des données brutes au sein d'un lac. Ce sont les efforts répétés exigés lorsque des données de piètre qualité se propagent en aval, forçant les équipes à corriger dans l'urgence des rapports erronés, à relancer des scripts lourds et à expliquer des écarts de chiffres devant la direction.
C'est pourquoi la conception de la gouvernance doit être une priorité de premier ordre lors d’un choix entre data lake et data mart. Si la passerelle reliant l'un à l'autre est défaillante, la plateforme paraîtra complète sur le papier, mais se révélera inutilisable en pratique.
Assurer la confiance grâce à la Data Observability
La plupart des incidents de données ne prennent pas naissance là où les utilisateurs finaux les constatent. Ils se manifestent dans le mart parce que c'est là que se portent les regards, mais la source de l'erreur remonte bien souvent en amont, dans le lac ou dans les flux d'ingestion qui l'alimentent.
Pourquoi surveiller le mart seul ne suffit pas
Un tableau de bord peut cesser d'être exact car un fichier source est arrivé en retard, un type de colonne a été modifié, un chargement s'est fait de façon incomplète, ou parce qu'un profil de distribution autrefois stable a suffisamment dérivé pour fausser une hypothèse en aval. Si votre surveillance se limite à la table finale ou à la requête du dashboard, vous ne détecterez le problème qu'une fois que l'entreprise y aura déjà été exposée.
Des études récentes datant de 2024 indiquent que 65 % des incidents liés à la qualité des données dans les data marts découlent de problèmes non surveillés dans les data lakes en amont, incluant des modifications de schéma invisibles et des retards de chargement, selon cette recherche sur les causes amont des incidents de qualité des données en aval.

Ce que l'observabilité doit surveiller
Au sein d'une infrastructure moderne, l'Observability doit englober au moins ces différents types de défaillances :
Les dérives de fraîcheur : Repérez les retards ou les absences d'arrivées avant que les fenêtres de reporting ne s'ouvrent.
La dérive de schéma : Identifiez les champs ajoutés, supprimés ou dont le type a changé avant que les traitements de transformation ne s'interrompent brutalement.
Les anomalies de données : Signalez les variations inattendues de volumes, de répartition ou de plages de valeurs susceptibles d'indiquer un dysfonctionnement de la source.
Les écarts de validation : Vérifiez en continu que les enregistrements respectent toujours les contraintes propres aux processus métiers en aval.
La Data Observability s'intègre au cœur de l'architecture, et pas uniquement au niveau opérationnel. Si votre lac est par nature flexible, votre surveillance doit quant à elle être structurée par conception.
Un modèle d'outillage pratique
Les équipes combinent généralement des alertes d'orchestration, des tests sur les transformations, du lignage de métadonnées et des solutions dédiées à l'observabilité. À titre d'illustration, l'article les différences expliquées entre data observability et data quality permet de bien comprendre que surveiller le comportement des pipelines et valider des règles métiers sont des activités complémentaires mais différentes.
Dans cette optique, digna se présente comme une option pertinente pour surveiller les anomalies, le respect des délais, les variations de schémas et la validation à la ligne à travers les lacs de données, les entrepôts et les pipelines, tout en exécutant l'analyse au sein même de l'environnement client. Cet aspect est primordial dans les secteurs réglementés nécessitant une visibilité opérationnelle étroite sans déplacement massif de données.
Un mart fiable repose sur un lac surveillé avec soin. La confiance en aval commence toujours en amont.
Ce qui change une fois l'observabilité en place
La transformation la plus marquante est d'ordre culturel. Les équipes de données cessent d'attendre que les utilisateurs métiers signalent les premiers bogues. Les ingénieurs identifient un retard de chargement bien avant que le directeur financier ne consulte un graphique obsolète. Les analystes comprennent immédiatement si une métrique a dévié en raison d'une évolution réelle du marché ou suite à une altération technique de la donnée. Les équipes de gouvernance disposent d'un historique de contrôle transparent pour valider la conformité d'un jeu de données publié.
C’est la dimension souvent absente des réflexions opposant les data lakes aux data marts. Les orientations d'architecture comptent, mais la confiance naît d’une surveillance active du chemin reliant l'un à l'autre.
Le cadre de décision : De quoi avez-vous besoin ?
Trancher la question « data lake ou data mart » par un simple choix arbitraire est une erreur. La bonne approche consiste à se poser une série de questions d'affaires et opérationnelles.
La liste de contrôle que les dirigeants d'entreprise devraient utiliser
Avez-vous besoin de conserver des données brutes et multi-formats pour des analyses futures ? Si oui, le recours à un élément de data lake s’avère indispensable.
Vos utilisateurs ont-ils besoin d'indicateurs de performance validés pour des décisions d'affaires régulières ? Si oui, l'utilisation d'un ou plusieurs data marts est requise.
Vos principaux utilisateurs sont-ils des data scientists et des ingénieurs ? Privilégiez alors des accès bruts et des traitements souples.
Vos principaux utilisateurs sont-ils des analystes, des contrôleurs ou des dirigeants d'entreprise ? Privilégiez les structures modélisées et la sémantique stable.
Votre équipe a-t-elle la capacité d'assurer des contrôles de qualité entre les différentes couches ? Si tel n'est pas le cas, évitez d'imaginer qu'un lac résoudra miraculeusement la complexité de votre plateforme.
La cohérence des indicateurs clés est-elle plus cruciale que l'exhaustivité de la source pour ce projet spécifique ? Si oui, diffusez vos indicateurs par l’entremise d’un mart et non directement depuis l’espace de stockage brut.

La réponse est souvent : les deux
Au sein des infrastructures matures, le choix s'articule généralement autour du mot et, et non du mot ou. Le lac constitue la couche d'atterrissage et de découverte élargie. Le mart fait office de couche de consommation ciblée, dédiée à des domaines d'activité définis. L’enjeu stratégique consiste à placer judicieusement les critères de qualité, à attribuer clairement la responsabilité des transformations et à détecter les anomalies avant qu’elles n’affectent l'aide à la décision.
S'il ne fallait retenir qu'un seul principe directeur, ce serait le suivant : stockez largement, publiez de manière ciblée et surveillez activement le parcours entre les deux. Cette démarche garantit à l'entreprise toute la souplesse nécessaire pour évoluer sans jamais dégrader la confiance envers les indicateurs servant au pilotage de l'activité.
Si votre équipe conçoit actuellement une infrastructure où des data lakes bruts alimentent des data marts critiques pour le pilotage, l'outil digna mérite d'être évalué pour intégrer votre couche opérationnelle. Il se concentre sur la qualité des données et l'observabilité à travers la détection d'anomalies, le suivi des modifications de schémas, le respect des délais et la validation à la ligne afin de permettre aux équipes d'agir le plus rapidement possible et de sécuriser la fiabilité des analyses diffusées.



