Pourquoi les tâches Databricks deviennent imprévisibles - Et comment les équipes détectent tôt l'instabilité
|
5
minute de lecture

Databricks les environnements sont construits pour l'élasticité. Les clusters s'ajustent, les charges de travail évoluent et les volumes de données augmentent continuellement. Cette flexibilité est puissante ; cependant, elle introduit également un défi auquel de nombreuses entreprises finissent par faire face :
Les tâches qui se comportaient jadis de manière prévisible commencent à fluctuer dans le temps d'exécution, l'utilisation des DBU et le coût.
Les pipelines réussissent toujours. Les tableaux de bord sont toujours mis à jour. Rien ne semble « cassé ». Pourtant, la prévisibilité opérationnelle s'érode.
Comprendre pourquoi cela se produit et comment le détecter rapidement est crucial pour les équipes exploitant Databricks en tant que plateforme de données et d'IA en production.
L'Instabilité dans Databricks Est une Question de Comportement, Pas d'Échec
Dans les systèmes traditionnels, l'instabilité signifiait souvent la surcharge du système ou les limites du matériel. L'instabilité de Databricks est différente.
Parce que les clusters s'ajustent automatiquement et les charges se répartissent dynamiquement, l'instabilité se manifeste par :
Augmentation de la consommation de DBU pour les mêmes tâches
Augmentation de la variance dans la durée d'exécution
Performance des tâches imprévisible
Événements de redimensionnement de cluster plus fréquents
Les tâches peuvent se terminer avec succès, mais leur comportement change au fil du temps. Ces changements sont souvent invisibles dans les tableaux de bord axés uniquement sur le succès/l'échec.
Qu'est-ce qui Rend les Tâches Databricks Imprévisibles ?
1. Croissance des Données qui Modifie les Plans d'Exécution
À mesure que les volumes de données augmentent :
Les shuffles augmentent
Les jointures deviennent plus lourdes
Les stratégies de partition se dégradent
L'efficacité du caching change
Même sans changements de code, les plans d'exécution Spark changent. Cela conduit à une utilisation plus élevée des DBU et des temps d'exécution plus longs.
Le travail « fonctionne » toujours, mais il consomme plus de ressources qu'avant.
2. Dérive Logique dans les Notebooks et les Pipelines
Les charges de travail Databricks évoluent rapidement.
Les équipes ajoutent :
Des jointures supplémentaires
Des agrégations additionnelles
De nouveaux calculs de caractéristiques ML
Des filtres plus larges
Chaque modification ajoute une surcharge. Individuellement, les changements semblent mineurs. Au fil des mois, ils modifient fondamentalement le comportement des charges de travail.
3. L'Auto-Échelle Masque les Problèmes de Ressources
L'auto-échelle est à la fois une force et un point aveugle.
Lorsque les charges de travail exigent plus de calcul :
Les clusters s'agrandissent automatiquement
Les tâches se terminent avec succès
Les coûts augmentent silencieusement
Au lieu de tomber en panne, le système absorbe les inefficacités, cachant les régressions de performance derrière une infrastructure élastique.
Le premier signal apparaît souvent comme une augmentation de la consommation de DBU, pas comme une erreur.
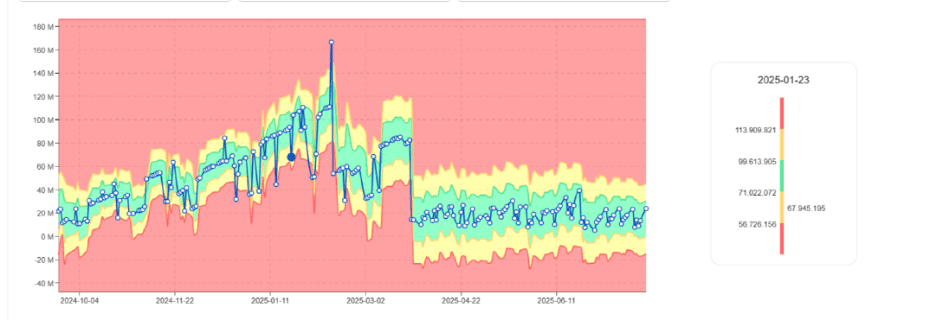
Tendance à l'augmentation de l'utilisation des DBU pour la même tâche
4. Déséquilibre dans les Décalages et les Shuffles
Le décalage des données cause certaines tâches à traiter des quantités disproportionnées de données.
Dans Databricks cela se manifeste par :
Des tâches de longue durée
Des traînards
Une variance accrue dans la durée des étapes
Parce que Spark distribue les tâches dynamiquement, le décalage produit des temps d'exécution instables et une consommation de DBU imprévisible.
5. Comportement de Rappel et Échecs Cachés
Les rappels de tâches sont courants dans les systèmes distribués.
Les problèmes transitoires, la pression mémoire ou la perte d'exécuteur peuvent déclencher des rappels qui :
Augmentent le temps d'exécution
Gonflent la consommation de DBU
Ajoutent de la volatilité
Les tâches réussissent, mais l'instabilité augmente.
6. Saisonnalité dans les Charges de Travail
Les tâches Databricks reflètent souvent les cycles d'affaires :
Traitement de fin de mois
Pics de rapports hebdomadaires
Calendriers de réentraînement des modèles
Sans modéliser ces modèles, les équipes ignorent soit les anomalies, soit sont submergées par de fausses alertes.
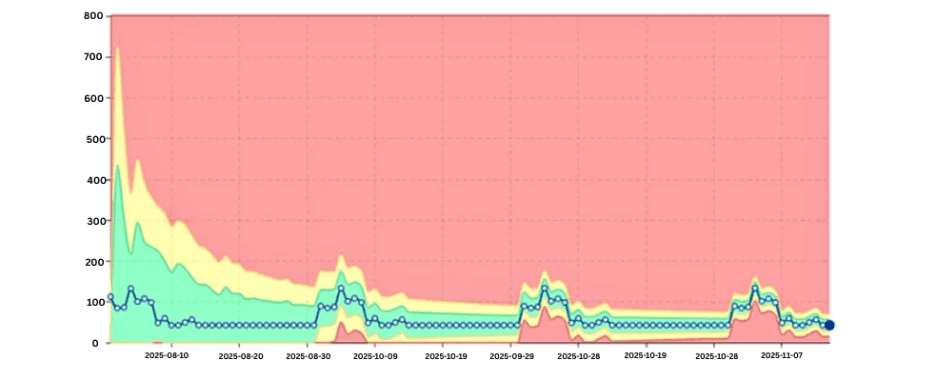
Modèle saisonnier des DBU avec des pics attendus
Pourquoi la Surveillance Traditionnelle Manque les Signaux Précoces
La plupart des équipes s'appuient sur :
Métriques de succès/échec des tâches
Tableaux de bord de coût
Vues d'utilisation des clusters
Ces outils montrent les résultats, pas les changements de comportement.
Ils ne révèlent pas :
Les tâches devenant plus coûteuses au fil du temps
Une variabilité croissante dans le temps d'exécution
Des changements structurels dans l'exécution des charges de travail
L’instabilité commence bien avant que les seuils soient franchis.
Le Passage à la Surveillance Comportementale
Détecter l'instabilité tôt nécessite d'analyser comment les charges de travail se comportent au fil du temps, pas seulement si elles réussissent.
Les signaux clés incluent :
Tendances de l'utilisation des DBU
Évolution du temps d'exécution
Variance dans la durée des tâches
Fréquence de mise à l'échelle des clusters
En transformant ces métriques en données de séries temporelles, les équipes peuvent identifier la dérive, la volatilité et le changement structurel.
Détecter l'Instabilité Tôt
Apprendre le Comportement Normal des Tâches
Au lieu de seuils fixes de DBU, les approches modernes apprennent :
Plage typique de DBU par tâche
Modèles de temps d'exécution attendus
Comportement normal des clusters
À mesure que les charges de travail se stabilisent, les plages de comportement acceptables se rétrécissent.
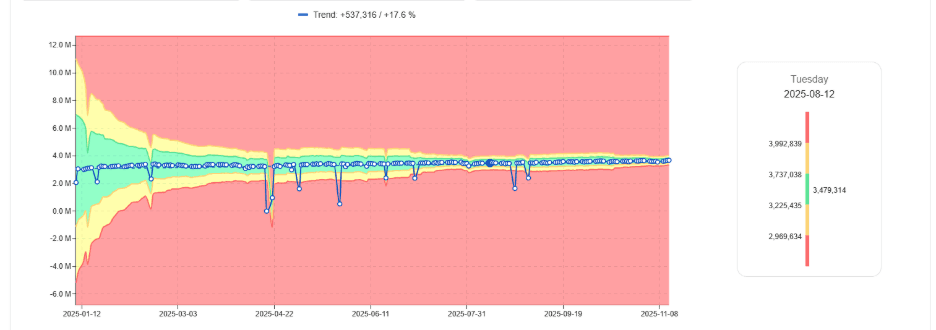
Bande normale de DBU apprise se rétrécissant avec le temps
Repérer la Dérive Progressive de DBU
L'un des plus grands moteurs de coûts est la croissance lente des DBU.
En comparant l'utilisation actuelle à des bases historiques, les équipes peuvent identifier quelles tâches consomment progressivement plus de ressources.
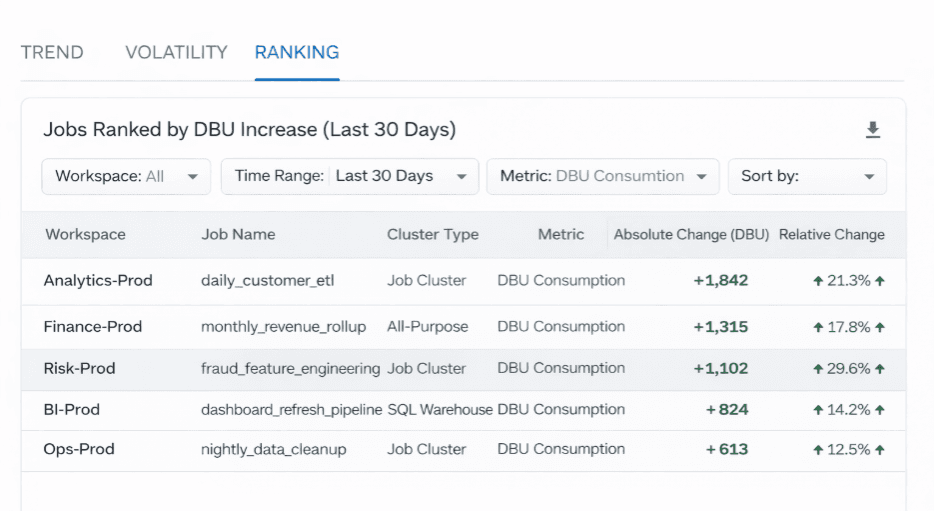
Tâches classées par augmentation mensuelle des DBU
Mesurer la Volatilité du Temps d'Exécution
Même si le temps d'exécution moyen reste constant, une forte variance signale une instabilité.
Les tâches volatiles sont plus difficiles à planifier et plus susceptibles de causer des retards en aval.
Tenir Compte de la Saisonnalité
Les systèmes comportementaux distinguent les pics cycliques prévus des véritables anomalies, réduisant le bruit des alertes.
Où digna Intervient
digna analyse les métriques de charges de travail Databricks telles que la consommation de DBU, le temps d'exécution et le comportement des volumes au fil du temps. Au lieu de limites statiques, il utilise l'IA pour apprendre des modèles normaux et détecter les écarts improbables tôt — qu'il s'agisse de pics soudains ou de dérives progressives.
Cela permet aux équipes de détecter les problèmes avant qu'ils n'apparaissent dans les rapports de coûts ou les violations de SLA.
Plus d'informations sur cette approche axée sur les anomalies peuvent être trouvées :
digna Data Anomalies | Regarder la Démonstration
Pourquoi la Détection Précoce est Importante
Lorsque l'instabilité est détectée tôt, les organisations peuvent :
Optimiser les requêtes avant que les coûts n'augmentent
Stabiliser les pipelines avant que les SLA ne soient impactés
Réduire les interventions en situation d'urgence
Améliorer la prévisibilité pour les équipes FinOps
Dernière Pensée
Les tâches Databricks échouent rarement clairement. Elles deviennent imprévisibles.
Cette imprévisibilité est visible dans le changement de comportement des DBU, la variabilité des temps d'exécution et les modèles d'exécution en évolution, des signaux que la surveillance statique ne peut pas capturer.
Les équipes qui adoptent une surveillance comportementale gagnent une visibilité précoce sur l'instabilité, maintenant ainsi le contrôle au fur et à mesure que leurs environnements Databricks s'étendent.



